
批处理引擎MapReduce应用案例
批处理引擎MapReduce应用案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
MapReduce能够解决的问题有一个共同特点:任务可以被分解为多个子问题,且这些子问题相对独立,彼此之间不会有牵制,待并行处理完成这些子问题后,总的问题便被解决。
在实际应用中,这类问题非常庞大,谷歌在论文中提到一些MapReduce的典型应用,包括分布式grep,URL访问频率统计,Web链接图反转,倒排索引构建,分布式排序等,这些均为比较简单的应用。下面介绍一些比较复杂应用。
一.Top K问题
在搜索引擎领域中,常常需要统计最近最热门的K个查询词,这就是典型的“Top K”问题,也就是从海量查询中统计出现频率最高的前K个。
该问题可分解成两个MapReduce作业,分别完成统计词频和找出词频最高的前K个查询词的的功能,另两个作业存在以来关系,第二个作业需要依赖前一个作业输出的结果。第一个作业是典型的WorldCount问题。对于第二个作业,首先map函数输出前K个频率最高的词,然后在reduce函数中汇总每个Map任务得到的前K个查询词,并输出频率最高的前K个查询只。
二.K-means聚类
K-means是一种基于距离的聚类算法,它采用距离作为相似性的评价指标,认为两个对象的距离越近,其相似度就越大,该算法解决的问题可抽象成:给定正整数k和n个对象,如何将这些数据点划分为k个聚类?
该问题采用MapReduce计算思路如下,首先随机选择k个对象作为初始中心点,然后不断迭代计算,直到满足终止条件(达到迭代次数上限或者数据点到中心点距离平方和最小),在第i轮迭代中,map函数计算每个对象到中心点的距离,选择距每个对象(object)最近的中心点(center_point),并输出<center_point,object>对。reduce函数计算每个聚类中对象的距离均值,并将这k个均值作为下一轮初始中心点。
三.贝叶斯分类
贝叶斯分类是一种利用概率统计知识进行分裂的统计学分方法。该方法包括两个步骤:训练样本和分类。 其实现由多个MapReduce作业完成,具体如下图所示。
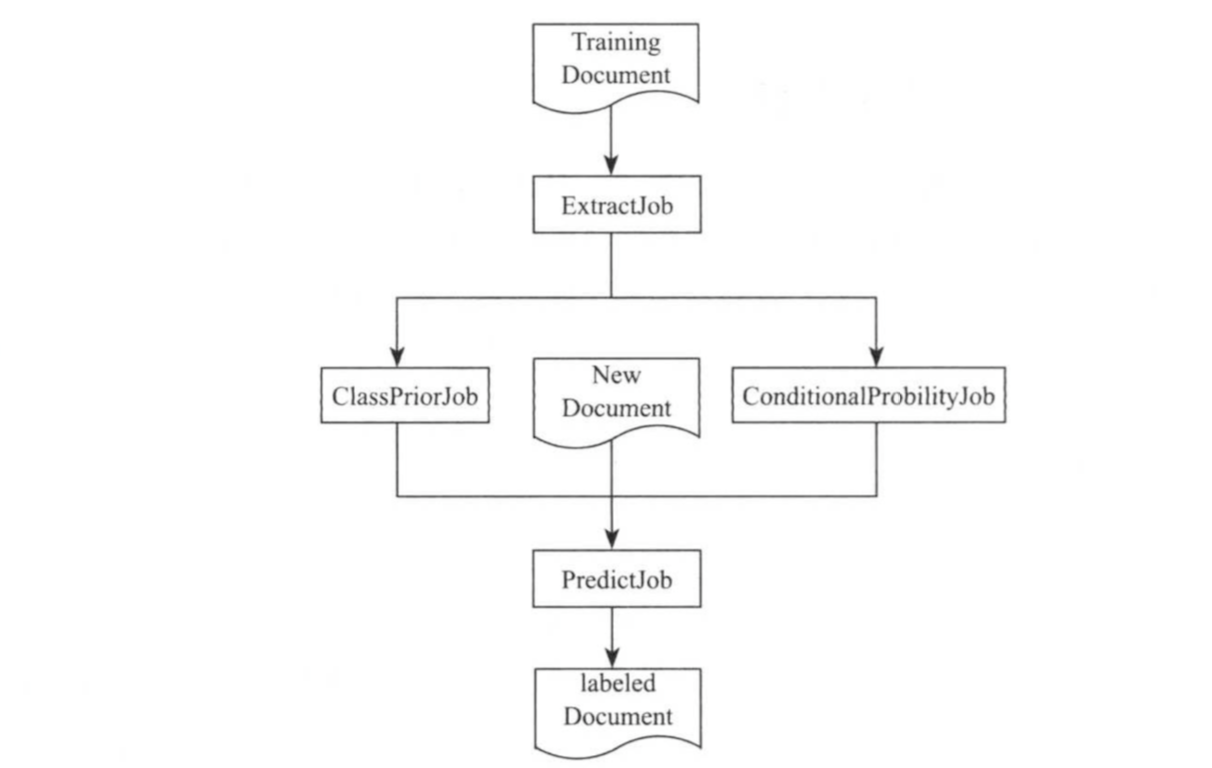
其中,训练样本可由三个MapReduce作业完成: (1)第一个作业(ExtractJob)抽取文档特征,该作业只需要Map即可完成; (2)第二个作业(ClassPriorJob)计算类别的先验概率,即统计每个类别中文档的数目,并计算类别概率; (3)第三个作业(CondititionProbilityJob)计算单词的条件概率,即统计<label,word>在所有文档中出现的次数并计算单词的条件概率; 后两个作业的具体实现类似于WordCount。分类过程有一个作业(PredictJob)完成,该作业的map函数计算每个待分类文档属于每个类别的概率,reduce函数找到每个文档概率最高的类别,并输出<docid,label>(编号为docid的文档属于类别label)。
四.MapReduce不能解决或者难以解决的问题
1>.Fibonacci数值计算
Fibonacci数值计算时,下一个结果需要依赖前面的计算结果,也就是说,无法将该问题划分成若干个互不相干的子问题,因而不能够用MapReduce解决。
2>. 层次聚类法
层次聚类法是应用最广泛的聚类算法之一,按采用“自顶向下”和“自底向上”两种方式,可将其分解为分解型层次聚类法两种。层次聚类方法采用迭代控制策略,使聚类逐步优化。它按照一定的相似性(一般是距离)判断标准,合并最相似的部分或者分隔最不相似的部分。以分解型层次聚类算法为例,其主要思想是,初始时,将每个对象归为一类,然后不断迭代,直到所有对象合并成一个大类(或者达到某个终止条件),在每轮迭代时,需要计算两两对象间的距离,并合并距离最近的两个对象为一类。
该算法需要计算两两对象间的距离,也就说每个对象和其他对象均有关联,因而该问题不能被分解成若干个子问题,进而不能用MapReduce解决。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/10793758.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号