

HQL基本语法及应用案例
HQL基本语法及应用案例
摘自:《大数据技术体系详解:原理、架构与实践》
一.HQL基本语法
HQL是Hive提供的数据查询语言,由于Hive巨大的影响力,HQL已被越来越多的Hive On Hadoop系统所支持和兼容。HQL语法非常类似于SQL,目前包括以下几类语句:
(1)DDL(Data Definition Language,数据定义语言)
DDL主要涉及元数据的创建,删除及修改。Hive中元数据包括数据库,数据表,视图,索引,函数,用户角色和权限等,具体包括:
数据库相关的DDL :CREATE/DROP/ALTER/USE Database
数据表相关的DDL :CREATE/DROP/TRUNCATE TABLE
表/分区/列相关的DDL :ALTER TABLE/PARTITION/COLUMN
索引相关的DDL :CREATE/DROP/ALTER INDEX
视图相关的DDL :CREATE/DROP/ALTER VIRW
函数相关的DDL :CREATE/DROP/ALTER
角色和权限相关的DDL :CREATE/DROP/GRANT/REVOKE ROLES AND PRIVILEGES
HQL的DDL语句的语法跟标准的SQL语法非常相似,为了简单起见,咱们主要介绍数据表的创建,删除和修改。
(2)DML(Data Manipulation Language,数据操作语言)
DML定义了数据操作语句,包括:
数据控制语句,包括LOAD,INSERT,UPDATE和DELETE四类语句。
数据检索语句,包括SELECT查询语句,窗口和分析函数等。
存储过程,HIVE存储过程的实现源自于开源项目HPL/SQL。HPL/SQL项目的目标是为Hive,Spark SQL和Impala等SQL On Hadoop项目实现存储过程。
HQL中的DML语句的语法跟标准SQL语法非常类似,我们主要介绍数据加载和SELECT查询语句。
(3)锁
Hive提供读写锁以避免数据访问一致性问题。
1>.HQL初体验
某网站每天产生大量用户访问日志,为简化分析,假设每条访问日志由六个字段构成:访问时间,所在国家,用户编号,用户访问的网页链接,客户端上次请求的链接以及客户端IP,数据格式如下所示(每个字段用","分隔):
1999/01/11 10:12,us,927,www.yahoo.com/clq,www.yahoo.com/jxq,948.323.252.617
1999/01/12 10:12,de,856,www.google.com/g4,www.google.com/uypu,416.358.537.539
1999/01/12 10:12,se,254,www.google.com/f5,www.yahoo.com/soeos,564.746.582.215
1999/01/12 10:12,de,465,www.google.com/h5,www.yahoo.com/agvne,685.631.592.264
1999/01/12 10:12,de,856,www.yinzhengjie.org.cn/g4,www.google.com/uypu,416.358.537.539
......
请问,如何用Hive构建数据表并使用HQL分析这些访问日志(比如在某一时间段的浏览次数)?
