

Hadoop集群资源管理篇-资源调度器
Hadoop集群资源管理篇-资源调度器
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Hadoop中的资源分配概述
1>.Hadoop资源分配的是什么

资源分配是指向使用Hadoop集群的用户分配稀缺的有限计算资源,如CPU时间,内存,存储空间和网络带宽等。 目前Hadoop 2.x版本中,主要是支持CPU(vcore)和内存(RAM)的资源控制。但在Hadoop 2.8,3.0.0-ALPHA1版本中,新增了基于cgroups技术(注意docker就是基于它来做资源限制的)支持磁盘I/O隔离 理论上,有无限的资源集合。可以想象所有这些用户群体,每个用户都有自己的期限,优先级和服务水平协议(Service Level Agreement,下面简称"SLA"),并且不会造成个人(或群组)资源使用冲突。 但在现实生活中,每一种资源都是有限的,大数据运维工程师的工作就是为多个竞争用户群体分配可用的有限资源,确保为每个组的关键工作分配足够的资源以便在期限内完成工作。 博主推荐阅读:(主要是一些Hadoop 3.x的新特性) 了解即可(主要是对于YARN相关介绍的,因为本篇博客主要讲解的是YARN组件): 添加cgroups支持磁盘I/O隔离: https://issues.apache.org/jira/browse/YARN-2619 YARN时间轴服务v.2:alpha 1: https://issues.apache.org/jira/browse/YARN-2928 用curator实现RM leader选举: https://issues.apache.org/jira/browse/YARN-4438 Linux的namespace和cgroups简介: https://www.cnblogs.com/yinzhengjie/p/12183066.html 综上所述,主要是一些YARN的BUG修复,但并不能代表Hadoop 3.x的所有特性,生产环境中每位大数据运维工程师可能使用的是不同的版本,因此关于版本的新特性建议以官方文档为主。当您使用时应该仔细阅读相应的文档: Hadoop 3.0新特性: http://hadoop.apache.org/docs/r3.0.0/ http://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-common/release/3.0.0/RELEASENOTES.3.0.0.html Hadoop 3.1新特性: