
批处理引擎MapReduce程序设计
批处理引擎MapReduce程序设计
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.MapReduce API
Hadoop同时提供了新旧两套MapReduce API,新API在就API基础上进行了封装,使得其在扩展性和易用性方面哥哥好。总结新就版本MapReduce API主要区别如下: (1)存放位置 旧版本API放在“org.apache.hadoop.mapred”包中,而新版API则放在“org.apache.hadoop.mapreduce”包及其子包中。 (2)接口类为抽象类 接口通常作为一种严格的“协议约束”,它只有方法声明但没有方法实现,且要求所有实现类(不包括抽象类)必须实现接口的每一个方法。接口的最大优点是允许一个类实现多种接口,进而实现类似C++中的“多重继承”。
抽象类则是一种比较宽松的“协议约束”,它可为某些方法提供默认实现,而继承类则可选择是否重新实现这些方法,正式因为这一点,抽象类在类衍化方面更具有优势,也就是说,抽象类具有良好的向后兼容性,当需要为抽象添加新的方法时,只要新添加的方法提供类默认实现,用户之前的代码就不必修改了。 考虑到抽象类在API衍化方面的优势,新API将InputFormat,OutputFormat,Mapper,Reducer和Partition由接口变为抽象类。 (3)上下文封装
新版本API将变量和函数封装成各种上下文(Contex)类,使得API具有更好的易用性和扩展性。首先,函数参数列表经封装后变短,使得函数更容易使用;其次,当需要修改或添加某些变量或函数时,只需要修改封装后的上下文即可,用户代码无需修改,这样保证了向后兼容性,具有良好的扩展性。
由于新版本和旧版本API在类层次结构,编程接口名称及对应的参数列表等方面存在较大差别,所以两种API不能够兼容。所以建议大家直接使用新的API进行程序开发。
二.MapReduce程序设计基础
Hadoop内核是采用Java语言开发的,提供Java API是自然而然的事情。一般而言,用户可按照以下几个步骤开发MapReduce应用程序: (1)实现Mapper,Reducer以及main函数。通过继承抽象类Mapper和Reducer实现自己的数据处理逻辑,并在main函数中创建Job,定制作业执行环境。 (2)本地调试。在本地运行应用程序,让程序读取本地数据,并写到本地,以便调试。 (3)分布式执行。将应用程序提交到Hadoop集群中,以便分布式处理HDFS中的数据。 接下来介绍介绍几个Java 程序设计实例,帮助打下理解MapReduce应用程序开发流出。