 [root@storage111 yinzhengjie]# cat PageViewData.csv #查看本地文件日志,为了测试我就随机写了条数据
[root@storage111 yinzhengjie]# cat PageViewData.csv #查看本地文件日志,为了测试我就随机写了条数据

[root@storage111 yinzhengjie]# hdfs dfs -ls /tmp/
Found 5 items
d--------- - hdfs supergroup 0 2019-05-20 10:48 /tmp/.cloudera_health_monitoring_canary_files
drwxr-xr-x - yarn supergroup 0 2018-10-19 15:00 /tmp/hadoop-yarn
drwx-wx-wx - root supergroup 0 2019-04-29 14:27 /tmp/hive
drwxrwxrwt - mapred hadoop 0 2019-02-26 16:46 /tmp/logs
drwxr-xr-x - mapred supergroup 0 2018-10-25 12:11 /tmp/mapred
[root@storage111 yinzhengjie]#
[root@storage111 yinzhengjie]#
[root@storage111 yinzhengjie]# ll
total 4
-rw-r--r-- 1 root root 1584 May 20 10:42 PageViewData.csv
[root@storage111 yinzhengjie]#
[root@storage111 yinzhengjie]# hdfs dfs -put PageViewData.csv /tmp/
[root@storage111 yinzhengjie]#
[root@storage111 yinzhengjie]# hdfs dfs -ls /tmp/
Found 6 items
d--------- - hdfs supergroup 0 2019-05-20 10:48 /tmp/.cloudera_health_monitoring_canary_files
-rw-r--r-- 3 root supergroup 1584 2019-05-20 10:49 /tmp/PageViewData.csv
drwxr-xr-x - yarn supergroup 0 2018-10-19 15:00 /tmp/hadoop-yarn
drwx-wx-wx - root supergroup 0 2019-04-29 14:27 /tmp/hive
drwxrwxrwt - mapred hadoop 0 2019-02-26 16:46 /tmp/logs
drwxr-xr-x - mapred supergroup 0 2018-10-25 12:11 /tmp/mapred
[root@storage111 yinzhengjie]#
[root@storage111 yinzhengjie]#
使用HIVE解决该问题可分为三个阶段:
阶段1:创建数据表page_view,以保证结构化用户访问日志:
hive> CREATE TABLE page_view(
> view_time String,
> country String,
> userid String,
> page_url String,
> referrer_url String,
> ip String)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED by '\n'
> STORED AS TEXTFILE;
OK
Time taken: 0.617 seconds
hive>
创建Hive数据表时,需显式指定数据存储格式,在以上示例中,TEXTFILE表示文本文件,“,”表示每列分隔符为逗号,而“\n”表示分隔符。
阶段2:加载数据。
使用LOAD语句将HDFS上的指定目录或文件加载到数据表page_view中:
hive> LOAD DATA INPATH "/tmp/PageViewData.csv" INTO TABLE page_view;
Loading data to table test.page_view
Table test.page_view stats: [numFiles=1, totalSize=1584]
OK
Time taken: 0.71 seconds
hive>
阶段3:使用HQL查询数据。
使用类SQL语言生成统计报表,比如“统计某个时间点后来自每个国家的总体访问次数。”
hive> SELECT country,count(userid) FROM page_view WHERE view_time > "1990/01/12 10:12" GROUP BY country;
hive> SELECT country,count(userid) FROM page_view WHERE view_time > "1990/01/12 10:12" GROUP BY country; Query ID = root_20190520105454_352faf00-c601-4146-be07-14f7db34e311 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1552552068924_7036, Tracking URL = http://storage101.aggrx:8088/proxy/application_1552552068924_7036/ Kill Command = /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop/bin/hadoop job -kill job_1552552068924_7036 