http://hadoop.apache.org/docs/r3.1.0/ http://hadoop.apache.org/docs/r3.1.4/hadoop-project-dist/hadoop-common/release/3.1.4/RELEASENOTES.3.1.4.html Hadoop 3.2新特性(该版本生产环境不推荐使用): http://hadoop.apache.org/docs/r3.2.0/ http://hadoop.apache.org/docs/r3.2.0/hadoop-project-dist/hadoop-common/release/3.2.0/RELEASENOTES.3.2.0.html Hadoop 3.3新特性: http://hadoop.apache.org/docs/r3.3.0/ http://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-common/release/3.3.0/RELEASENOTES.3.3.0.html 温馨提示: 如下图所示,我们可以调研我们正在使用的Hadoop版本的一些BUG修复情况。 https://issues.apache.org/jira/browse/YARN-10455?jql=project%20%3D%20YARN%20AND%20fixVersion%20%3D%202.10.2
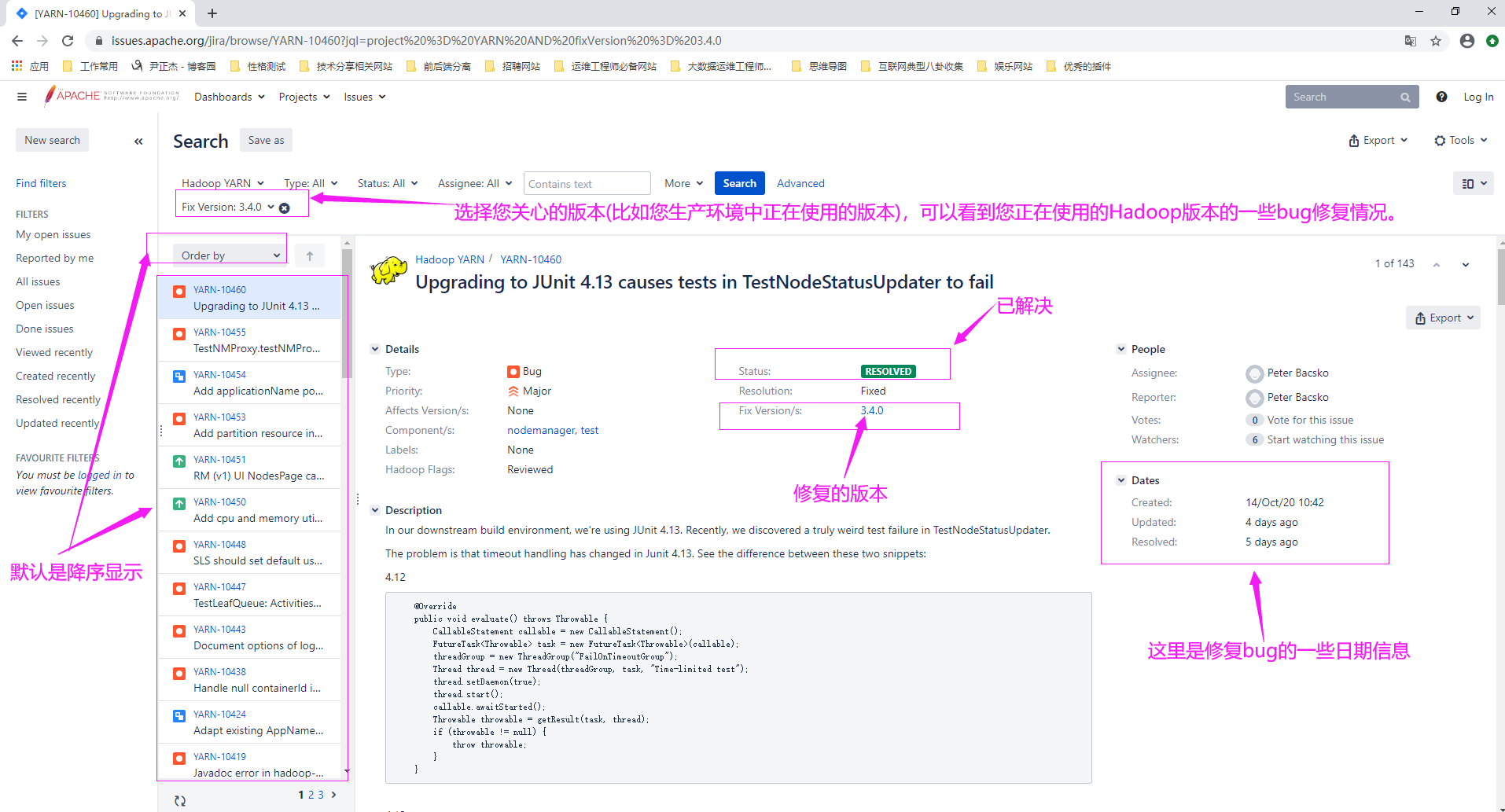
2>.大数据运维工程师负责管理集群的工作负载
作为一个Hadoop管理员,一个关键任务就是平衡工作负载,以便于满足SLA和用户的期望。Hadoop提供了几个非常强大的资源调度器(公平调度器和容量调度器)来管理集群的工作负载。 Hadoop资源调度器是负载将任务分配给各种DataNodes上的可用YARN容器的组件。调度器是ResourceManager中的一个插件。 可用将Hadoop调度器视作位一个工具,它使集群的多个租户共享集群,并以有效和及时的方式使用集群资源,同时它还注意集群的总分配容量。在这样的情况下资源通常指内存(RAM)和处理能力(CPU内核),尽管我们也可用将磁盘存储(比如可用设置配额)作为资源。 假设有一个典型的场景,在这个场景中需要满足不同SLA的各种用户组。除了这些用户组之外,还有几个数据科学家可以在集群中执行长时间运行的作业,这些作业可能需要24小时或更长时间才能完成。需要严格满足SLA的用户无法接收任务运行超过工作窗口,而数据科学家和分析师希望我们公平的分配资源,不至于使它们的任务一致运行。 