1>.构建倒排索引
倒排索引(Inverted index),也常被称为反向索引,是一种索引方法,通常用于快速全文搜索某个词语所在文档或者文档中的具体存储位置。它是文档检索系统中最常用的数据结构,也是搜索引擎中最核心大的技术之一。目前主要有两种不同的反向索引形式: (1)一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。 (2)一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。 第二种方式提供了更多的兼容性(比如短语搜索),但是需要更多的时间和空间来创建。本实力主要介绍第一种方式。
以英文为例,下面是要被索引的文本:
T0 = "I wish to wish the wish you wish to wish"
T1 = "but if you wish the wish the witch wishes"
T2 = "I won't wish the wish you wish to wish"
我们就能得到下面的反向索引:
"I" : {0,2}
"wish" : {0,1,2}
"to" : {0,2}
"the" : {0,1,2}
"you" : {0,1,2}
"but" : {1}
"if" : {1}
"witch" : {1}
"wont" : {2}
检索的条件"I","wish"和“you”将对应这个集合:{0,2} ∩ {0,1,2} ∩ {0,1,2} = {0,2}。
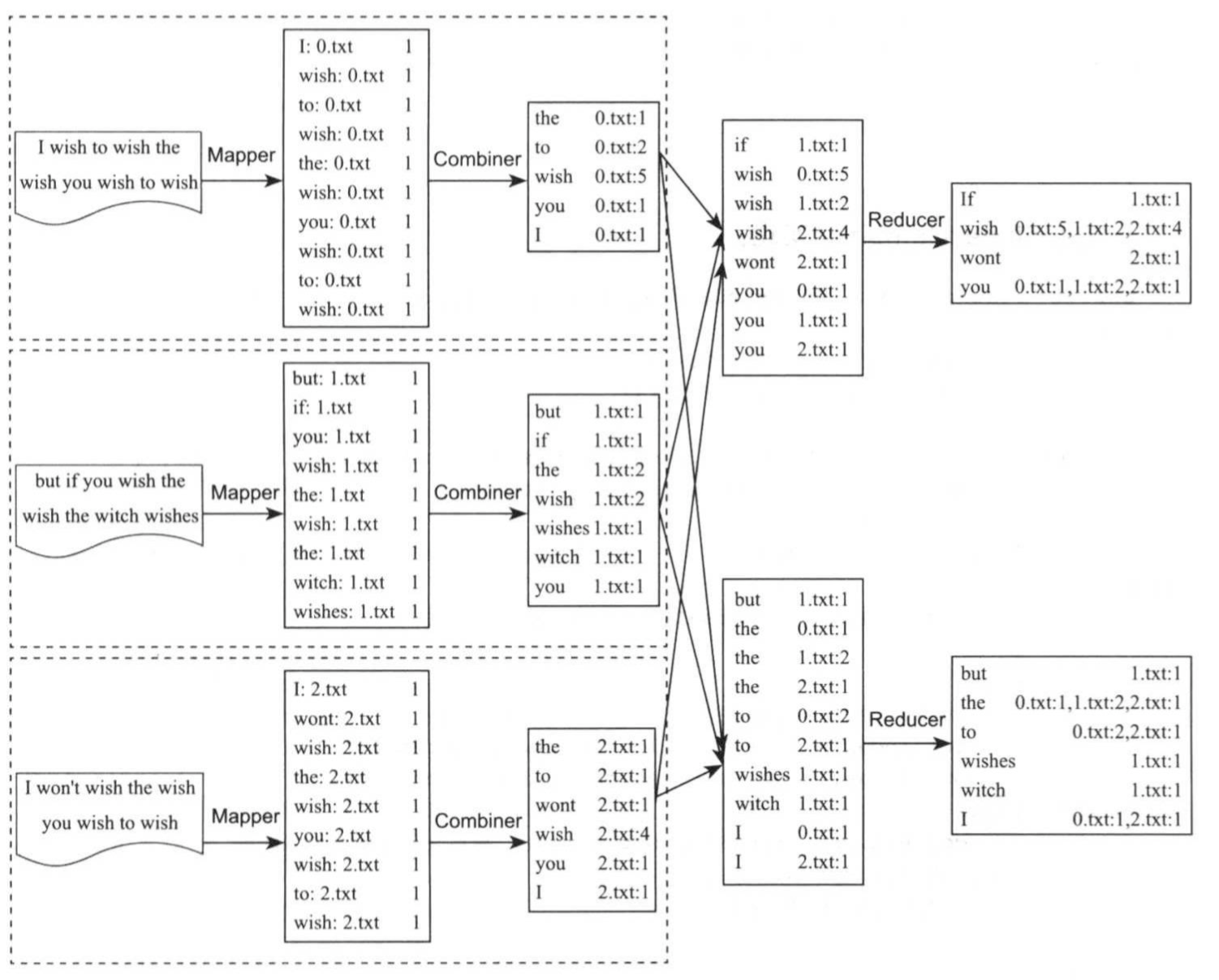
采用MapReduce实现倒排索引需实现三个基本组件:Mapper,Combiner和Reducer,如上图所示,具体如下: (1)Mapper Mapper过程分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词,文档URI和词频(作为权重),其中,单词和文档URI为输出key,词频作为value。 (2)Combiner 统计词频,输出key为单词,输出value为文档URI和词频。 (3)Reducer 将相同key值的value值组合成倒排索引文件所需的格式。
将上面过程转化成代码,则程序框架如下所示:


下面分别介绍InvertedIndexMapper,InvertedIndexCominer和InvertedIndexReducer三个内部类的实现。
InvertedIndexMapper内部类实现如下:

InvertedIndexCombiner内部类实现如下:

InvertedIndexReducer内部类实现如下:

MapReduce应用程序设计完成后,可直接在IDE中运行,此时需设置两个本地目录作为程序的输入,分别是输入数据所在目录和输出数据存放目录。
通过本地运行确认程序程序逻辑确认后,可通过“haoop jar”命令将MapReducer作业提交到hadoop集群中,同时,“-D”指定作业运行参数,包括Map Task使用内存量,Reduce Task个数等,如下所示:
hadoop jar revertedIndex.jar java.package.name.InvertedIndex -D mapreduce.map.memory.mb=4096 -D mapreduce.map.java.opts=-Xms2560M -D mapreduce.job.reduces=4 /input/data /outout/data
2>.SQL GroupBy
给定数据表order,保存了交易数据,包括交易号dealid,用户ID,交易时间以及交易金额等,定义如下: crate table order( dealid long NOT NULL, uid long NOT NULL, dealdate date NOT NUll, amount long NOT NULL ) 交易数据量比较大,为TB级别,保存在大量文本文件中,没行保存一条交易数据,不同字段通过“,”分隔,形式如下: 000001,12054,2015-01-01,1200 000002,12090,2015-01-01,2500 000003,13000,2015-01-02,800 ...... 请问,如何编写MapReduce程序得到以下SQL产生的结果: SELECT dealid,count(distinct uid) num from order group by dealid; 一种简单的方案是,在Mapper中,将dealid和uid分别作为key和value输出,在Reducer中,借助Java中的Map数据结构设计同一dealid中不同uid数目。该方法的缺点是Reducer中内存使用量是不可控的,极有可能发生内存溢出。 另一种方案是借助MapReduce的排序功能完成uid的去重,计算过程如下图所示:
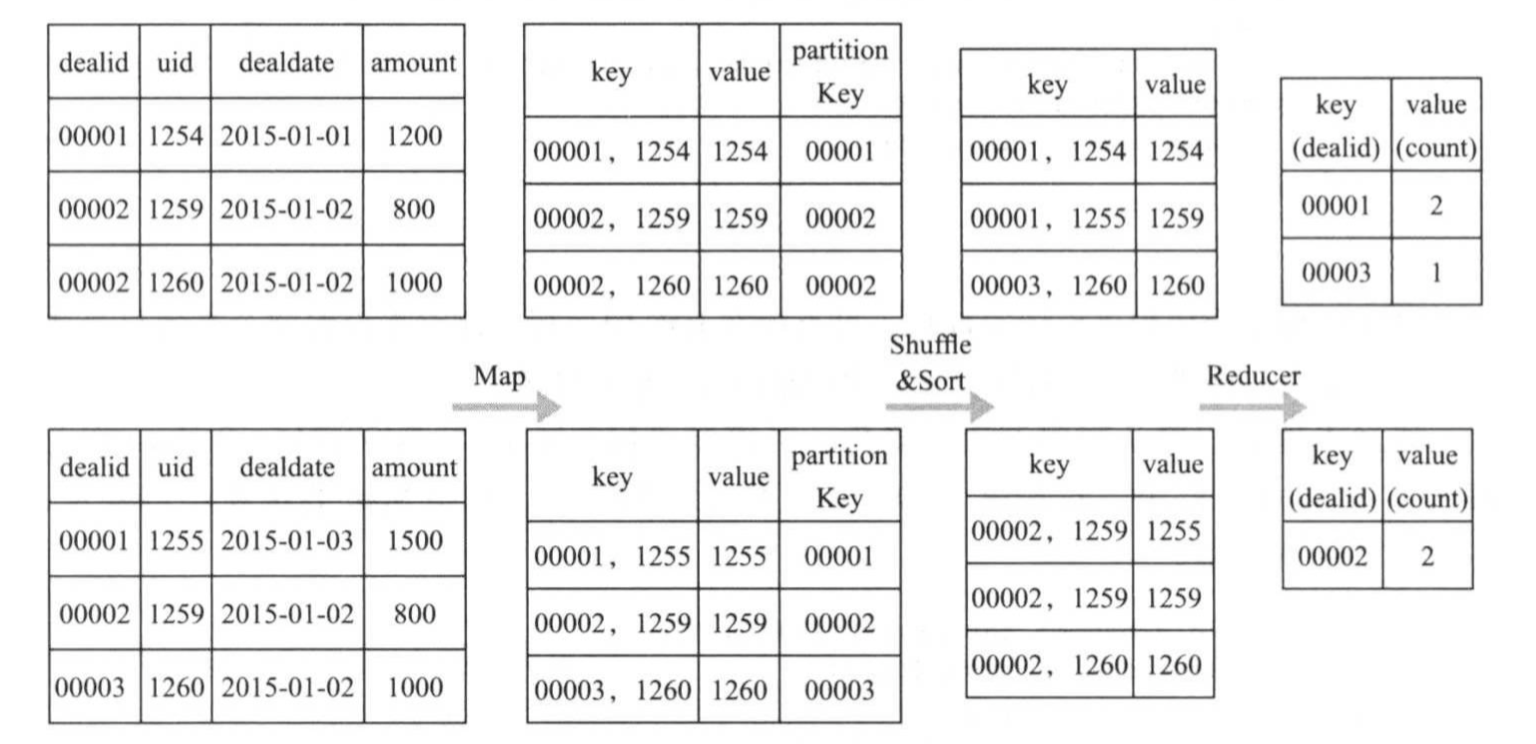
将上面过程转换成代码,则程序框架如下所示:

下面分别介绍SqlGroupByMapper,SqlGroupByPartitioner和SqlGroupByReducer三个内部类的实现。
SqlGroupByMapper内部类实现如下:

SqlGroupByPartitioner内部类实现如下:

SqlGroupByReducer内部类实现如下:

三.MapReduce程序设计进阶
MapReduce提供了很多高级功能,使用户更容易开发高效的分布式程序,这些功能包括数据压缩,多路输入/输出,组合主键以及DistributedCache等,本节将一次介绍这些功能。
1>.数据压缩


冷热数据是根据最近公司访问时间确定的,一般而言,认为最近X天内未访问过的数据为冷数据,其中X的大小视公司情况而定,比如100或者365天。可通过分析NameNode日志得到HDFS上冷数据和热数据。(这种方式是可行,但我不推荐大家使用,因为配置文件是基于XML写的,你如果一条一条去查的话,会有一种欲哭无泪的感觉)
数据压缩能够通过一定的编码技术减少数据存储空间,是一种利用CPU资源换取IO资源的优化技术,它涉及两个优化指标:压缩比和压缩/解缩效率,这两个指标是此消彼长的,一个压缩算法能够产生较大的压缩比,则压缩/解压效率则不会很高。通常根据需求来确定选择何种数据压缩算法,对于历史冷数据,通常会选用压缩比较高的算法,对于访问频率较低的非冷数据,则选用压缩比/解压效率比较折中的算法,对于访问频率较低的非冷数据,则选用压缩比与压缩/解压效率比较折中的算法,对于频率访问的热数据,则不会压缩。
对于MapReduce这种分布式程序而言,另外一个特殊的压缩算法评测指标是可分解性(splitable)。一个压缩算法具备可分解性是值该压缩算法支持级别的压缩,能够在文件内部以块形式压缩数据。采用可分解性压缩算法压缩的文件,能够被进一步划分成若干个split,被任务并行处理,典型的代表与LZO和Bzip2;另一种压缩算法仅支持文件级别的压缩,采用这种算法压缩的文件,不能进一步分解,只能被一个任务处理,典型的代表是Gzip和Snappy,比较这集中算法如下所示。
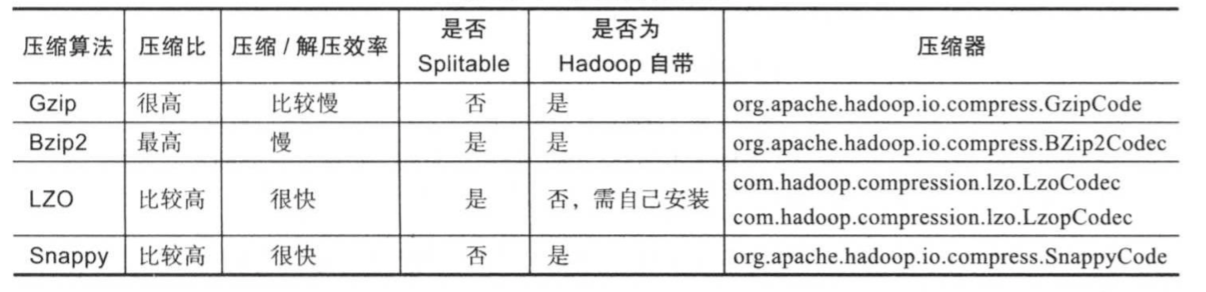
在MapReduce作业以下三个阶段可能涉及压缩/非压缩数据的读取和写入:Map输入,Map输出和Reduce输出,其中Map输出的结果为临时数据,建议通过压缩方式减少IO数据量,其他两个阶段与具体数据格式相关: (1)文本文件 如果数据采用Gzip和Snappy算法进行压缩,则文件将变得不可分解,因而一个文件只能被一个Map Task处理。 (2)SequenceFile
SequenceFile是一种内部分块的key/value文件格式,采用任意算法压缩后,文件仍可以别被划分成若干个split,并由多个Map Task并行处理。
2>.多路输入/输出
多路输入/输出是将多种存储格式或者计算逻辑放到一种MapReduce作业中完成的手段,通常用于以下两种情况: (1)作业的输入/输出中包含多种不同格式的数据源,比如既有文本文件,也有key/value格式文件。 (2)作业的多个输入数据源需要通过不同逻辑处理,并针对不同的处理逻辑,写入不同的文件。 MapReduce提供了MultipleInputs和MultipleOutputs类,允许用户设置多路输入/输出源,并制定对应的InputFormat和OutputFormat,下面分别介绍这两个类的使用方法。
MultipleInputs允许用户设置多路不同(或相同)格式的数据源,下面给出了示例代码:

用户可以在程序中国通以下方法获取当前Map Task处理的数据路径:

MultipleOutputs允许用户设置多路不同(或相同)格式的输出路径,下面给出了示例代码:

编写Mapper或Reducer可将不同类型的结果写入不同目录下,代码如下:

最终输出结果存放目录组织方式为:

3>.DistributedCache
DistributedCache是Hadoop为方便用户进行应用程序开发而设计的数据分发工具,它能够将只读的文件自动分发到各个节点上进行本地缓存,以便Task运行时家在使用。DistributedCache将文件分为三种: (1)普通文件 直接缓存到任务运行的节点,且不经过任何处理。 (2)jar包 缓存到任务运行的节点,并自动加到运行环境的CLASSPATH中。 (3)归档文件(后缀为".zip",".jar",".tar",".tgz"或者".tar.gz"的文件)
缓存到任务运行的节点,并自动解压到任务的工作目录下。
Hadoop DistributedCache提供了丰富的API方便用户分发文件,主要如下:

这些API使用示例如下:

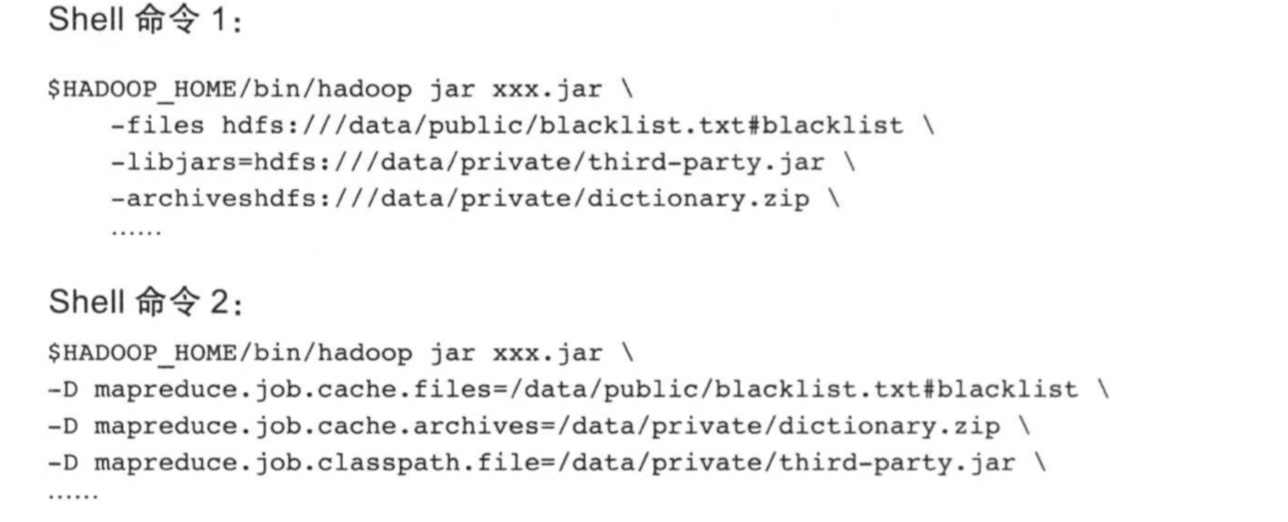
设置命令行参数是一种比较简单且灵活的方法,但前提是在程序中使用GenericOptionsParser类解析通用参数(主要包括“-files”,“-libjars”,"-archives"和“-D”)。用户提交作业是,使用通用参数指定对应类型但文件即可。
四.Hadoop Streaming(官方文档链接:http://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html)
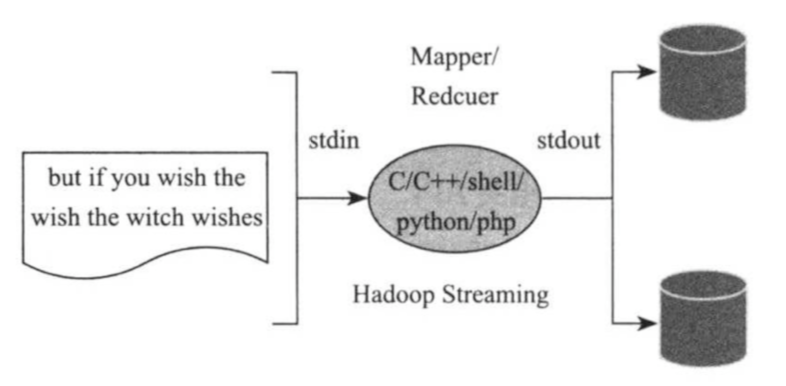
Hadoop Streaming是Hadoop为方便非Java用户编写MapReduce程序而设计但工具包,它允许用户将任何可执行文件或者脚本作为Mapper/Reducer,这大大提高程序员的开发效率。
Hadoop Streaming要求用户编写的Mapper/Reducer从标准输入中度数据,并将结果写到标准数据中,这类似于Linux中管道机制,具体如下图所示:
Hadoop Streaming是一个Java版本的MapReduce应用程序框架,它对外提供一系列可设置参数,用法如下:
hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar [genericOptions] [streamingOptions]