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-05-20 10:55:11,599 Stage-1 map = 0%, reduce = 0% 2019-05-20 10:55:21,001 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.83 sec 2019-05-20 10:55:27,300 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.49 sec MapReduce Total cumulative CPU time: 7 seconds 490 msec Ended Job = job_1552552068924_7036 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.49 sec HDFS Read: 10512 HDFS Write: 21 SUCCESS Total MapReduce CPU Time Spent: 7 seconds 490 msec OK cn 1 de 11 se 4 us 4 Time taken: 30.736 seconds, Fetched: 4 row(s) hive>
2>.数据表的创建,删除和修改
不同于关系型数据库中的数据表,Hive具有以下特点:
(1)元数据和数据是分离的,元信息保存在Metastore中,数据则保存在分布式文件系统中。
(2)自定义文件格式,Hive中存储数据的文件格式是用户自定义的,目前支持文本文件,Sequence File,Avro,ORC和Parquet等数据格式。
(3)运行时数据合法性检查,关系型数据库中的数据是插入时进行合法性检查的,而Hive中的数据则是(HQL翻译成的)分布式应用程序运行时进行数据合法性检查的。
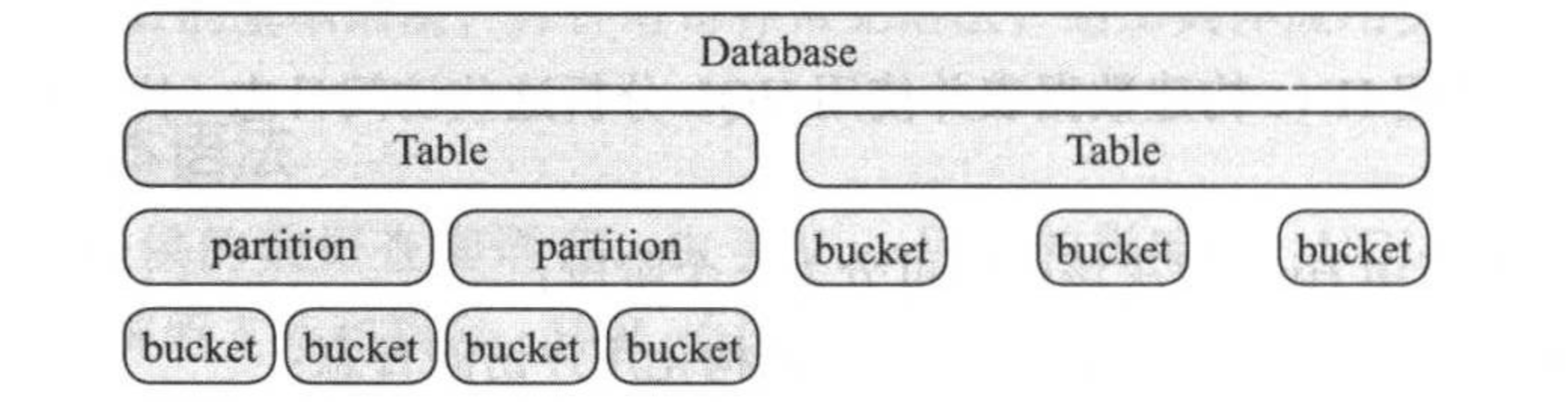
(1)Hive数据表的创建
Hive数据表是多层级的,如上图所示,Hive中可以有多个数据库,每个数据库中可以存在多个数据表,每个数据表可进一步划分为多个分区或者数据桶,每个分区内部也可以有多个数据桶。
Hive创建表的语法定义如下(经简化):
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(cole_name data_type [COMMENT col_comment],...)]
[PARTITIONED BY (col_name data_type [COMMENT col_comment],...)]
[CLUSTERED BY (col_name,col_name,...) INTO num_buckets BUCKETS]
[
[ROW FORMAT row_format]
[STORED AS file_format]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (perperty_name=property_value,...)]
[AS select_statement];
接下来,按照数据表语法定义顺序,依次解析各个关键字的含义:
1)数据表的类别。Hive数据表分为三类:临时表(TEMPORARY TABLE),外部表(EXTERNAL TABLE)和受管理表(MANAGED TABLE),其分区如下:
临时表 : 仅对当前session可见,一旦session退出,该数据表将自动被删除。
外部表 : 外部表的数据存储路径是用户定义的而非Hive默认存储位置,外部表被删除后,其对应的数据不会被清除(仅删除元数据)。
受管理表 : 默认是数据表的类型,这种表的数据是受Hive管理的,与元数据的生命周期是一致的。
2)数据类型(data_type)。Hive提供了丰富的数据类型,它不仅提供类似于关系型数据库中的基本数据类型,也提供了对高级数据类型(包括数据,映射表,结构体和联合体)的支持,具体包括:
基本数据类型 : TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,DOUBLE PRECISON,STRING,BINARY,TIMESTAMP,DECIMAL,DATA,VARCHAR和CHAR的美好。
数组(array) : 类似于Java中的映射表,由Key/value映射对组成的集合,key是value的索引。
结构体(struct): 类似于C语言中的结构体,由一系列具有想用类型或不同类型的数据构成的数据集合。
联合体(union) : 类似于C语言中的联合体,与结构体类似,但它将几种相同或不同类型的变量存放到同一段内存单元中。
3)分区表和分桶表。为了加速数据处理,数据表可进一步划分成更小的存储单位,即分区或分桶。
分区表 : 数据表可以按照某一个或几个字段进一步划分成多个数据分区(使用语句“PARTITIONED BY col_name”),不同分区的数据将被存放在不同目录中。这样,当一个查询语句只需要用到里面的若干个分区时,其他分区则可直接跳过扫描,大大节省了不必要的磁盘IO。
分桶表 : 数据表或数据分区可进一步按照某个字段分成若干个桶,比如语句“CLUSTERED BY(userid)INTO 32 BUCKETS"可讲数据按照userid这一字段分成32个桶,实际是按照公式"hash_function(bucketing_column) mod num_buckets"计算得到具体桶编号的,其中hash_function与具体的数据类型有关。分桶表对倾斜数据表(某一列或几列中某些数据值出现次数非常多)分析,数据采样和多表链接(尤其是map side join)等场景有特殊优化。
4)行格式(row format)。该配置用于指定每行的数据格式,仅对行式存储格式有意义,其语法如下:
DELIMITED [FIELDS TEMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value,...)]