这里最大的问题是,如果位数据科学家提供大量资源(它们的工作将占用大量资源,它们的数据集通常非常大),则有严格SLA要求的关键任务将超过其分配的工作窗口。 我们使用基于Hadoop资源调度器之一的资源分配策略(具体来说就是公平调度调度器),并使用权重和其它优先级分配策略来确保SLA的作业按时完成。如果这些作业没有运行,则位数据科学家分配的资源会增多,因此他们的工作可以在合理的时间内完成。 温馨提示: (1)资源调度器策略允许优先处理集群允许的各种任务; (2)容量调度器是Apache Hadoop的默认调度器,而对于某些Hadoop发行版本,如Cloudera,则公平调度器是默认调度器。
3>.资源调度器概述
资源调度器是Hadoop YARN中最核心的组件之一,它是ResourceManager中的一个插件式服务组件,负责整个集群资源的管理和分配。Hadoop最初是为批处理作业而设计的,当时(MRv1)仅采用了一个简单的FIFO调度机制分配任务。 但随着Hadoop的普及,单个Hadoop集群中的用户量和应用程序种类不断累加,适用于批处理场景的FIFO调度机制不能很好地利用集群资源,也不能够满足不同应用程序的服务质量要求,因此,设计适用于多用户的资源调度器势在必行。 从目前看来,主要有两种多用户资源调度器的设计思路:第一种是在一个物理集群上虚拟多个Hadoop集群,这些集群各自拥有全套独立的Hadoop服务,典型的代表是HOD(Hadoop On Demand)调度器;另一种是扩展YARN调度器,使之支持多个队列多用户,这也是本篇博客要介绍的重点。 YARN资源调度器是直接从MRv1基础上修改而来的,它提供了三种可用资源调度器,分别是FIFO(First In First Out),Yahoo!的Capacity Scheduler和Facebook的Fair Scheduler,它们的实现原理和实现细节与MRv1中对应三种调度器基本一致。 在YARN中,资源调度器是以层级队列方式组织资源的,这种组织方式符合不同公司的组织架构,有利于资源在不同资源件分配和共享,进而提高集群资源利用率。
二.资源调度器背景
Hadoop最初设计目的是支持大数据批处理作业,如日志挖掘,Web索引等作业,为此,Hadoop仅提供了一个非常简单的调度机制:FIFO(First in First out),即先来先服务,在该调度机制下,所有作业被统一提交到一个队列中,Hadoop按照提交顺序依次运行这些作业。
但随着Hadoop的普及,单个Hadoop集群的用户量越来越大,不同用户提交的应用程序往往具有不同服务质量要求(Quality of Service,简称"Qos"),典型应用有以下几种:
(1)批处理作业:
这种作业往往耗时较长,对时间完成一般没有严格要求,如数据挖掘,机器学习等方面的应用程序。
(2)交互式作业:
这种作业往往期望及时返回结果,如SQL查询(Hive,Imapa,Kylin,presto)等。
(3)生产线作业:
这种作业往往要求有一定的资源保证,如统计值计算,垃圾数据分析等。
此外,这些应用程序对硬件资源需求量也是不同的,如过滤,统计类作业一般为CPU密集型作业,而数据挖掘,机器学习作业一般为I/O密集型作业。因此,简单的FIFO调度策略不仅不能满足多样化需求,也不能充分利用硬件资源。
为了克服单队列FIFO调度器的不足,多种类型的用户多队列调度器诞生了。当前主要有两种多用户资源调度器的设计思路:
(1)在一个物理集群上虚拟多个Hadoop集群,这些集群各自拥有全套独立的Hadoop服务。
典型的代表是HOD调度器;
(2)扩展Hadoop调度器,使之支持多个队列多用户,这种调度器允许管理员按照应用需求对用户或者应用程序分组,并为不同的分组分配不同的资源量,同时通过添加各种约束放置单个用户或者应用程序独占资源,进而能够满足各种Qos需求。
典型代表是Yahoo!的Capacity Secheduler和Facebook的Fair Scheduler。
三.Hadoop的资源调度器类型
1>.HOD(全称为"Hadoop On Demand")调度器概述
HOD(全称为"Hadoop On Demand")调度器是一个在共享物理集群上管理若干个Hadoop集群的工具,用户可用通过HOD调度器在一个共享物理集群上快速搭建若干个独立的虚拟Hadoop集群,以满足不同的用户,比如运行不同类型的应用程序,运行不同的Hadoop版本进行测试等。
HOD调度器可使管理员和用户轻松地快速搭建和使用Hadoop。HOD是Hadoop 1.0提供的调度器,由于这种调度器本身的局限性,Hadoop 2.0的发行版本不在包含它。
HOD调度器的工作过程实现中依赖于一个资源管理器来为它分配,回收节点和管理各节点上的作业运行的情况,如监控作业的运行,维护作业的运行状态等。而HOD只需在资源管理器所分配的节点上运行Hadoop守护进程和MapReduce作业即可。
Hadoop 1.0版本中HOD采用的资源管理器是开源的Torque资源管理器。HOD调度器首先使用Torque资源管理器为虚拟Hadoop集群分配节点,然后在分配的节点上启动MapReduce和HDFS中各个守护进程,并自动为Hadoop守护进程和客户端生成的配置文件。
