

kubernetes基础及部署说明
kubernetes基础及部署说明
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.容器编排系统生态圈
Docker通过“镜像”机制极富创造性地解决了应用程序打包的根本性难题,它推动了容器技术的快速普及生产落地。 容器本身仅提供了托管运行应用的底层逻辑,而容器编排(Orchestration)才是真正产生价值的所在。
容器编排(Container orchestration)其实就是容器生命周期的管理工具,尤其是在组建一个微服务环境当中,存在的服务数量非常多时,并且期望服务能动态注册,部署等方式来完成环境管理时,容器编排的价值体现更加充分。
云原生以容器为核心技术,分为运行时(Runtime)和 Orchestration 两层,Runtime 负责容器的计算、存储、网络;Orchestration 负责容器集群的调度、服务发现和资源管理。
我们知道在云计算时代,主机编排系统开源的佼佼者自然是OpenStack,比较优秀的容器编排系统有: (1)Docker 容器编编排系统三剑客:docker-compose,docker-swarm(cluster),docker-machine (2)Apache开源的Mesos-marathon和Hadoop-YARN (3)出身名门的(Google)的Kubernetes,借鉴于Google内部Borg和Omega两个非开源容器编排系统(据说在Google内部已经运行10多年之久)运维经验,Google使用Golang编写了K8s。 后者Kubernetes的出现对Docker容器编排系统无疑是降维打击,在2017年底左右,Kubernetes几乎完胜Docker自身编排容器。以至于K8s已经成为容器编排的代名词。 Kubernetes的出现对OpenStack无疑也是一种降维打击,据说京东就用Kubernetes集群替换掉了OpenStack集群。现在很多云服务的商家已经支持K8s一件式部署了,比如亚马逊,微软,阿里等。 所以说你现在还在学习OpenStack无意是落伍了,除非你确定你要去的这家公司正在使用OpenStack,否则我们就没有多大必要花费过多精力去学习它了。因为Kubernetes的出现几乎让OpenStack要凉凉了~ 博主推荐阅读: CNCF(Cloud Native Computing Foundation) 云原生容器生态系统概要(http://dockone.io/article/3006) CNCF Cloud Native Interactive Landscape(https://landscape.cncf.io/) kubernetes设计架构(https://www.kubernetes.org.cn/kubernetes%e8%ae%be%e8%ae%a1%e6%9e%b6%e6%9e%84) kubernetes的GitHub地址(https://github.com/kubernetes/kubernetes)
二.容器编排(container orchestration)系统特点