在创建数据表时,DELIMITED和SERDE两种配置最多设置一个(可以不设置)。几个关键字含义如下:
FIELDS TERMINATED BY char : 每行中不同字段的分隔符char。
COLLECTION ITEMS TERMINATED BY char : map,sturct或array中每个元素之间的分隔符char。
MAP KEYS TERMINATED BY char : map中key和value之间的分隔符char。
LINES TERMINATED BY char : 行分隔符char。
举个例子,我们创建一个person的数据表,由name(姓名)和score(课程成绩)两个字段构成,其中source数据类型为map,key为课程名,value是得分。
CREATE TABLE person(name STRING,score map<STRING,INT>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
对应的数据存储方式为:
Tom 'Math':80,'Chinese':90,'English':95
Bob 'Chinese':60,'Math':80,'English':99
SERDE关键字允许用户通过定制化和反序列化规定数据存储格式,比如:JSON格式和CSV格式。
5)数据格式(file format)。HIVE支持多种数据存储格式,包括:
TEXTFILE : 文本文件,这是默认文件存储格式,用户可通过"hive.default.fileformat"修改默认值,可选值为:TextFILE,SequenceFile,RCfile或ORC。
SEQUENCEFILE : 二进制存储格式SequenceFile;
RCFILE : 列式存储格式;
ORC : 优化的列式存储格式;
PARQUET : 列式存储格式;
AVRO : 带数据模式的存储格式;
INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname :通过自定义InputFormat和OutputFormat两个组件定义数据格式。
6)数据存放位置(HDFS path)。每个数据表对应的数据将被存在一个单独目录中,具体由参数"hive.metastore.warehouse.dir"指定,默认是"/usr/hive/warehouse/<databasename>.db/<tablenae>/,"比如数据库school中的表student存放路径则为:"/user/hive/warehouse/school.db/student/"中。
7)表属性。Hive允许用户为数据表增加任意表属性,每个表属性以“key/value”的形式存在,Hive也预定了一些表属性,比如:
TBLPROPERTIES("hbase.table.name"="table_name") : 用于Hive与HBase集成,表示该Hive表对应的HBase表的table_name;
TBLPROPERTIES("orc.compress"="ZLIB") : 用于标注ORC表的压缩格式,ZLIB为压缩算法。
(2)Hive数据表的删除于修改
Hive提供了两种删除数据表的语法:
DROP TABLE,语法如下:
DROP TABLE [IF EXISTS] table_name [PUTCE];
删除指定数据表的数据和元信息,其中数据将被移动到垃圾箱,除非设置了“PURGE”标志,则跳过垃圾箱直接永久清除。需要注意的是,如果指定了数据表是外表,则仅会清理元信息。
TRUNCATE TABLE,语法如下:
TRUNCATE TABLE table_name [PATTITION partition_spec];
数据指定数据表的全部数据或某个分区,默认情况下,删除的数据将被移动到垃圾箱。
3>. 数据的查询语句
HQL数据查询语句的语法和标准SQL非常类似,具体如下:
[WITH CommonTableExpression (,CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr,select_expr,...