由于HOD在Hadoop 2.0发行版本中已经移除,因此我并不打算在这里去介绍它,感兴趣的小伙伴可以看董西成所写的《Hadoop 技术内幕 深入解析YARN架构设计与实现原理》一书,书中有对HOD作业的调度流程有比较详细的介绍。
综上所述,相比大家对HOD这个调度器也有了一个大概了认识,估计也猜到它的缺陷与不足。从集群管理和资源利用率两方面来看,这种基于完全隔离的集群划分方法存在诸多问题。
(1)从集群角度看,多个Hadoop集群会给运维人员造成管理上的诸多不便;
(2)多个Hadoop集群会导致集群整体利用率低下,这主要是负载不均衡造成的,比如某个集群非常忙碌时另外一些集群可能空闲,也就是说,多个Hadoop集群无法实现资源共享。
(3)如下图所示,考虑到集群回收后数据可能丢失,用户通常将虚拟集群中的数据写到外部的HDFS上。
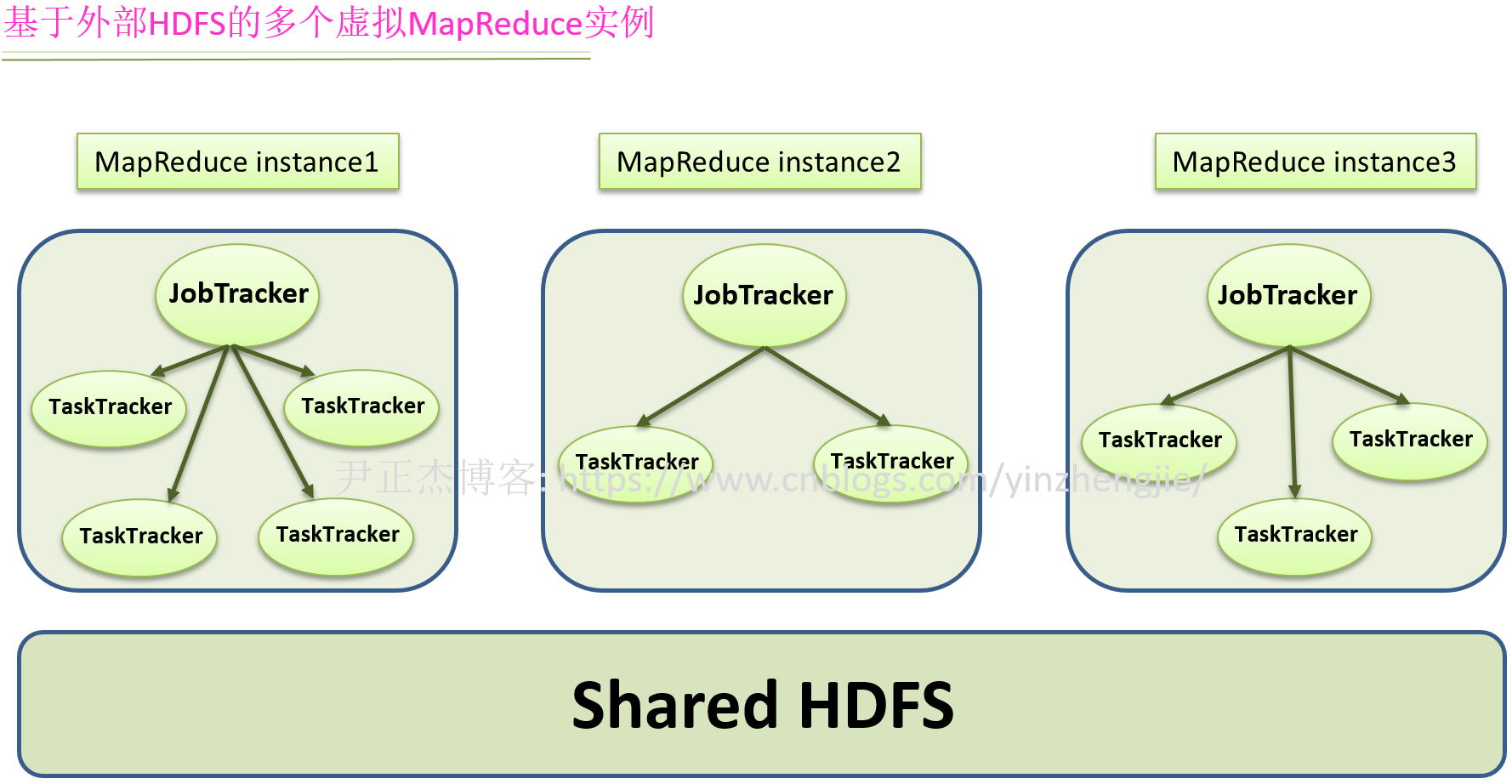
如上图所示,HOD这种资源调度方式会丧失部分数据本地特性。
为解决该问题,一种更好的方法是在整个集群中保留一个Hadoop实例,而通过Hadoop调度器将整个集群中资源划分给若干个队列,并让这些队列共享所有节点上的资源,当前的Yahoo!的Capacity Scheduler和Fackbook的Fair Scheduler正式再用这种设计思路。
2>.FIFO调度器概述
先进先出(FIFO)调度器使用简单的先到先得策略来调度作业。该调度器只需要将所有应用程序放入单个队列中,并按照应用程序提交给YARN的顺序执行它们即可。在先前请求之后进入的请求,只有在先前请求被处理后才会处理后来的请求。
也就是说,在FIFO调度器中,如果两个用户都提交了单独的作业,并且第一个作业需要使用所有的集群资源才能完成工作,则在执行第二个作业的任务之前,必须先完成第一个作业中的所有任务。
由于这是默认调度器,因此它可以开箱即用,不需要再mapred-site.xml文件中进行任何特定的配置更改。FIFO调度器虽然是默认调度器,但其实际上主要用于简单的概念验证或Hadoop集群开发环境,而使用其他两个调度器需要进行各项的配置。
我们来看一个数据科学家运行一个需要20万张地图才能完成的作业场景。可以将数据的总大小除以HDFS的块大小来获取作业的map任务大致数量。在这种情况下,假设数据大约为60TB,HDFS块大小为256MB,则需要提供大约25万个map任务来处理整个数据。
如果集群在任何给定时间内最大容器为约5000个容器,这意味着这个数据科学家的工作将占据整个集群很长时间(如果map任务的平均时间为5分钟,则可以预计至少4个小时才能完成),并且其他作业不能运行。如果一些等待作业需要满足SLA,情况就比较糟糕了!
