
Hadoop YARN资源管理-公平调度器(Fackbook的Fair Scheduler)
Hadoop YARN资源管理-公平调度器(Fackbook的Fair Scheduler)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
之前我分享了配置容量调度器(Apache Hadoop默认的调度器)的笔记,今天我们来学习另一个重要的Hadoop资源调度器,即公平调度器,当然,它也是CDH默认的调度器。
一.公平调度器概述
1>.YARN资源调度器概述
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13341939.html
2>.队列
队列使得调度器能够分配资源。所有集群用户都被分配一个名为"default"的队列。可以在层次结构中排列队列,还可以使用权重配置队列,以便微调集群中的资源分配。 为了确保特定用户或应用程序始终获得所需的资源,公平调度器允许将保证的最小份额分配给队列。 应用程序或用户始终得到最小共享保证,但调度器可确保队列中不会有闲置未使用的资源。当分配有保证资源的任何队列由于队列未运行应用程序而具有剩余资源时,集群会将剩余资源分配给其它应用程序。
应用程序被提交到一个特定的队列,在默认情况下每个用户都有自己的队列。还可以创建自定义队列,以确保最小资源,并为每个队列设置权重以指定优先级。
公平调度器依赖于以分层方式构建的资源队列或池。所有队列都从名为根队列的同一个祖先继承。后代队列称为叶子队列,应用程序将在叶子队列上调度。叶子队列可以拥有更多级别的子队列。
可以在fair-scheduler.xml文件中定义队列,并将其命名为以父队列开头的名称(例如:"root.default"),请注意,引用队列时,可以不指定队列名称的根部分。Hadoop以公平的方式将集群资源分配到根队列的子队列中。
温馨提示:
Hadoop会每10秒自动加载fair-scheduler.xml文件,所以对Fair Scheduler配置所做的任何更改几乎都会成功生效。没有必要像在修改容量调度器的配置时那样手动运行"yarn rmadmin -refreshQueues"命令哟~
二.配置公平调度器
1>.启用公平调度器策略并指定"fair-cheduler.xml"文件路径
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml ... <!-- 配置公平调度器 --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>指定resourcemanager的调度器(如上所示,默认为容量调度器),我这里指定的是公平调度器</description> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/yinzhengjie/softwares/hadoop/etc/hadoop/conf/fair-scheduler.xml</value> <description>指定公平调度器的配置文件所在路径,hadoop会每间隔10秒自动加载该文件,而无需向容量调度器那样手动运行"yarn rmadmin -refreshQueues"命令。</description> </property> ... [root@hadoop101.yinzhengjie.com ~]#
温馨提示:
(1)通过编辑分配文件(就是我上面指定的"fair-scheduler.xml"文件路径),可以在运行时修改最小份额,限制,权重,抢占超时和队列调度策略。计划程序会在看到文件已被修改后10-15秒重新加载该文件。
(2)编辑"fair-scheduler.xml"文件时,若对已经存在的队列进行更名时,新更名的队列会在10-15秒内自动创建出来,但原来存在的队列名称依旧存在,知道你重启YARN集群时它才会自动消失哟;
2>.fair-scheduler.xml文件格式说明
分配文件(${HADOOP_HOME}/etc/hadoop/conf/fair-scheduler.xml)必须为XML格式。该格式包含五种类型的元素:
Queue elements:
代表队列。队列元素可以采用可选属性'type',将其设置为'parent'使其成为父队列。当我们要创建父队列而不配置任何叶队列时,这很有用。每个队列元素可能包含以下属性:
minResources:
队列有权使用的最少资源。对于单资源公平性策略,仅使用内存,而忽略其他资源。如果不满足队列的最小份额,将在同一父项下的任何其他队列之前为它提供可用资源。
在单资源公平性策略下,如果队列的内存使用率低于其最小内存份额,则认为该队列不满意。在支配资源公平的情况下,如果队列在集群资源中相对于集群容量的使用率低于该资源的最小份额,则认为该队列不满足要求。
如果在这种情况下无法满足多个队列,则资源以相关资源使用率与其最小值之间的最小比率进入队列。
maxResources:
可以分配队列的最大资源。不会为队列分配一个容器,该容器的总使用量将超过此限制。此限制是递归实施的,如果该分配会使队列或其父级超过最大资源,则不会为该队列分配容器。
maxContainerAllocation:
队列可以为单个容器分配的最大资源。如果未设置该属性,则其值将从父队列继承。默认值为yarn.scheduler.maximum-allocation-mb和yarn.scheduler.maximum-allocation-vcores。不能高于maxResources。该属性对于根队列无效。
maxChildResources:
可以分配临时子队列的最大资源。子队列限制是递归实施的,因此,如果该分配会使子队列或其父队列超出最大资源,则不会分配容器。
对于minResources,maxResources,maxContainerAllocation和maxChildResources属性,可以使用以下一种格式给出参数:
旧格式:"X mb,Y vcores","X% cpu,Y% memory","X%"。如果未提供单个百分比,则必须同时配置内存和cpu,而忽略其他资源类型并将其设置为零。
新格式(推荐):"vcores = X,memory-mb = Y"或"vcores = X%,memory-mb = Y%"。可以看出,以这种格式,可以给出百分比或整数的无单位资源值。
在后一种情况下,将根据为该资源配置的默认单位来推断单位。当指定了内存和CPU以外的资源时,需要这种格式。
如果使用minResources,则任何未指定的资源都将设置为0;如果使用maxResources,maxContainerAllocation和maxChildResources,则该资源的最大值将设置为0。
maxRunningApps:
限制队列中一次运行的应用程序数量。
maxAMShare:
限制可用于运行应用程序主服务器的队列公平份额的比例。此属性只能用于叶队列。例如,如果设置为1.0f,则叶队列中的AM最多可以占用100%的内存和CPU公平份额。-1.0f的值将禁用此功能,并且不会检查amShare。默认值为0.5f。
weight:
与其他队列不成比例地共享集群。权重默认为1,权重为2的队列所接收的资源大约是权重为默认队列的两倍。
schedulingPolicy:
可以根据用户名和组以及应用程序请求的队列配置将提交的应用程序放入适当队列的策略。调度策略使用规则来顺序地评估,并将新的的应用程序置于队列中。在fair-scheduler.xml文件中,可以设置以下几种调度策略:
fifo:
优先考虑具有较早提交时间的应用程序的容器,但是如果满足较早应用程序的请求后群集上仍有剩余空间,则较晚提交的应用程序可以同时运行。
fair:
公平调度策略是默认值。
drf:
主导资源公平策略。
虽然可以指定上述列出的三个值之一,但实际上可以使用任何扩展了"org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy"的类。
aclSubmitApps:
可以将应用程序提交到队列的用户和/或组的列表。有关此列表的格式以及队列ACL如何工作的更多信息,请参考官网的ACL部分。
aclAdministerApps:
可以管理队列的用户和/或组的列表。当前,唯一的管理操作是杀死应用程序。有关此列表的格式以及队列ACL如何工作的更多信息,请参考官网的ACL部分。
minSharePreemptionTimeout:
队列在尝试抢占容器以从其他队列中获取资源之前,处于其最小份额之下的秒数。如果未设置,则队列将从其父队列继承值。默认值为Long.MAX_VALUE,这意味着它在设置有意义的值之前不会抢占容器。
fairSharePreemptionTimeout:
队列在尝试抢占容器以从其他队列中获取资源之前,处于其公平份额阈值以下的秒数。如果未设置,则队列将从其父队列继承值。默认值为Long.MAX_VALUE,这意味着它在设置有意义的值之前不会抢占容器。
fairSharePreemptionThreshold:
队列的公平份额抢占阈值。如果队列在等待fairSharePreemptionTimeout而没有收到fairSharePreemptionThreshold * fairShare资源,则可以抢占容器以从其他队列中获取资源。如果未设置,则队列将从其父队列继承值。默认值为0.5f。
allowPreemptionFrom:
确定是否允许调度程序从队列中抢占资源。默认值为true。如果队列的此属性设置为false,则此属性将递归应用于所有子队列。
reservation:
表示该ReservationSystem队列的资源可供用户储备。这仅适用于叶子队列。如果未配置此属性,则无法保留叶队列。
User elements:
代表控制各个用户行为的设置。它们可以包含一个属性:maxRunningApps,一个特定用户正在运行的应用程序数量的限制。
A userMaxAppsDefault element:
它为未另外指定限制的任何用户设置默认的运行应用程序限制。
A defaultFairSharePreemptionTimeout element:
设置根队列的公平抢占超时。被根队列中的fairSharePreemptionTimeout元素覆盖。默认设置为Long.MAX_VALUE。
A defaultMinSharePreemptionTimeout element:
设置根队列的最小共享抢占超时;由根队列中的minSharePreemptionTimeout元素覆盖。默认设置为Long.MAX_VALUE。
A defaultFairSharePreemptionThreshold element:
设置根队列的公平份额抢占阈值;被根队列中的fairSharePreemptionThreshold元素覆盖。默认设置为0.5f。
A queueMaxAppsDefault element:
设置队列的默认运行应用程序限制;在每个队列中被maxRunningApps元素覆盖。
A queueMaxResourcesDefault element:
设置队列的默认最大资源限制;在每个队列中被maxResources元素覆盖。
A queueMaxAMShareDefault element:
设置队列的默认AM资源限制。在每个队列中被maxAMShare元素覆盖。
A defaultQueueSchedulingPolicy element:
设置队列的默认调度策略。如果指定,则由每个队列中的schedulePolicy元素覆盖。默认为"fair"。
A reservation-agent element:
设置ReservationAgent的实现的类名,该类试图将用户的预订请求放入Plan中。默认值为org.apache.hadoop.yarn.server.resourcemanager.reservation.planning.AlignedPlannerWithGreedy。
A reservation-policy element:
设置SharingPolicy实现的类名,它验证新的保留是否不违反任何不变式。默认值为org.apache.hadoop.yarn.server.resourcemanager.reservation.CapacityOverTimePolicy。
A reservation-planner element:
设置Planner的实现的类名称,如果Plan容量低于(由于计划的维护或节点故障转移)用户保留的资源,则调用该元素。
默认值为org.apache.hadoop.yarn.server.resourcemanager.reservation.planning.SimpleCapacityReplanner,它扫描计划并按相反的接受顺序(LIFO)贪婪地删除保留,直到保留的资源在计划容量之内。
A queuePlacementPolicy element:
包含规则元素列表,这些规则元素告诉调度程序如何将传入的应用程序放入队列中。规则以列出顺序应用。规则可能会引起争论。所有规则都接受“创建”参数,该参数指示规则是否可以创建新队列。“创建”默认为true;
如果设置为false且该规则会将应用程序放置在分配文件中未配置的队列中,则我们继续执行下一条规则。最后一条规则必须是永远不能发出继续的规则。有效规则如下所是:
specified:
将应用放入请求的队列中。如果应用程序没有请求队列,即应用配置的"default"规则,则我们继续。如果应用程序请求队列名称以句号开头或结尾,即".q1"或"q1"之类的名称。将被拒绝。
user:
应用程序以提交用户的名称放入队列中。用户名中的句点将被替换为"_dot_",即用户"first.last"的队列名称为"first_dot_last"。
primaryGroup:
将应用程序放入队列中,队列中包含提交该应用程序的用户的主要组的名称。组名中的句点将被替换为"_dot_",即组"one.two"的队列名称为"one_dot_two"。
secondaryGroupExistingQueue:
将应用程序放入队列中,该队列的名称与提交该应用程序的用户的次要组相匹配。
将选择与已配置队列匹配的第一个辅助组。组名中的句点将被替换为"_dot_",即,如果存在这样一个队列,则以"one.two"作为其次要组之一的用户将被放入"one_dot_two"队列中。
nestedUserQueue:
将应用程序放入用户队列中,用户名位于嵌套规则建议的队列下。这类似于"user"规则,区别在于"nestedUserQueue"规则,可以在任何父队列下创建用户队列,而"user"规则仅在根队列下创建用户队列。
请注意,仅当嵌套规则返回父队列时,才会应用nestedUserQueue规则。可以通过将队列的"type"属性设置为"parent"来配置父队列,或者通过在该队列下配置至少一个叶子作为父节点来配置父队列。有关示例用例,请参见分配示例。
default:
将应用程序放入默认规则的'queue'属性中指定的队列中。如果未指定'queue'属性,则将应用程序放置在'root.default'队列中。
reject:
该应用程序被拒绝。
温馨提示:
为了与原始FairScheduler向后兼容,可以将"queue"元素命名为"pool"元素。
博主推荐阅读:
https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
3>.一个fair-scheduler.xml示例文件
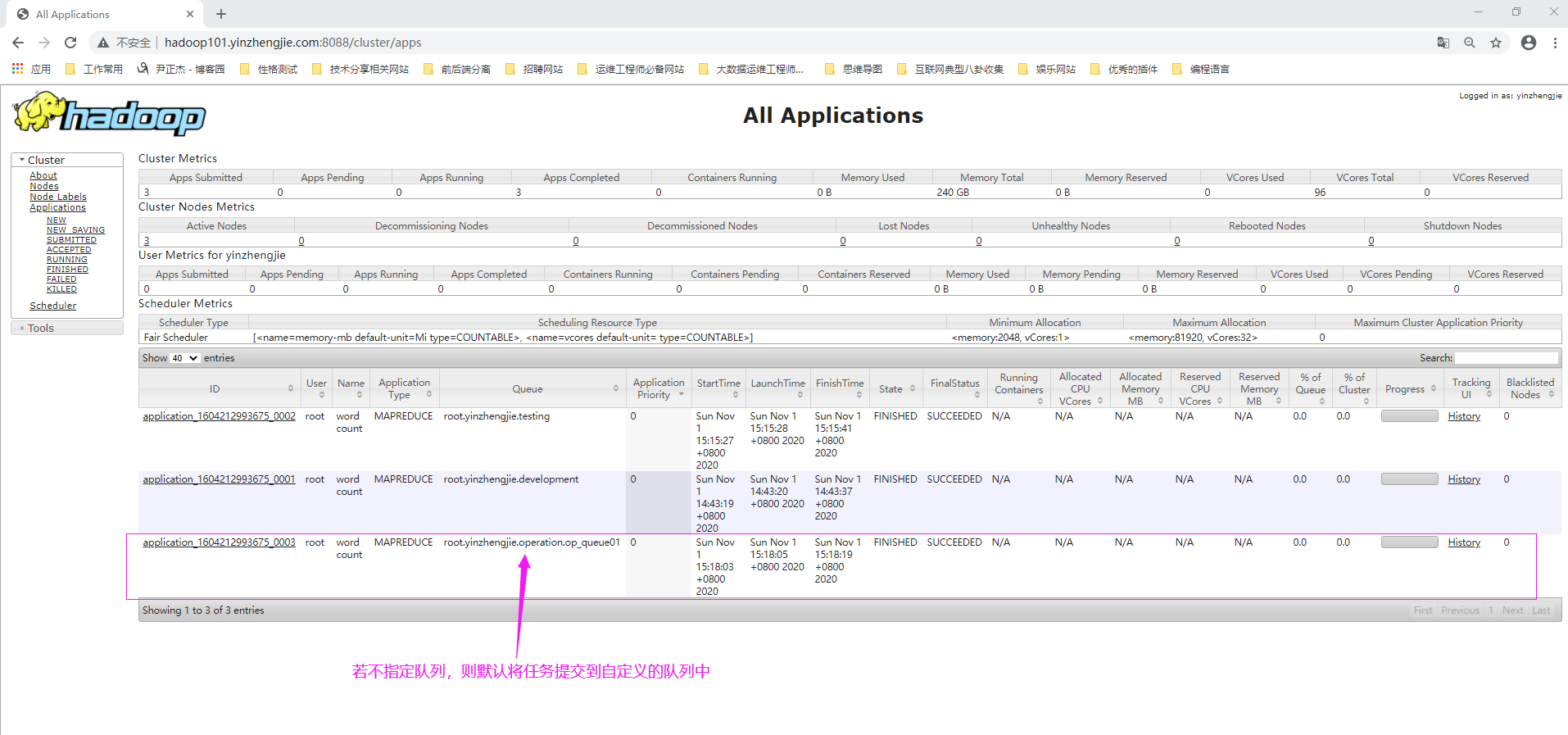
[root@hadoop101.yinzhengjie.com ~]# mkdir -v ${HADOOP_HOME}/etc/hadoop/conf mkdir: created directory ‘/yinzhengjie/softwares/hadoop/etc/hadoop/conf’ [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/conf/fair-scheduler.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/conf/fair-scheduler.xml <?xml version="1.0"?> <allocations> <queue name="yinzhengjie"> <minResources>2048 mb,1vcores</minResources> <maxResources>4096 mb,4vcores</maxResources> <maxRunningApps>50</maxRunningApps> <maxAMShare>0.1</maxAMShare> <weight>2.0</weight> <schedulingPolicy>fair</schedulingPolicy> <queue name="operation" > <queue name="op_queue01" ></queue> <queue name="op_queue02" ></queue> </queue> <queue name="development" ></queue> <queue name="testing" ></queue> </queue> <queueMaxAMShareDefault>0.5</queueMaxAMShareDefault> <queueMaxResourcesDefault>4096 mb,6vcores</queueMaxResourcesDefault> <!-- 不同于容量调度器,公平调度器设计了一个基于规则的系统来为作业分配调度队列。 它内置了一套规则可以插拔式的配置。定义分配规则使用<queuePlacementPolicy/>标签,具体条件使用<rule/>定义。 下面的规则我就不重复介绍了,详情可参考:"https://www.cnblogs.com/yinzhengjie/p/13789883.html" 关于create属性: 若匹配到已经存在的队列,则将作业放到改队列,若匹配不到已经存在的队列,则根据create来选择是否创建队列,默认值是true。 例如,若<rule name="user" create=true/>,此时用户jason提交作业,调度器就会寻找是否有名字为jason的队列,若没有,就会创建名字为jason的队列,并将这个作业放到该队列中。 --> <queuePlacementPolicy> <rule name="specified" create="false" /> <rule name="primaryGroup" create="false" /> <rule name="nestedUserQueue" create="false "> <rule name="secondaryGroupExistingQueue" create="false" /> </rule> <rule name="default" queue="root.yinzhengjie.operation.op_queue01"/> </queuePlacementPolicy> </allocations> [root@hadoop101.yinzhengjie.com ~]#
温馨提示:
如下图所示,配置文件成功后,在间隔10-15秒内会自动刷新配置文件,我们可以在RM Web UI查看调度器队列的情况。
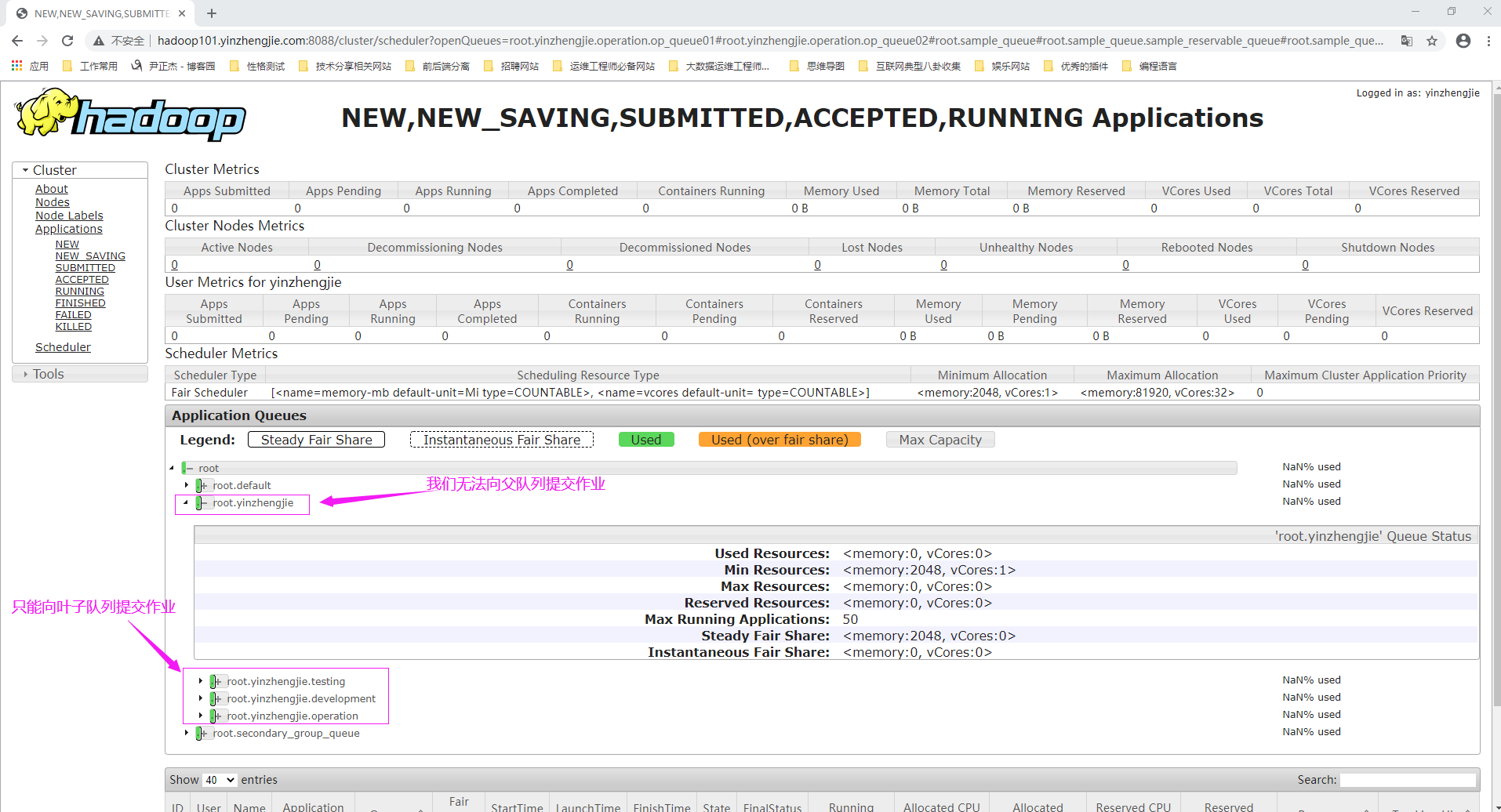
三.将作业提交到调度器
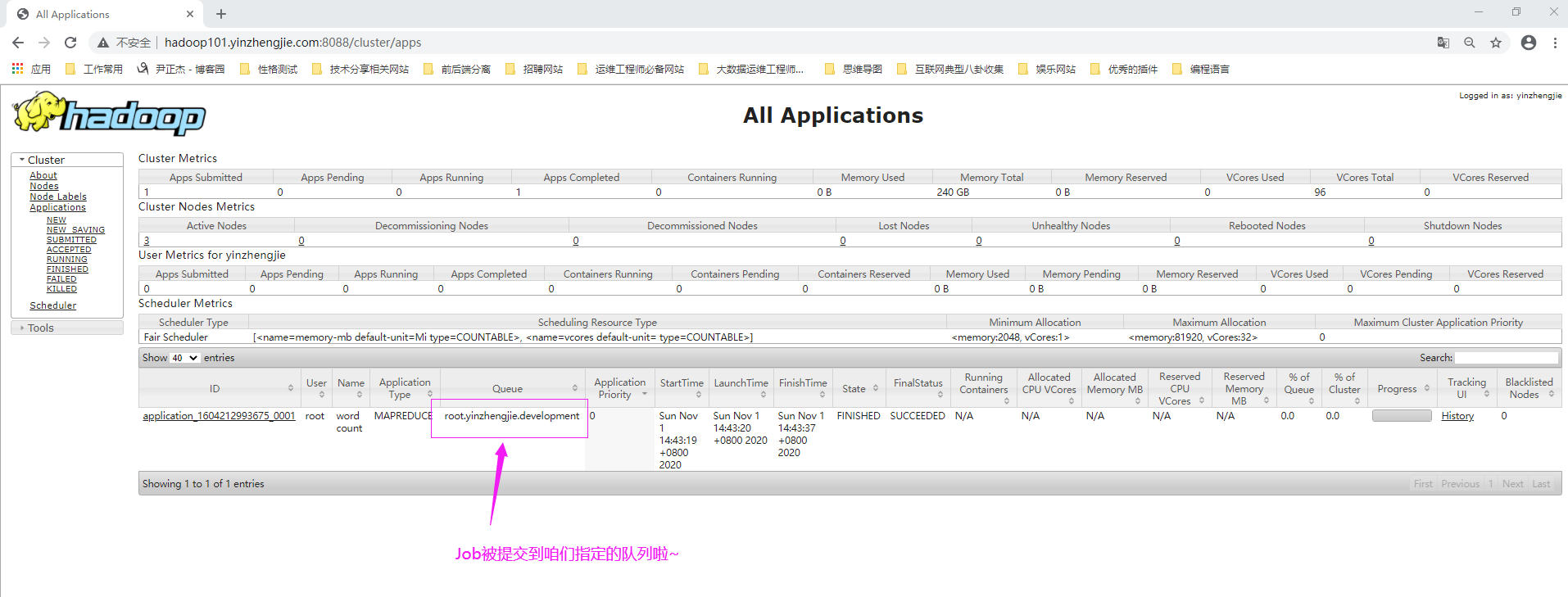
1>.将作业提交到指定"root.yinzhengjie.development"队列


[root@hadoop101.yinzhengjie.com ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount -D mapreduce.job.queuename=root.yinzhengjie.development /input /output
