

Cloudera Certified Associate Administrator案例之Troubleshoot篇
Cloudera Certified Associate Administrator案例之Troubleshoot篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.调整日志的进程级别
问题描述:
今天node103.yinzhengjie.org.cn节点的DataNode和NodeManager进程频繁死掉,你决定临时将该节点两个进程的日志级别调整为DEBUG,以便于进行维护排查。
解决方案:
操作时需注意要求将HDFS和YARN的所有节点日志界别都调整,还是只需要调整还是只需要调整个别节点,两者的调整方式是不一样的,对于个别节点日志级别的临时调整,可以使用yarn daemonlog -setlevel命令来进行,当然通过CM进行更为方便。
1>.点击主机,选择"所有主机"

2>.点击"HDFS DataNode"角色
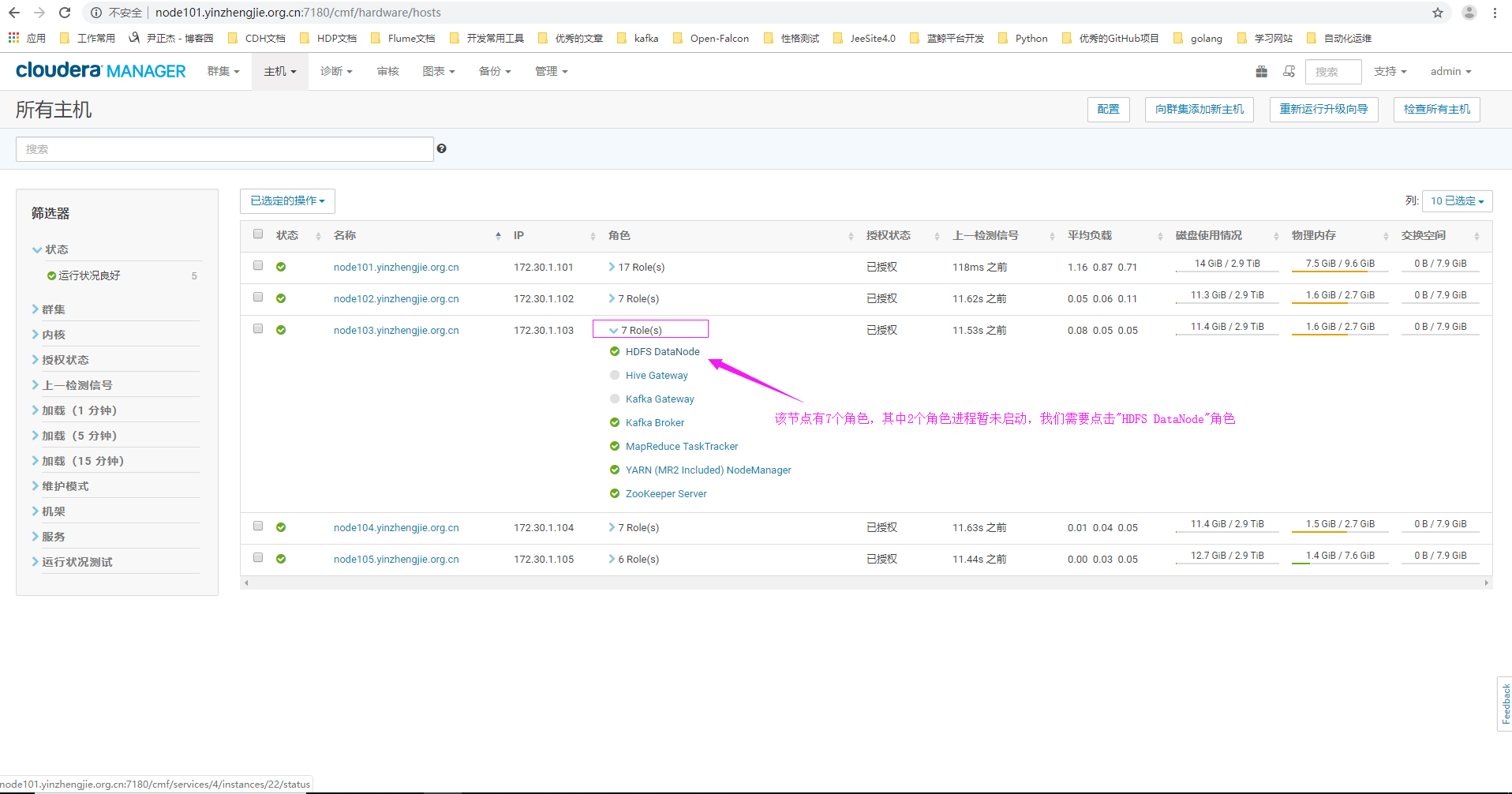
3>.进入"node103.yinzhengjie.org.cn"节点的DataNode角色的配置界面(需要注意的是,此配置只针对该节点生效哟~)
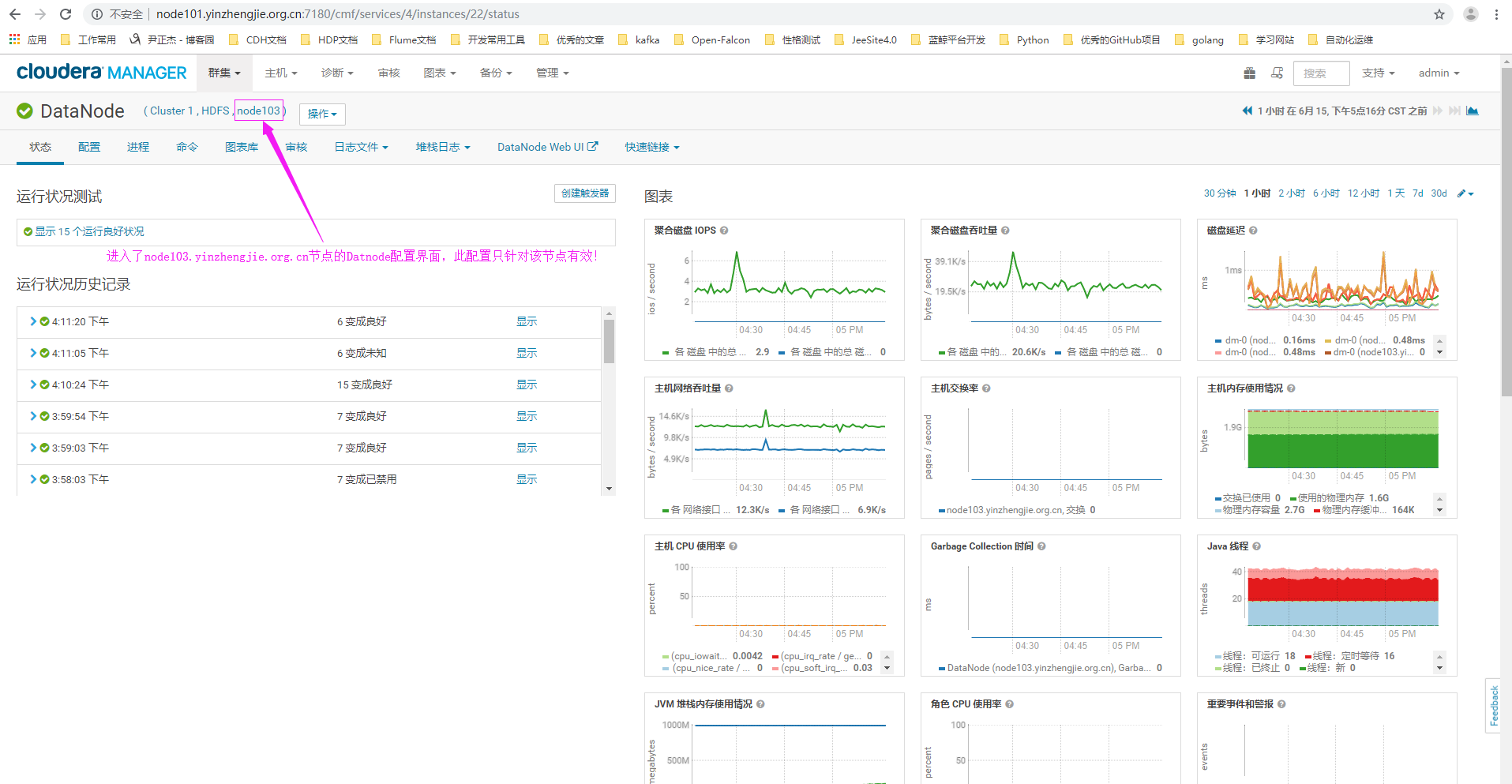
4>.点击配置搜索关键字"DataNode 记录阈值"(英文页面为:"DataNode Logging Threshold")
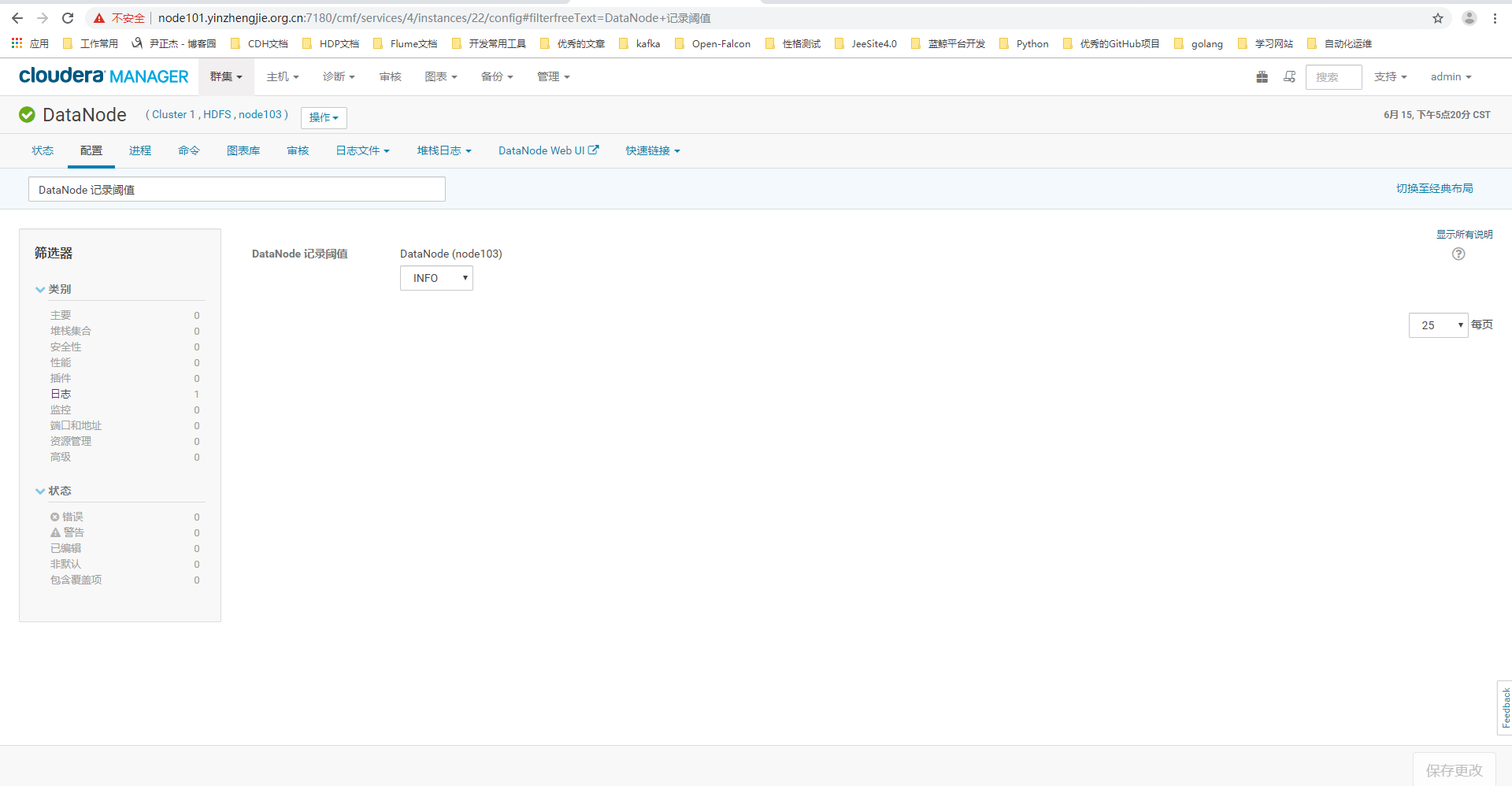
5>.修改"node103.yinzhengjie.org.cn"节点的页面配置为"DEBUG"

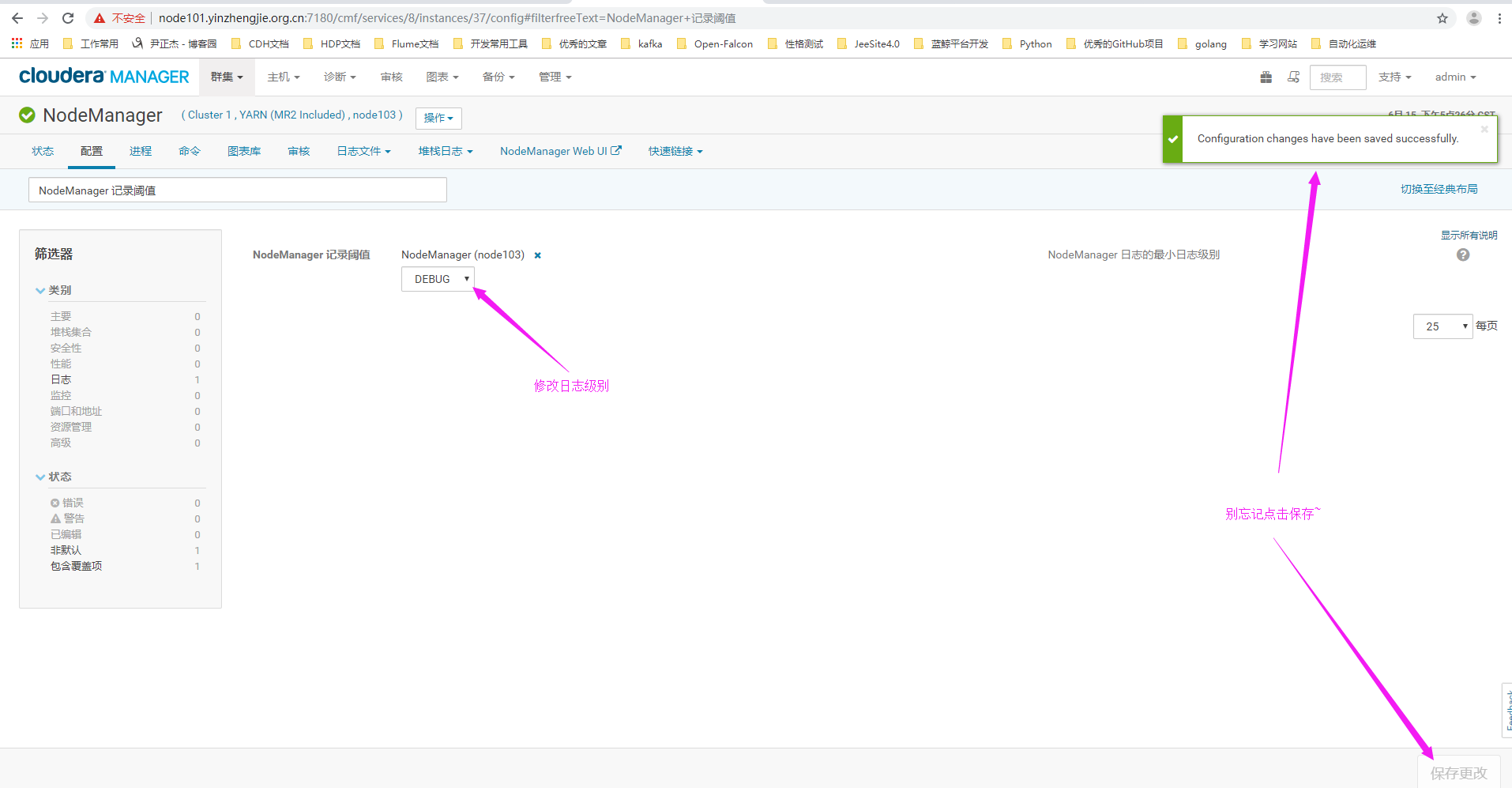
6>.进入NodeManger的WebUI配置界面
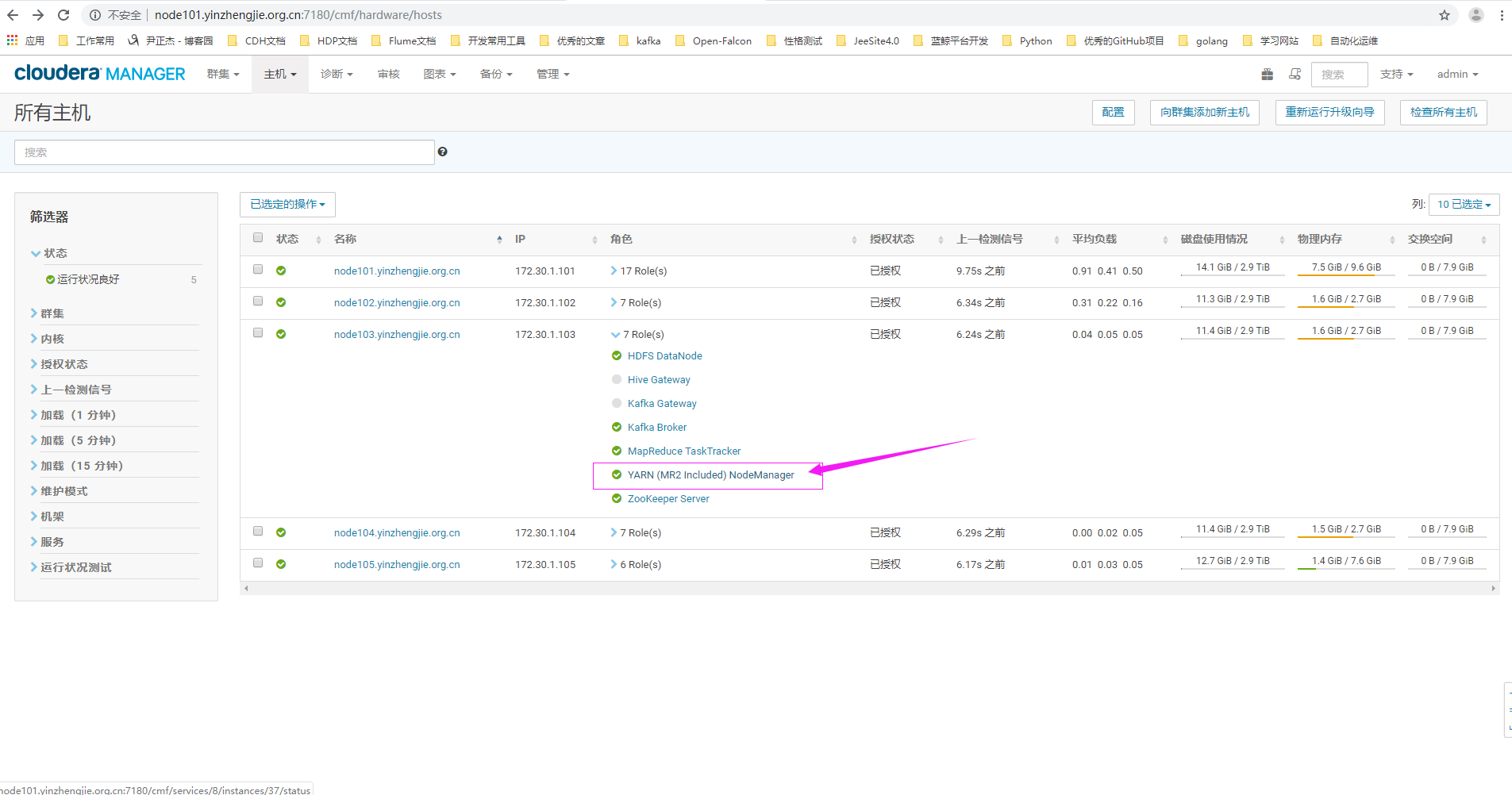