对于生产环境的服务器,应该配置和使用Hadoop提供的其他调度器(容量调度器和公平调度器)。这两个调度器都非常复杂,可以使用它们控制共享Hadoop集群(大多数集群)中资源的分配。
这两个调度器都克服了默认FIFO调度器的缺点,使多个组能够共享一个集群,同时保证用户和组一些类型的资源分配。
3>.容量调度器(Yahoo!的Capacity Scheduler)概述
容量调度器是Hadoop提供的资源调度程序,可帮助我们分配资源,同时最大化集群的吞吐量及利用率。假设目前组织中有三个不同的团体:销售,营销和研究。通常情况下,这三个组以不同的方式使用Hadoop资源。 例如,销售团队在节假日前可能需要更多的资源,同样,营销组在新的销售活动运行期间可能需要更多的处理能力。 如果你真正了解集群工作负载和利用率,并希望据此在用户之间分配资源,则你可能会考虑使用容器调度器。在某些集群中,这种信息很容易得到,而在其他集群中,则不容易获取。 容量调度器背后的基本概念是:使用专用队列分配作业。每个队列具有分配给它的预定量的资源。但是,由于要保证队列资源的容量,因此可以根据集群的资源利用率来对容量进行设置。 容量调度器的目标是使组织的多个租户(用户)以可预测的方式共享Hadoop集群的资源,Hadoop使用作业队列来实现这一目标。 客户端通过将作业分配到特定的命名队列来调度作业,队列是一个Hadoop作业的有序列表,一个接一个地顺序执行。 调度器为作业队列提供容量的保证,同时为队列的集群利用率提供弹性。在这种情况下的弹性意味着资源的分配没有完全固定。 当队列使用集群资源时,很容易出现一些队列超载,同时其他一些队列相对空闲的情况。而容量调度器可以自动将容量使用较少的队列的为市容容量传输到超载队列。 结果是,集群利用率始终保持较高的值,同时关键的Hadoop作业也具有可预测的完成时间。 容量调度器旨在满足共享Hadoop集群的组织中多个租户的需求,确保每个租户的应用程序能及时分配到资源。目标是最大限度地提高吞吐量并有效利用集群资源。容量调度器使组织中的多个单元通过容量保证的方式来使用同一集群。允许某个单元使用其他单元未使用的任何多余容量。 我们使用一个简单的场景来解释容量调度器的功能。假设你有5个作业队列,为每个队列分配集群总容量的20%,如果队列1超载,则容量调度器从队列2,3,和4中回收可用资源,并将它们分配给队列1,因为过载后需要额外的资源来满足容量保证。 容量调度器依赖作业队列促进集群资源的共享,它为所有集群的作业队列提供最小容量保证。 如果作业队列中有剩余未使用的容量,调度器把多余容量移动给超载的队列使用,从而优化集群资源的利用。 除了保证每个队列的最小容量外,调度器还可以指定队列的最大容量,这是可以分配给队列的的超过其保证容量的绝对上线。 容量调度器设置严格的资源限制,以确保没有单个应用程序,用户或队列(短期内定义)小号与其不相称的集群资源量。它还设置了在给定时间内单个用户或队列可以运行多少个应用程序的限制。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13383344.html
4>.公平调度器(Fackbook的Fair Scheduler)概述
可以使用公平调度器控制Hadoop分配集群资源的方式。公平调度器是一个内置的Hadoop资源调度程序,其目标是让较小的作业快速完成(响应时间较短),并未生产作业提供有保障的服务级别。 我们来看一个典型的中到大型Hadoop集群的例子,例如有500~600个节点,每天有4000~5000个作业,大约偶50~100个用户。通常运行各种类型的数据科学相关的应用程序,如统计报告,优化,垃圾邮件检测等。 这些作业通常不是相同的类型,一些设计到数据导入和小时报告的生产作业。一些其他作业由正在运行特殊Hive查询和Pig作业的数据分析师运行。通常有一些长时间运行的数据分析或机器学习作业同时运行。 作为一名大数据运维工程师,你的问题是如何在这些竞争作业中有效的分配集群的资源。 公平调度器背后的基本思想是:不需要为组或队列预留一定量的内容。调度器在集群中的所有正在运行的作业之间动态分配可用资源。 当大型作业首先启动,并且恰好是运行的唯一作业时,默认情况下将使用所有集群的资源(除非指定了最大资源限制)。 随后,当第二个作业启动时,它被分配大约一半的总集群资源(默认情况下),现在两个作业在相同的基础上共享集群资源。这是"公平"的概念,因此将这个调度器命名为"公平调度器"。 公平调度器确保应用程序的资源分配是"公平"的,这意味着所有应用程序随着时间的推移能获取大致相等数量的资源。当我们在公平调度器的上下文中讨论资源是,资源只是指内存。 不过,也可以使用称为"主导资源公平(DRF)"的调度器,其实公平调度器的辩题,该调度器把内存和CPU都作为资源。"主导资源公平"是一个概念,其中YARN调度器简称每个用户的主导资源(定义为与所有其他用户相比,占用较多的资源类型),并将其用作该用户资源使用量的量度。 