容器编排是用来管理容器生命周期的组件,尤其是在大规模动态环境当中,比如目前来讲比较火热的微服务技术场景。我们一般而言要使用容器解决以下任务: (1)提供并部署容器; (2)管理容器的冗余及可用性; (3)我们可以通过向上扩展容器的机制或者将容器分散到多个主机之上运行多个容器基于向外扩展的方式来完成系统扩展; (4)容器运行在服务器之上,若随着业务的发展,当前运行的容器的服务器硬件要求不满足该容器的运行条件时,可以把该容器迁移到可以满足的硬件运行环境的物理机上,或者当运行容器的主机挂掉之后依旧可以在另外一个节点启动起来; (5)可以将整个资源在多个容器之间完成合理分配; (6)可以根据业务需求将运行容器的服务暴露到公网; (7)容器之间的服务可以让各组件互相访问(服务发现逻辑); (8)监控容器及各个宿主的运行状态; (9)配置应用程序并确保容器之间他们有关联关系; 简单来说,容器编排是指容器应用的自动布局,协同及管理,它主要负责完成以下具体任务: (1)Service Discovery,即服务发现 (2)Load Balancing,即负载均衡 (3)Secrets/configuration/storage management,即配置和存储管理 (4)Health checks,即健康状态检查 (5)Auto-[scaling/restart/healing] of containers and nodes,即包含容器和节点自动的伸缩/重启/健康状态监测等 (6)Zero-downtime delopys,即零宕机部署(换句话说,我们在部署服务时用户时无法感知的) 以上这些功能恰恰使容器编排变得极其有用且强大的核心原因,容器编排可以解决上述问题自然也就解决了运维工作中的痛点。
三.kubernetes集群架构
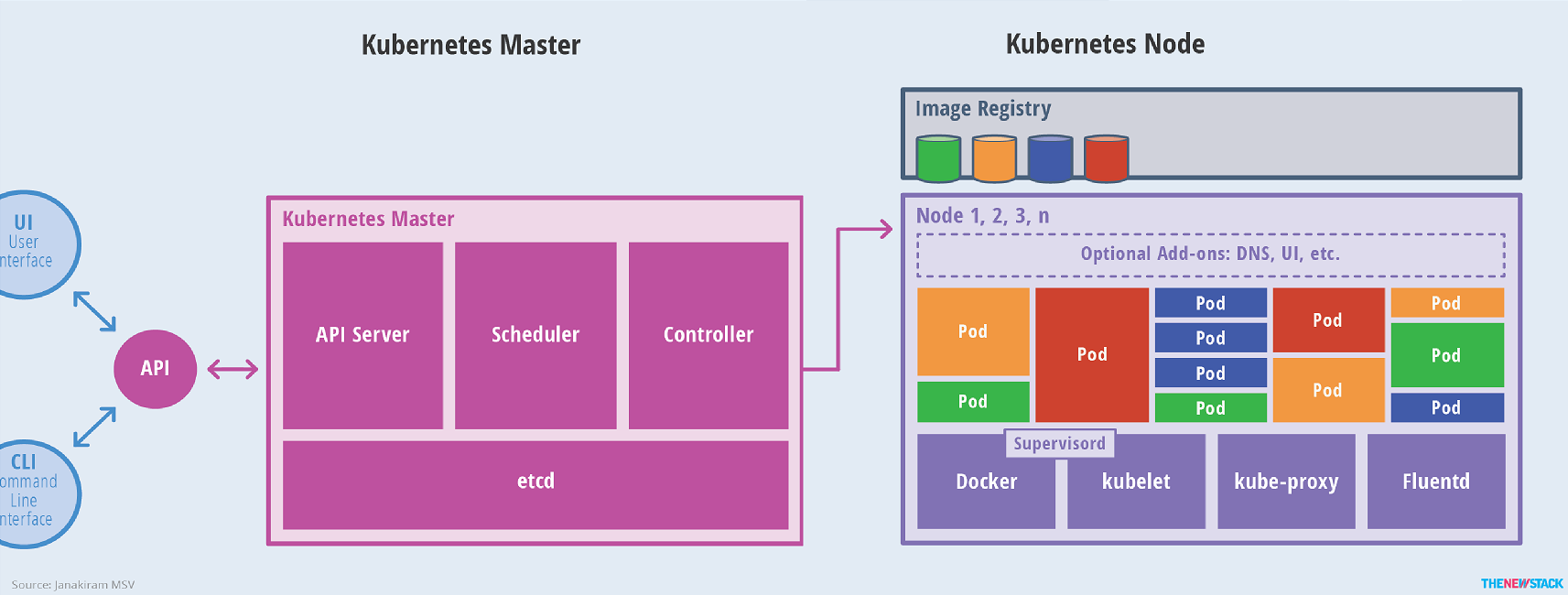
kubernetes是一个可以自动部署(automating deployments),伸缩(scaling)和运维容器化应用(operations of application containers)的开源平台。 如上图所示,相必大家不难看出kubernetes集群(Cluster)两个核心组件,即Kubernetes Master和Kubernetes Node。下面是对Kubernetes Cluster各组件的功能说明。 (1)UI,CLI 统称API用于发送请求给Kubernetes(K8S)集群。 (2)Kubernetes Master 功能上有点类似于Hadoop中的NameNode节点,用于处理客户端的发来的请求,根据需求调度后端节点运行任务。其内部核心组件分为: 1)API Server(K8S内置组件) 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制; 提供API服务的组件,是一个独立的守护进程,是Kubernetes集群的唯一入口(无论是客户端还是内部组件都必须通过它来访问); 它提供基于https(RESTful风格)和rpc协议(grpc是据说是将来要取代Https的RESTful风格)来提供服务的。它用来处理客户端传来的JSON格式的请求数据而非HTML格式哟。它也是K8S集群唯一能操作etcd的组件。 2)Scheduler(K8S内置组件) 负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上; 用于调度的组件,比如客户端通过API Server提交了一个新增容器的请求,该请求保存在etcd中,etcd通过API Server通知Scheduler,Scheduler接收到通知后会在管理的资源中选择一个最佳运行的节点去创建容器; 该指令依旧存放在etcd中(Scheduler不能直接访问etcd,而是通过API Server间接访问etcd)。 