7>.点击配置搜索关键字"NodeManager 记录阈值"(英文页面为:"NodeManager Logging Threshold")
二.运行wordcount
问题描述: 公司的某个开发人员尝试在集群上运行wordcount程序,但作业执行发生错误,请你帮助解决。 请将gateway机器的input.txxt文件上传到HDFS上的“/yinzhengjie/debug/mapreduce/data/input”目录中,并执行"wordcount /yinzhengjie/debug/mapreduce/data/input /yinzhengjie/debug/mapreduce/data/output"来测试是否可以运行。 解决方案: 通常作业失败类型只有目录存在,内存不足,权限部队等简单的几种,难度较低,一般不需要Java语言的知识,只要能看懂英文就可以解决。
1>.上传文件
[root@node101.yinzhengjie.org.cn ~]# ll total 4 -rw-r--r-- 1 root root 553 Jun 15 17:38 input.txt [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]# cat input.txt The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]# hdfs dfs -mkdir -p /yinzhengjie/debug/mapreduce/data/input [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]# hdfs dfs -copyFromLocal input.txt /yinzhengjie/debug/mapreduce/data/input [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /yinzhengjie/debug/mapreduce/data/input Found 1 items -rw-r--r-- 3 root supergroup 553 2019-06-15 17:53 /yinzhengjie/debug/mapreduce/data/input/input.txt [root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]#
2>.执行wordcount


[root@node101.yinzhengjie.org.cn ~]# [root@node101.yinzhengjie.org.cn ~]# su hdfs [hdfs@node101.yinzhengjie.org.cn /root]$ [hdfs@node101.yinzhengjie.org.cn /root]$ cd /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/ [hdfs@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce]$ [hdfs@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce]$ hadoop jar hadoop-mapreduce-examples.jar wordcount /yinzhengjie/debug/mapreduce/data/input /yinzhengjie/debug/mapreduce/data/output 19/06/15 18:00:46 INFO client.RMProxy: Connecting to ResourceManager at node101.yinzhengjie.org.cn/172.30.1.101:8032 19/06/15 18:00:47 INFO input.FileInputFormat: Total input paths to process : 1 19/06/15 18:00:47 INFO mapreduce.JobSubmitter: number of splits:1 