在默认情况下,YARN不使用DRF算法,只会考虑内存资源,CPU完全被忽略。可以通过在"fair-scheduler.xml"文件中将"defaultQueueSchedulingPolicy"参数设置为drf来为公平调度器启用DRF。 如果要对容量调度器执行相同操作,可以将"capacity-scheduler.xml"文件中的"capacity.scheduler.capacity.resource-calculator"参数的值设置为"org.apache.hadoop.yar.util.resource.DominantResourceCalculator"。 公平调度器的目标是允许短时间的交互式作业与长期运行的作业并存。它还尝试按比例将资源分配给用户,并确保有效地使用集群。 在这种情况下,公平性意味着资源被分配给最不足够的队列,即调度器总是尝试将容器分配给获得资源最少的队列。可以为队列富裕权重,以确定哪个应用程序获取说明比例的集群资源。 当集群中只有一个应用程序在运行时,公平调度器会将所有集群资源分配给该应用程序。随着新应用程序的启动,资源将从第一个应用程序中被抽取并分配给较新的应用程序,最终所有应用程序都使用大约相同比例的集群资源。 不过,"公平"并不意味着所有队列都被视为同等重要,通常可以为队列配置各种权重,以表示其优先级。 在默认情况下,公平调度器允许所有应用程序运行。但是,可以在每个用户或每个队列的基础上限制运行的应用程序的数量。可以在用户一次提交大量应用程序时限制系统上的压力。 当限制了用户可以提交应用程序的数量时,用户提交的其他应用程序将在队列中等待,直到该用户提交的某些较早的应用程序完成。 公平调度器可以使用不同的调度策略,默认调度策略是公平共享,其仅将内存作为资源。还有一个使用不是很多的FIFO策略。第三种类型是调度策略DRF也很常见,DRF将内存和CPU资源分配给应用程序。 在公平共享策略下,还可以通过分配权重来确定应用程序的优先级,从而确定分配给应用程序的集群资源的百分比。与权重较小的队列相比,具有较高权重的队列将获得更多的关注。 在默认的情况下,所有队列的权重均为1。可以通过为其分配不同的权重以允许某些队列获得比其他队列更多的资源。例如:通过将队列的权重设置为4,可以指定该队列获得4倍于其他队列的资源。 博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/13789883.html
5>.容量调度器和公平调度器的对比
容量调度器的公平调度器有一些重要的区别,但也有许多相似之处。
两个调度器之间的相似之处:
公平调度器和容量调度器都具有相同的目标:允许长时间运行的作业在适合的时间内完成,同时运行查询的用户能够更快速的获得。也就是说,支持批量和短期作业的共存。
两个容量调度器有几个共同点,如下所示:
(1)两个调度器都支持分层队列;
(2)所有队列都从根或默认队列继承;
(3)只能将应用程序提交给叶子队列;
(4)队列都支持最小和最大容量;
(5)都支持限制每个队列的最大应用程序数;
(6)两个调度器都可以跨队列移动应用程序;
两个调度器之间的差异:
容量调度器和公平调度器之间也存在一些重要的区别,如下所示:
(1)公平调度器包含调度策略,用于确定在分配资源时那些作业获取资源。可以使用三种类型的调度策略fifo,fair(默认调度策略)和drf。可以使用defaultQueueSchedulingPolicy元素指定策略。另一方面,容量调度器总是使用FIFO原则来调度每个队列中的作业;
(2)公平调度器支持启用多个队列分配策略,在这些策略下,调度器根据用户,组或应用程序发出的队列请求,在队列之间排列新应用程序的位置。可以通过设置create标志将应用程序提交到不存在的队列;
(3)容量调度器选择当前使用容量和配置容量之间差距最大的作业,也就是说,最缺乏资源的队列在其他队列之前获取资源。另一方面,公平调度器则根据最高的赤字来选择作业;
(4)公平调度器在作业中分配过剩容量,而容量调度器则咋自己群的租户中分配过剩容量;
(5)公平调度器使用抢占策略来支持队列之间的公平性,并通过权重为用户分配优先级。另一方面,容量调度器使用抢占策略将保障的容量返回给队列;
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/13341939.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
标签:
YARN


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
2019-07-19 Pthon魔术方法(Magic Methods)-可视化
2018-07-19 SHELL脚本编程-信号捕捉trap