3)Controller manager(K8S内置组件) 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等; 该组件会watch Api Server组件用于管理K8S集群的组件,确保我们所创建的容器能够按照期望的状态运行的核心组件(比如:监控集群的所有容器运行,当某个容器挂掉后它可以迅速在另一个节点启动),我们甚至可以说Controller manager是K8s的大脑。 4)etcd(并不是K8S内置组件,该组件是由CoreOS公司研发,该公司还研发了一款叫做Rkt的容器引擎,虽说有Google公司的支持,但依旧没有撼动Docker容器的地位,后来CoreOS被RedHat公司收购,最终Redhat又被IBM公司收购啦~) 保存了整个集群的状态; etcd只能被API Server直接访问。是整个集群的核心,负责存储K8S请求数据所有的数据。 etcd基于raft协议使用Golang语言开发的分布式强一致的键值对(key/value)数据库存储系统。存储方式和redis很像,但是功能却比redis要强大,因为它支持数据的强一致性,也支持leader选举等各种分布式协同功能。 (3)Kubernetes Node 功能上有点类似于Hadoop中的DataNode节点,被Kubernetes调度的,即负责真正干活的节点(运行容器)。其内部核心组件分为: 1)kubelet 负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理; 该组件也会watch Api Server组件,即实时查看关于当前节点的任务,从而去执行创建或删除容器的任务(以Docker为例,创建容器时就会调用docker的API去Image Registry去下载相应的容器并启动)。 2)Container runtime 负责镜像管理以及Pod和容器的真正运行(CRI); 典型代表有Docker,其实kubernetes可远远不止支持Docker一种容器,它支持很多类型的容器,比如kubernetes有自己的容器引擎,上面提到的CoreOS提供的rkt,以及frakti等。 不过迄今为止,我们不得不说Docker是容器的佼佼者,它也是容器的代名词。因此K8S标准只支持Docker,其它容器引擎都通过CRI(Container Runtime Interface)组件来支持。不仅如此,K8S还支持容器存储的CSI和容器网络CNI的相关接口。 3)kube-proxy 负责为Service提供cluster内部的服务发现和负载均衡; kube-proxy说白了也是API Server的客户端,它实时监视(watch)着API Server上的资源变动(尤其是service资源变动),它会把每个service资源变动在相应节点上定义为对外暴露相关规则(iptable或者ipvs),比如对外暴露外网映射之类的。 4)Pod 虽然我们说Kubernetes是容器编排系统,但是不得不说在K8S之上并不会直接运行容器,每个容器在K8S中都被重新封装成pod,说白了pod就是容器的外壳,但需要注意的是一个pod是可以存在多个容器的。每个pod被K8S当作一个原子单元进行管理; 我们习惯上说pod是k8s集群中的的基本运行单元,比如一个pod中有多个容器,这意味这个pod里面的所有容器只能被调度到一台节点去执行,不能将同一个pod里面的多个容器拆分到不同的Node运行; 温馨提示,K8S集群中同一个pod里面多个容器是共享了UTS,Network,IPC,也就是说同一个pod多个容器可以通过lo网卡接口进行通信哟。 5)Fluentd
如Fluentd-elasticsearch提供集群日志采集、存储与查询