20/11/01 14:43:18 INFO client.RMProxy: Connecting to ResourceManager at hadoop101.yinzhengjie.com/172.200.6.101:8032
20/11/01 14:43:18 INFO input.FileInputFormat: Total input files to process : 1
20/11/01 14:43:18 INFO mapreduce.JobSubmitter: number of splits:1
20/11/01 14:43:19 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/11/01 14:43:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1604212993675_0001
20/11/01 14:43:19 INFO conf.Configuration: resource-types.xml not found
20/11/01 14:43:19 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
20/11/01 14:43:19 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
20/11/01 14:43:19 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
20/11/01 14:43:19 INFO impl.YarnClientImpl: Submitted application application_1604212993675_0001
20/11/01 14:43:19 INFO mapreduce.Job: The url to track the job: http://hadoop101.yinzhengjie.com:8088/proxy/application_1604212993675_0001/
20/11/01 14:43:19 INFO mapreduce.Job: Running job: job_1604212993675_0001
20/11/01 14:43:25 INFO mapreduce.Job: Job job_1604212993675_0001 running in uber mode : false
20/11/01 14:43:25 INFO mapreduce.Job: map 0% reduce 0%
20/11/01 14:43:30 INFO mapreduce.Job: map 100% reduce 0%
20/11/01 14:43:37 INFO mapreduce.Job: map 100% reduce 100%
20/11/01 14:43:39 INFO mapreduce.Job: Job job_1604212993675_0001 completed successfully
20/11/01 14:43:39 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1014
FILE: Number of bytes written=419577
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=781
HDFS: Number of bytes written=708
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=2384
Total time spent by all reduces in occupied slots (ms)=3710
Total time spent by all map tasks (ms)=2384
Total time spent by all reduce tasks (ms)=3710
Total vcore-milliseconds taken by all map tasks=2384
Total vcore-milliseconds taken by all reduce tasks=3710
Total megabyte-milliseconds taken by all map tasks=4882432
Total megabyte-milliseconds taken by all reduce tasks=7598080
Map-Reduce Framework
Map input records=3
Map output records=99
Map output bytes=1057
Map output materialized bytes=1014
Input split bytes=119
Combine input records=99
Combine output records=75