FROM table_eference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
接下来说明几处与标准SQL不同之处:
(1)WHIH CommonTableExpression (,CommonTableExpresson):Hive提供了一种将子查询作为一个数据表的语法,叫做Common Table Expression(CTE),比如从表t中选出两种类型的数据,并合并在一起为输出:
with t1 as (select * from t where key = '5'),
t2 as (select * from t where key = '4')
select * from t1 union all select * from t2;
(2)ORDER BY 和SORT BY:ORDER BY和SORT BY两个语句均是数据表和数据按照指定的排序键进行排序,但排序方式稍有不同,具体需从底层计算引擎MapReduce角度理解。ORDER BY用于全局排序,就是对指定的所有排序键进行全局排序,使用ORDER BY的查询语句,最后会有一个Reduce Task来完成全局排序(即只会启动一个Reduce Task);SORT By用于分区内排序,即每个Reduce任务内部排序(即最终启动多个Reduce Task并行排序)。
(3)DISTRIBUTE BY 和CLUSTER BY:DISTRIBUTE BY语句能按照指定的字段或表达式对数据进行划分,输出到对应的Reduce Task或者文件中。CLUSTER BY等价于DISTERIBUTE BY与SORT BY组合,比如以下两条HQL语句等价。
SELECT col1,col2 FROM t1 CLUSTER BY col1;
SELECT col1,col2 FROM t1 DISTRIBUTE BY coll SORT BY coll;
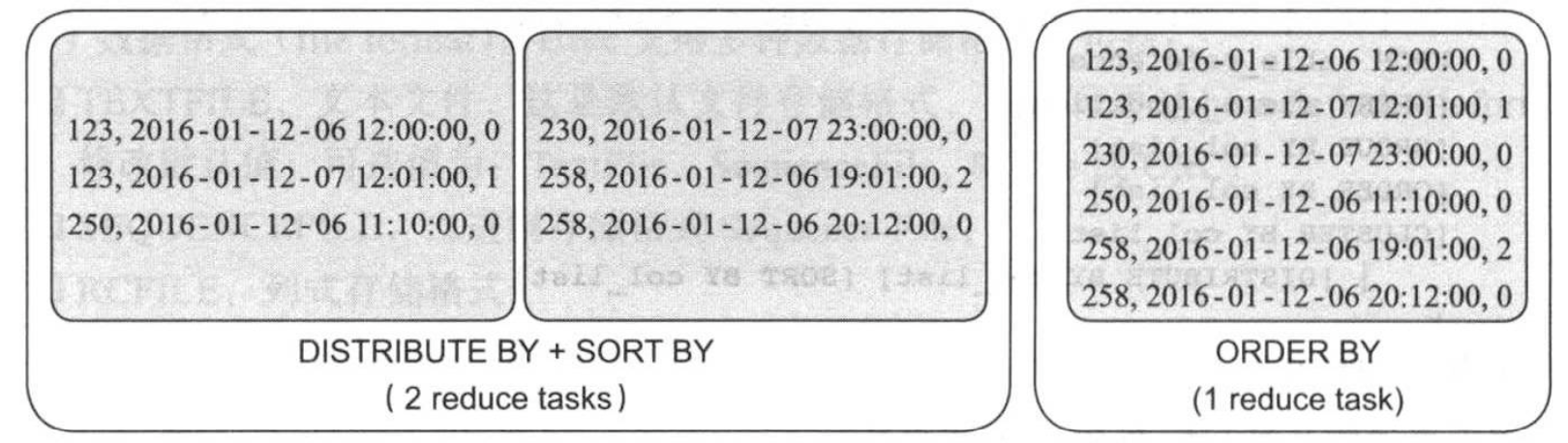
当数据量特别大,需要对最终结果进行排序时,建议采用DISTRIBUTE BY结合SORT BY语句,比如统计每个url对应的用户行为日志,并按照时间结果排序,如果采用DISTRIBUTE + SORT BY方式,HQL语句如下:
set mapreduce.job.reduces=2 #设置reduce task数目为1
SELECT url_id,log_time,log_type FROM behavior DISTRIBUTE BY url_id SORT BY user_id,log_time;
如果采用“ORDER BY”,HQL语句如下:
SELECT url_id,log_time,log_type FORM behavior ORDER BY user_id,log_time;
以上两种方式最终结果如下图所示:
二.HQL应用案例
为了方便大家更系统的了解HQL的使用方式,这里将给出一个综合案例-汪涵的用户访问日志分析系统。背景如下:某个网站每天产生大量用户访问行为数据,这些行为数据包含的字段与我们前面描述的一直,如何使用Hive构建一个数据仓库洗,能够从国家和时间(天,月和年为时间粒度)两个纬度产生网站的pv,uv等报表数据。
为了提高数据处理效率,我们采用了分区表和列式存储两种优化技巧:
分区表:以国家和时间(以天为单位)两个纬度创建分区表,这样,当统计某个国家或时间端内数据时,只需要扫描对应分区中的数据(忽略索引),大大提高性能。
列式存储:考虑到绝大部分情况下,HQL语句只会用到若干列数据,为了避免不必要的磁盘IO,我们采用列式存储格式存储数据,比如ORC或Parquet。
构建用户访问日志分析系统的主要流程如下图所示:

(1)ETL(Extract Transform Load)。用户描述将数据从来源端经过抽取(extract),转化(transform),加载(load)至目的端的过程。其中抽取主要功能是从原始文本解析处需要的数据,并对不合要求的数据进行清洗和转换,包括: 不符合要求的数据是完整的数据,错误的数据,重复的数据。 不一致的数据,数据粒度的转换,以及一些商务规划的计算。 在实例中,原始日志数据经抽取和转换(可选用Python语言,使用Hadoop Streaming实现)后,变为以下结构化数据: 1999/01/12 10:12,se,254,www.google.com/f5,www.yahoo.com/soeos,564.746.582.215 1999/01/12 10:12,de,465,www.google.com/h5,www.yahoo.com/agvne,685.631.592.264 ...... 之后加载到数据表page_view中,该数据表的创建方式我们上面以及做过介绍了,这里不再赘述。 每天产生的原始数据行为数据经ETL后,以"PageViewData_<date>.csv"(<date>表示当前的日期)命名方式存到/tmp目录下,并通过以下DML语句加载到数据表page_view(以文本文件作为的存储格式)中: LOAD DATA INPATH "/tem/PageViewData_19990112.csv" INTO TABLE page_view; (2)创建ORC分区表,并加载数据。