(4)Image Registry 存放镜像文件的仓库,并不直接被Kubernetes集群管理,即并不算k8s原生组成部分,通常我们会自建私有的镜像仓库,比如使用Harbor部署https高可用的镜像仓库。
和K8S相关的公网镜像仓库:
Docker Hub(Docker官网维护)
k8s.grc.io(Google公司维护,需要FQ访问)
quay.io(由之前的CoreOS维护)
(5)附加组件(Add-ons)
DNS(完成服务注册和服务发现)
CNI(全称"Container Network Interface",即容器网络接口插件,如flannel,colico等)
Web UI(为用户提供管理界面,如Dashboard)
Cluster(level Logging)
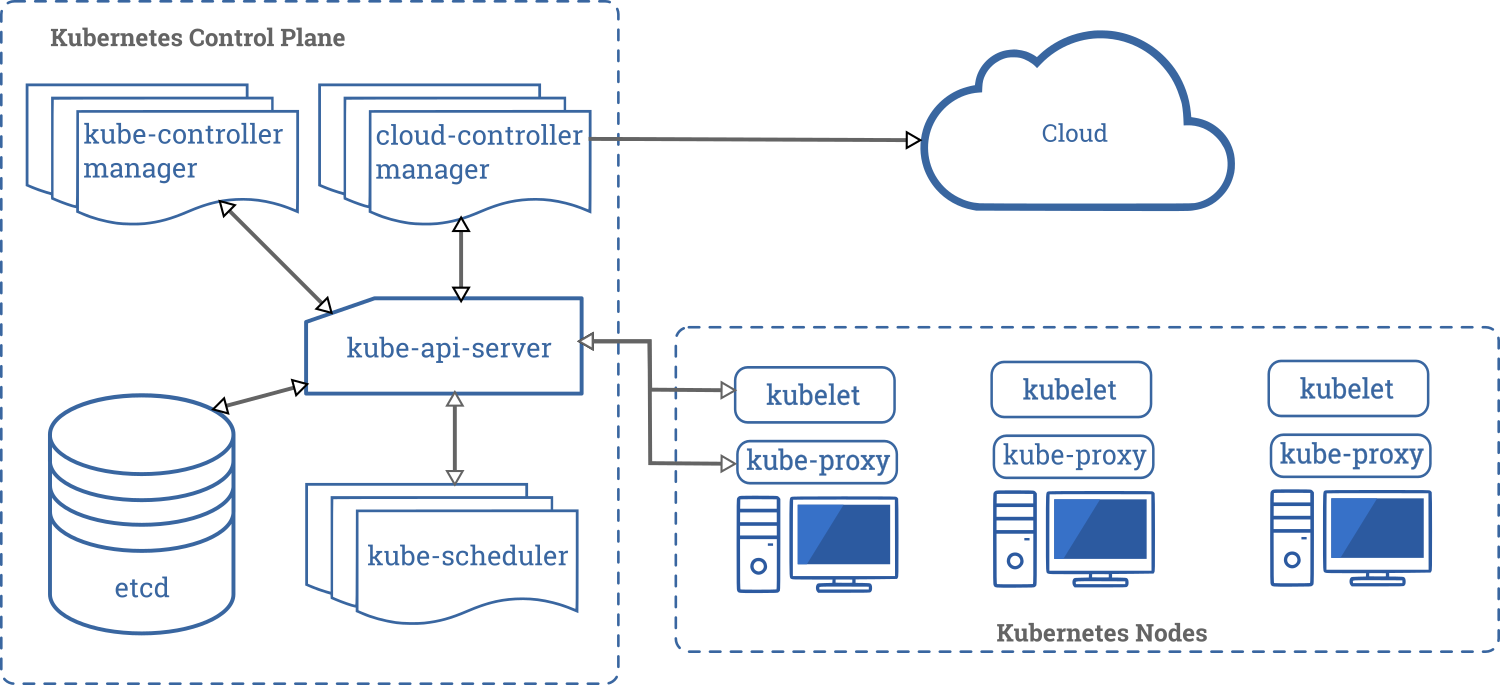
如下图所示,是kubernetes的组件图,从图中可以看出能和etcd交互的就只有API Server,因此在生产环境中应该将etcd配置为高可用集群,而API Server也是至关重要的,所有组件通信都得通过它,有点类似于冯诺依曼体系中的总线角色,因此API Sever也是至关重要的角色。博主推荐阅读:https://kubernetes.io/docs/concepts/overview/components/
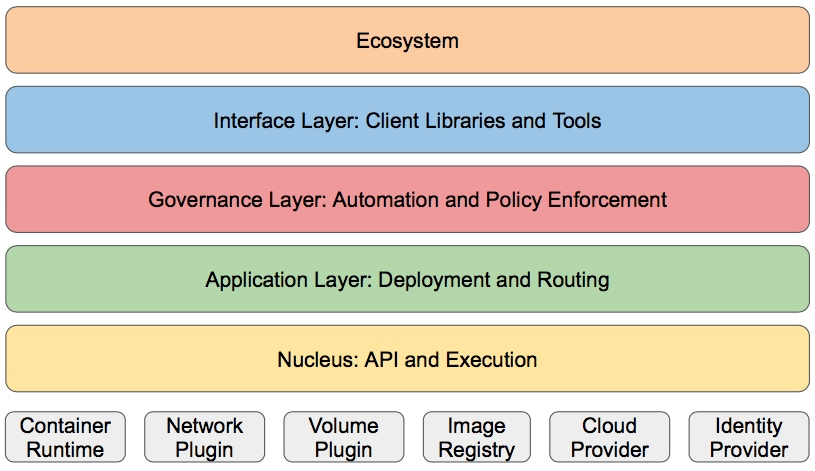
四.Kubernetes设计理念
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示。
核心层:
Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
应用层:
部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
管理层:
系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
接口层:
kubectl命令行工具、客户端SDK以及集群联邦
生态系统:
在接口层之上的庞大容器集群管理调度的生态系统,可以划分为以下两个范畴:
Kubernetes外部:
日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
Kubernetes内部:
CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
博主推荐阅读:
https://www.kubernetes.org.cn/kubernetes%e8%ae%be%e8%ae%a1%e7%90%86%e5%bf%b5
五.Kubernetes Network
kubernetes的网络大致分为以下三类:
节点网络:
主要是指Kubernetes Master和各个Kubernetes Node之间进行通信的网络地址段。
pod网络:
我们知道pod被运行在各个Kuberbernetes Node之上,如果各个Node之间的pod想要相互通信它们并不会直接进行通信,因为每个pod的动态IP地址,所以每个pod并不知道想要访问的目的pod的IP地址,它们如果想要访问目的pod需要经过一个service层。
这个service有对每个pod的打了标签,当任意一个节点的pod想要访问另外一个pod必须得经过service网络,service网络保存着标签选择器,可以迅速匹配到pod想要范围另一个pod的真实IP地址,当pod拿到IP地址后就可以自行进行通信请求了。
service网络:
主要是为pod提供一个标签选择器的功能,比如帮助一个pod去查询访问另外一个pod的label对应的真实IP地址。而sevice网络在kubernetes1.11.x版本之前默认使用iptable实现的,在kubernetes 1.11.x版本之后引入了ipvs实现。
各个pod之间的通信过程概要:
每个pod都有被动态分配的IP地址,如果想要和另外一个pod进行通信,各个pod需要先和service网络进行通信,最终拿到另一个想要访问pod的动态IP地址进行通信。
六.部署Kubernetes集群环境说明
部署Kubernetes集群如果是学习环境就可以部署一个测试环境,如果生产环境就得对节点做一个具体的规划。
测试环境:
使用单Kubernetes Master节点,单etcd实例;
Kubernetes Node主机数量按需而定;
nfs或者glusterfs等存储系统;
生产环境:
高可用etcd集群,建立3,5或7个节点;
高可用Kubernetes Master:
Kubernetes API Server无状态,可多实例:
借助于keepalived进行vip流动实现多实例冗余;
或在多实例前端通过HAProxy或Nginx反向代理,并借助于keepalived对代理服务器进行冗余;
Kubernetes Schedluer及Kubernetes Controller Manager各自只能有一个活动实例,但可以有多个备用:
各自自带leader选举的功能,并且默认处于启用状态;
多Kubernetes Node主机,数量越多,冗余能力越强;
ceph,glusterfs,iSCSI,FC SAN及各种云存储等;
七.部署Kubernetes集群工具
常用的部署环境:
IaaS公有云环境,AWS,GCE,Azure等;
IaaS私有云或公有云环境:OpenStack和VSphere等;
裸机(Baremetal)环境:物理服务器或者独立的虚拟机等;
常用的部署工具:
kubeadm(由SIG小组研发的部署工具,可以说是K8S官方提供的部署工具)
kops(主要是AWS环境中使用,对于咱们国家使用相对较少)
kubespray(是利用ansible进行部署的工具,由Google公司研发)
Kontena Pharos
其它二次封装的常用发行版本:
Rancher(由Rancher labs公司发布)
Tectonic(CoreOS公司发布的)
Openshift(Redhat公司基于ansible工具对k8s进行二次封装的发行版本)
温馨提示:
Kubernetes的部署相对于Linux内核部署要简单的多,因此生产环境中我们用的Linux基本上都是二次发行版本,如RedHat,CentOS,Ubuntu,Suse等,但就目前而言,使用原生的Kubernetes相对较多。
而且二次发行版以红帽公司开发的Openshift为例,把原生的Kubernetes的一些专业术语进行了大批量更名,因此可能会让刚学完原生Kubernetes的同学有些抵触。感兴趣的小伙伴可以去研究一下Openshift,它在k8s的基础之上还增加一些自己的工具。
我的博客笔记主要介绍Kubernetes官方提供的kubeadm部署工具及使用ansible部署原生Kubernetes。
八.使用kubeadm部署k8s集群
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/12257108.html
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/10915293.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