Reduce input groups=75
Reduce shuffle bytes=1014
Reduce input records=75
Reduce output records=75
Spilled Records=150
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=81
CPU time spent (ms)=780
Physical memory (bytes) snapshot=483950592
Virtual memory (bytes) snapshot=7208615936
Total committed heap usage (bytes)=386400256
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=662
File Output Format Counters
Bytes Written=708
[root@hadoop101.yinzhengjie.com ~]#
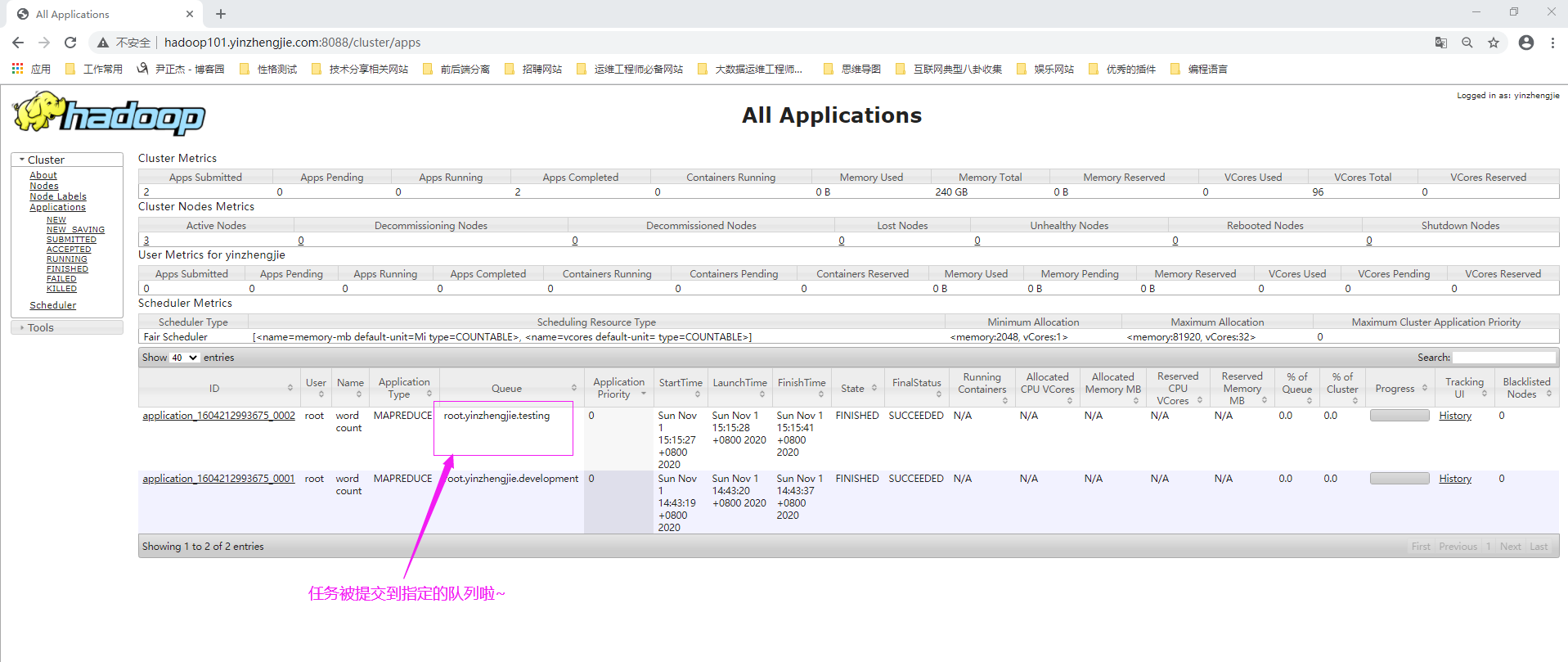
2>.将作业提交到指定"root.yinzhengjie.testing"队列
[root@hadoop101.yinzhengjie.com ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount -D mapreduce.job.queuename=root.yinzhengjie.testing /input /output
20/11/01 15:15:26 INFO client.RMProxy: Connecting to ResourceManager at hadoop101.yinzhengjie.com/172.200.6.101:8032
20/11/01 15:15:26 INFO input.FileInputFormat: Total input files to process : 1
20/11/01 15:15:27 INFO mapreduce.JobSubmitter: number of splits:1
20/11/01 15:15:27 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
20/11/01 15:15:27 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1604212993675_0002
20/11/01 15:15:27 INFO conf.Configuration: resource-types.xml not found
20/11/01 15:15:27 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
20/11/01 15:15:27 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
20/11/01 15:15:27 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
20/11/01 15:15:27 INFO impl.YarnClientImpl: Submitted application application_1604212993675_0002
20/11/01 15:15:27 INFO mapreduce.Job: The url to track the job: http://hadoop101.yinzhengjie.com:8088/proxy/application_1604212993675_0002/
20/11/01 15:15:27 INFO mapreduce.Job: Running job: job_1604212993675_0002
20/11/01 15:15:33 INFO mapreduce.Job: Job job_1604212993675_0002 running in uber mode : false
20/11/01 15:15:33 INFO mapreduce.Job: map 0% reduce 0%
20/11/01 15:15:37 INFO mapreduce.Job: map 100% reduce 0%
20/11/01 15:15:41 INFO mapreduce.Job: map 100% reduce 100%
20/11/01 15:15:42 INFO mapreduce.Job: Job job_1604212993675_0002 completed successfully
20/11/01 15:15:42 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1014
FILE: Number of bytes written=419253