19/06/15 18:00:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1560591816714_0001 19/06/15 18:00:47 INFO impl.YarnClientImpl: Submitted application application_1560591816714_0001 19/06/15 18:00:47 INFO mapreduce.Job: The url to track the job: http://node101.yinzhengjie.org.cn:8088/proxy/application_1560591816714_0001/ 19/06/15 18:00:47 INFO mapreduce.Job: Running job: job_1560591816714_0001 19/06/15 18:00:52 INFO mapreduce.Job: Job job_1560591816714_0001 running in uber mode : false 19/06/15 18:00:52 INFO mapreduce.Job: map 0% reduce 0% 19/06/15 18:00:58 INFO mapreduce.Job: map 100% reduce 0% 19/06/15 18:01:03 INFO mapreduce.Job: map 100% reduce 13% 19/06/15 18:01:05 INFO mapreduce.Job: map 100% reduce 38% 19/06/15 18:01:06 INFO mapreduce.Job: map 100% reduce 50% 19/06/15 18:01:08 INFO mapreduce.Job: map 100% reduce 63% 19/06/15 18:01:09 INFO mapreduce.Job: map 100% reduce 88% 19/06/15 18:01:11 INFO mapreduce.Job: map 100% reduce 100% 19/06/15 18:01:12 INFO mapreduce.Job: Job job_1560591816714_0001 completed successfully 19/06/15 18:01:12 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=976 FILE: Number of bytes written=1349146 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=705 HDFS: Number of bytes written=613 HDFS: Number of read operations=27 HDFS: Number of large read operations=0 HDFS: Number of write operations=16 Job Counters Launched map tasks=1 Launched reduce tasks=8 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=3402 Total time spent by all reduces in occupied slots (ms)=22251 Total time spent by all map tasks (ms)=3402 Total time spent by all reduce tasks (ms)=22251 Total vcore-milliseconds taken by all map tasks=3402 Total vcore-milliseconds taken by all reduce tasks=22251 Total megabyte-milliseconds taken by all map tasks=3483648 Total megabyte-milliseconds taken by all reduce tasks=22785024 Map-Reduce Framework Map input records=1 Map output records=87 Map output bytes=901 Map output materialized bytes=944 Input split bytes=152 Combine input records=87 Combine output records=67 Reduce input groups=67 Reduce shuffle bytes=944 Reduce input records=67 Reduce output records=67 Spilled Records=134 Shuffled Maps =8 Failed Shuffles=0 Merged Map outputs=8 GC time elapsed (ms)=453 CPU time spent (ms)=9890 Physical memory (bytes) snapshot=2097287168 Virtual memory (bytes) snapshot=25250430976 Total committed heap usage (bytes)=1470103552 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=553 File Output Format Counters Bytes Written=613 [hdfs@node101.yinzhengjie.org.cn /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce]$
三.
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/11028141.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