为了加快数据处理速度,我们以国家和和时间(以天为单位)两个度量创建ORC分区表orc_page_view,对应的DDL语句如下所示: hive> CREATE TABLE orc_page_view( > view_time STRING, > userid STRING, > page_url STRING, > referrer_url STRING, > ip STRING) > PARTITIONED BY (vd STRING,country STRING) > STORED AS ORC; OK Time taken: 0.144 seconds hive> 由于分区字段vd(View Data)和country会出现在数据存放的目录中,所以无需在放在数据表对应的字段列表中。 创建完ORC分区表后,采用以下DDL语句将page_view表中的数据加载到新表orc_page_view中,数据是1999年1月15日产生的来自四个国家(us:美国,de:德国)的用户访问日志: hive> FROM page_view pv > INSERT OVERWRITE TABLE orc_page_view > PARTITION (vd = '19990115', country = 'us') > SELECT view_time,userid,page_url,referrer_url,ip WHERE pv.view_time LIKE '1999/01/15%' AND pv.country = 'us' > INSERT OVERWRITE TABLE orc_page_view > PARTITION (vd = '19990115', country = 'de') > SELECT view_time,userid,page_url,referrer_url,ip WHERE pv.view_time LIKE '1999/01/15%' AND pv.country = 'de';
(3)数据查询。使用HQL产生1999年1月15日的报表:
SELECT country,count(userid) FROM page_view WHERE view_time = "19990115" GROUP BY country;
用户可讲HQL产生的结果写入MySQL数据库,以便前段可视化展示。
以上三个步骤是不断迭代进行的,将每天的数据存入ORC分区表orc_page_view中,进而可以获取某一段时间的统计报表。
hive> FROM page_view pv
> INSERT OVERWRITE TABLE orc_page_view
> PARTITION (vd = '19990115', country = 'us')
> SELECT view_time,userid,page_url,referrer_url,ip WHERE pv.view_time LIKE '1999/01/15%' AND pv.country = 'us'
> INSERT OVERWRITE TABLE orc_page_view
> PARTITION (vd = '19990115', country = 'de')
> SELECT view_time,userid,page_url,referrer_url,ip WHERE pv.view_time LIKE '1999/01/15%' AND pv.country = 'de';
Query ID = root_20190520145050_bc6612ae-b276-4455-8784-d24d59e3b584
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1552552068924_7045, Tracking URL = http://storage101.aggrx:8088/proxy/application_1552552068924_7045/
Kill Command = /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop/bin/hadoop job -kill job_1552552068924_7045
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 0
2019-05-20 14:50:48,769 Stage-2 map = 0%, reduce = 0%
2019-05-20 14:50:55,115 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 4.56 sec
MapReduce Total cumulative CPU time: 4 seconds 560 msec
Ended Job = job_1552552068924_7045
Stage-5 is selected by condition resolver.
Stage-4 is filtered out by condition resolver.
Stage-6 is filtered out by condition resolver.