其中[genericOptions]为通用参数,主要包含以下四个:
-D property=value:
以<key,value>方式指定属性及其值,比如-Dmapreduce.job.queuname=test可将作业提交到队列test中。
-files:
指定要分发的普通文件,这些文件会被自动分发到任务允许的节点上,并保存到任务当前工作目录下。
-libjars:
指定要分发的jar包,这些jar包会别自动分发到任务允许的节点上,并自动加到任务运行的CLASSPATH环境变量中。
-archives:
指定要分发的归档文件,可以是“.tar.gz”,".tgz",".zip"结尾的压缩文件。
具体案例可以参考官方提供的案例:http://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html#Generic_Command_Options。
其中[streamingOptions]为Hadoop Streaming特有参数,主要有以下几个:
-input:
输入文件路径。
-output:
输出文件路径。
-mapper:
用户编写的Mapper程序,可以是可执行文件或者脚本。
-reducer:
用户编写的Reducer程序,可以是可之行文件或者脚本。
-file:
指定的文件会被自动分发到集群的各个节点上,可以是Mapper或者Reducer要用的输入文件,如配置文件,字典等。
-partitioner:
用户自定义的Partitioner程序(必须用Java实现)。
-combiner:
用户自定义的Combiner程序。
-numReduceTasks:
Reduce Task数目。
具体案例可以参考官方提供的案例:http://hadoop.apache.org/docs/stable/hadoop-streaming/HadoopStreaming.html#Streaming_Command_Options。
为了便于大家了解Hadoop Streamming使用方式,接下来为介绍几个编程实例。
1>.Hadoop Streaming编程实例
(1)C++版本WordCount 采用C++实现WordCount关键点是,在Mapper中,使用标准cin获取每行文本,经分词处理后,使用标准输出cout产生中间结果;在Reducer中,使用标准输入cin获取Mapper产生的中间结果,并统计每个词出现的频率,最后使用标准输出cout将结果写入HDFS最。 Mapper(mapper.cpp)实现的具体代码如下所示:

Reducer(reducer.cpp)实现的具体代码如下:

分别编译这两个程序,生成的可执行文件分别是wc_mapper和wc_reducer,使用以下命令提交作业:

由于Hadoop Streaming 类似于Linux管道,这使得测试变得非常容易,用户可以直接在本地使用下面的命令测试结果是否正确: cat test.txt | ./wc_mapper | sort | ./wc_reducer (2)Shell 版本WordCount 采用shell版WordCount实现思路和C++类似:使用标注输入获取数据,处理后,通过标准输出产生结果。 Mapper(mapper.sh)实现的具体代码如下:

Reducer(reducer.sh)实现的具体代码如下:

使用下面命令提交作业:

用户可直接在本地使用下面的命令测试结果是否正确: cat test.txt | sh mapper.sh | sort | reducer.sh
2>.Hadoop Streaming常用参数
Hadoop Streaming 以参数形式提供了大量功能,帮助用户简化分布式程序,主要参数如下: (1)定制化Mapper/Reducer的输入/输出key和value:
stream.map.input.field.separator :Mapper输入的key月value分隔符,默认是TAB。
stream.map.output.field.separator : Mapper输出的key与value分隔符。
stream.num.map.output.key.fields :Mapper输出key与value的划分位置。
下面这个作业制定了Mapper输出数据的分隔符为".",其中,第四个“.”之前的所有自负为key,其余字符为value,如果某一行输出数据不足四个“.”,则所有输出字符串为key,而value为空。

类似的,Reducer的输出字符串的分隔符以及key/value划分方式可通过参数stream.reduce.output.field.separator和stream.num.reduce.output.key.fields定制。
(2)利用KeyFieldBasedPartitioner定制分区方法。可结合Hadoop自带Partition实现“org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner”以及参数“mapreduce.partition.keypartitioner.options”定制化分区方法,举例如下:

在该实例中,Mapper的输出数据被“.”划分成若干个字段,其中,前四段为key(有参数stream.num.map.output.key.fields指定),前两个字段为分区字段(由参数mapreduce.partition.keypartitioner.options指定),这种配置方式想当于前两个字段作为parimary key,第三四个字段作为secondary key,其余字段作为value,这样,primary key用来分区,两者结合用来培训。
(3)定制化Reduce Task个数:可通过参数mapreduce.job.reduces定制化Reduce Task个数,如果该值设置为0,表示该MapReduce作业只有 Map Task。下面这个作业将Reduce Task数目指定为5:

3>.Hadoop Streaming实现原理分析
Hadoop Streaming工具包实际上是一个Java编写的MapReduce作业,当用户可执行文件或者脚本文件充当Mapper或者Reducer时,Java端的Mapper或者Reducer冲淡了wrapper角色,它们将输入文件的key和value直接传递给可执行文件或者脚本文件进行处理,并将处理结果写入HDFS。
实现Hadoop Streaming的关键技术点是如何用标准输出实现Java于其他可执行文件或者脚本文件之间的通信。为此,Hadoop Streaing 使用了SDK中的java.lang.ProcessBuilder类,该类提供了一套管理操作系统进程的方法,包括创建,启动,和停止进程(也就是应用程序)等。相比于JDK的Process类,ProcessBuilder允许用户对进程进行更多控制,包括设置当前工作目录,改变环境参数等。
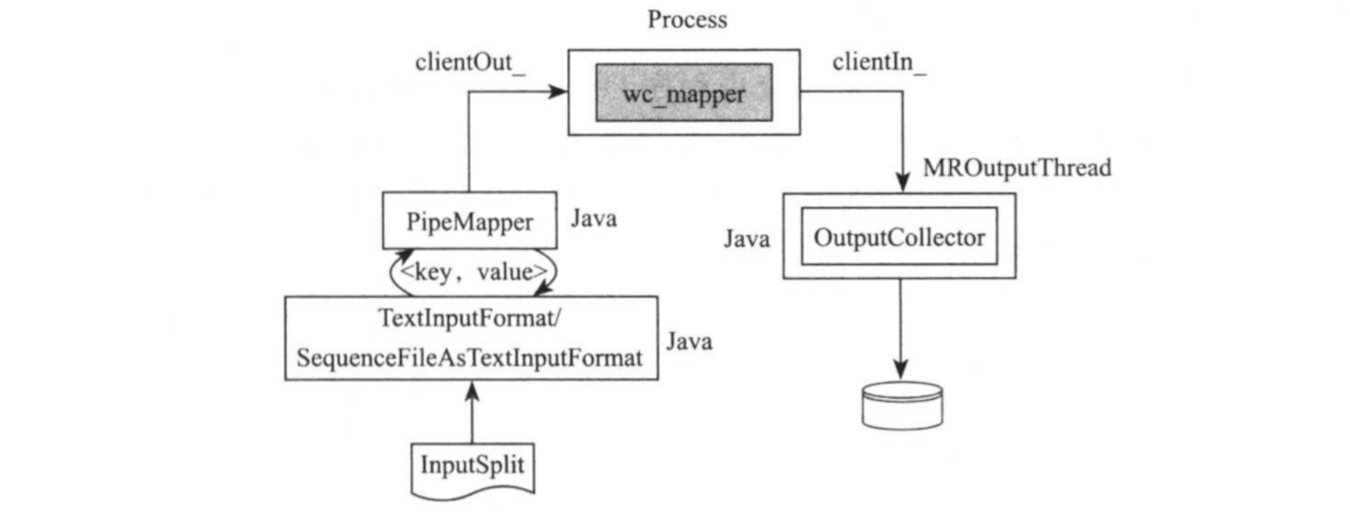
对于C++版WordCount而言,其Mapper执行过程下图所示,Hadoop Streaming使用ProcessBuilder以独立进程方式启动可之行文件wc_mapper,并创建该进程的输入输出流,以便向其传递待处理的输入数据,并捕获输出结果。
由于Hadoop Streaming使用分隔符定位一个完整的key或者value,目前只能支持文本格式的数据,不支持二进制格式。在0.21.0版本之后,Hadoop Streaming增加了对二进制文件的自持,并添加了两种新的二进制文件格式:“RawBytes”和“TypedBytes”,顾名思义,Rawbytes指key和value是原始字节序列,而TypedBytes指key和value可以拥有的数据类型,比如boolean,list,map等,由于它们采用的是长度而不是某一种分隔符定位key和value,因而支持二进制文件格式。参考链接:https://issues.apache.org/jira/browse/HADOOP-1722。
RawBytes传递给可执行文件或者脚本文件的内容编码格式为:

TypedBytes允许用户的key和value指定数据类型,对于固定长度的基本类型,如byte,bool,int,long等,其编码格式为:

对于长度不固定的类型,如byte array,String等,其编码格式为:
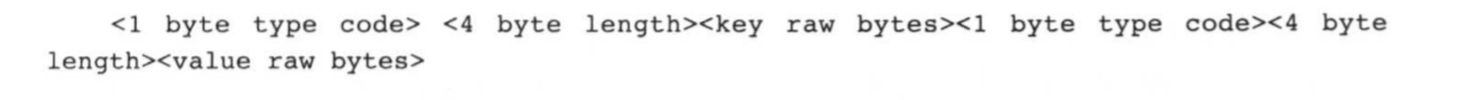
当key和value大部分情况下为固定长度的基本类型时,TypedBytes比RawBytes格式要更省空间,感兴趣的读者可以自行尝试这两种文件格式。
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/p/10780538.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号