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=781
HDFS: Number of bytes written=708
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1934
Total time spent by all reduces in occupied slots (ms)=2029
Total time spent by all map tasks (ms)=1934
Total time spent by all reduce tasks (ms)=2029
Total vcore-milliseconds taken by all map tasks=1934
Total vcore-milliseconds taken by all reduce tasks=2029
Total megabyte-milliseconds taken by all map tasks=3960832
Total megabyte-milliseconds taken by all reduce tasks=4155392
Map-Reduce Framework
Map input records=3
Map output records=99
Map output bytes=1057
Map output materialized bytes=1014
Input split bytes=119
Combine input records=99
Combine output records=75
Reduce input groups=75
Reduce shuffle bytes=1014
Reduce input records=75
Reduce output records=75
Spilled Records=150
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=89
CPU time spent (ms)=840
Physical memory (bytes) snapshot=515182592
Virtual memory (bytes) snapshot=7209365504
Total committed heap usage (bytes)=388497408
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=662
File Output Format Counters
Bytes Written=708
[root@hadoop101.yinzhengjie.com ~]#
3>.不指定提交的队列,运行Job观察默认规则是否生效
[root@hadoop101.yinzhengjie.com ~]# hdfs dfs -rm -r /output 20/11/01 15:17:48 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop101.yinzhengjie.com:9000/output' to trash at: hdfs://hadoop101.yinzhengjie.com:9000/user/root/.Trash/Current/output1604215 068898[root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /input /output 20/11/01 15:18:02 INFO client.RMProxy: Connecting to ResourceManager at hadoop101.yinzhengjie.com/172.200.6.101:8032 20/11/01 15:18:03 INFO input.FileInputFormat: Total input files to process : 1 20/11/01 15:18:03 INFO mapreduce.JobSubmitter: number of splits:1 20/11/01 15:18:03 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled 20/11/01 15:18:03 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1604212993675_0003 20/11/01 15:18:03 INFO conf.Configuration: resource-types.xml not found 20/11/01 15:18:03 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 20/11/01 15:18:03 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE 20/11/01 15:18:03 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE 20/11/01 15:18:03 INFO impl.YarnClientImpl: Submitted application application_1604212993675_0003 20/11/01 15:18:03 INFO mapreduce.Job: The url to track the job: http://hadoop101.yinzhengjie.com:8088/proxy/application_1604212993675_0003/ 20/11/01 15:18:03 INFO mapreduce.Job: Running job: job_1604212993675_0003 20/11/01 15:18:09 INFO mapreduce.Job: Job job_1604212993675_0003 running in uber mode : false 20/11/01 15:18:09 INFO mapreduce.Job: map 0% reduce 0% 20/11/01 15:18:14 INFO mapreduce.Job: map 100% reduce 0% 20/11/01 15:18:20 INFO mapreduce.Job: map 100% reduce 100% 20/11/01 15:18:20 INFO mapreduce.Job: Job job_1604212993675_0003 completed successfully 20/11/01 15:18:20 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=1014 FILE: Number of bytes written=419187 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=781 HDFS: Number of bytes written=708 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=1922 Total time spent by all reduces in occupied slots (ms)=1977 Total time spent by all map tasks (ms)=1922 Total time spent by all reduce tasks (ms)=1977 Total vcore-milliseconds taken by all map tasks=1922 Total vcore-milliseconds taken by all reduce tasks=1977 Total megabyte-milliseconds taken by all map tasks=3936256 Total megabyte-milliseconds taken by all reduce tasks=4048896 Map-Reduce Framework Map input records=3 Map output records=99 Map output bytes=1057 Map output materialized bytes=1014 Input split bytes=119 Combine input records=99 Combine output records=75 Reduce input groups=75 Reduce shuffle bytes=1014 Reduce input records=75 Reduce output records=75 Spilled Records=150 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=89 CPU time spent (ms)=950 Physical memory (bytes) snapshot=490921984 Virtual memory (bytes) snapshot=7208210432 Total committed heap usage (bytes)=388497408 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=662 File Output Format Counters Bytes Written=708 [root@hadoop101.yinzhengjie.com ~]#
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/13789883.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