Stage-11 is selected by condition resolver.
Stage-10 is filtered out by condition resolver.
Stage-12 is filtered out by condition resolver.
Moving data to: hdfs://storage-ha/user/hive/warehouse/test.db/orc_page_view/vd=19990115/country=us/.hive-staging_hive_2019-05-20_14-50-35_046_58667942699678678-1/-ext-10000
Moving data to: hdfs://storage-ha/user/hive/warehouse/test.db/orc_page_view/vd=19990115/country=de/.hive-staging_hive_2019-05-20_14-50-35_046_58667942699678678-1/-ext-10002
Loading data to table test.orc_page_view partition (vd=19990115, country=us)
Loading data to table test.orc_page_view partition (vd=19990115, country=de)
Partition test.orc_page_view{vd=19990115, country=us} stats: [numFiles=1, numRows=1, totalSize=733, rawDataSize=488]
Partition test.orc_page_view{vd=19990115, country=de} stats: [numFiles=1, numRows=5, totalSize=1035, rawDataSize=2465]
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Cumulative CPU: 4.56 sec HDFS Read: 8269 HDFS Write: 1965 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 560 msec
OK
Time taken: 23.25 seconds
hive>
hive> SELECT country,count(userid) FROM page_view WHERE view_time = "19990115" GROUP BY country; Query ID = root_20190520145959_a5af9c6d-1704-4494-bbb1-22d020badc36 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1552552068924_7048, Tracking URL = http://storage101.aggrx:8088/proxy/application_1552552068924_7048/ Kill Command = /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop/bin/hadoop job -kill job_1552552068924_7048 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-05-20 14:59:59,869 Stage-1 map = 0%, reduce = 0% 2019-05-20 15:00:07,174 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.41 sec 2019-05-20 15:00:16,563 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.87 sec MapReduce Total cumulative CPU time: 7 seconds 870 msec Ended Job = job_1552552068924_7048 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.87 sec HDFS Read: 10803 HDFS Write: 0 SUCCESS Total MapReduce CPU Time Spent: 7 seconds 870 msec OK Time taken: 38.087 seconds hive>
博主推荐阅读:Hive快速入门篇之HQL的基础语法(https://www.cnblogs.com/yinzhengjie/p/9154339.html)。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/10847527.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
