

HDFS的配置详解和日常维护
HDFS的配置详解和日常维护
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS运维概述
HDFS的运维主要分为两方面,一方面是对文件系统的管理,这部分与linux文件系统的操作有很多相似之处,较易掌握;另一方面是对分布式进程的管理.
通过Cloudera Manager Server的Web UI去访问HDFS界面。具体操作如下:
1>.点击HDFS服务
2>.点击"Web UI",随机选择一个NameNode节点(我这里做了hdfs ha模式)。
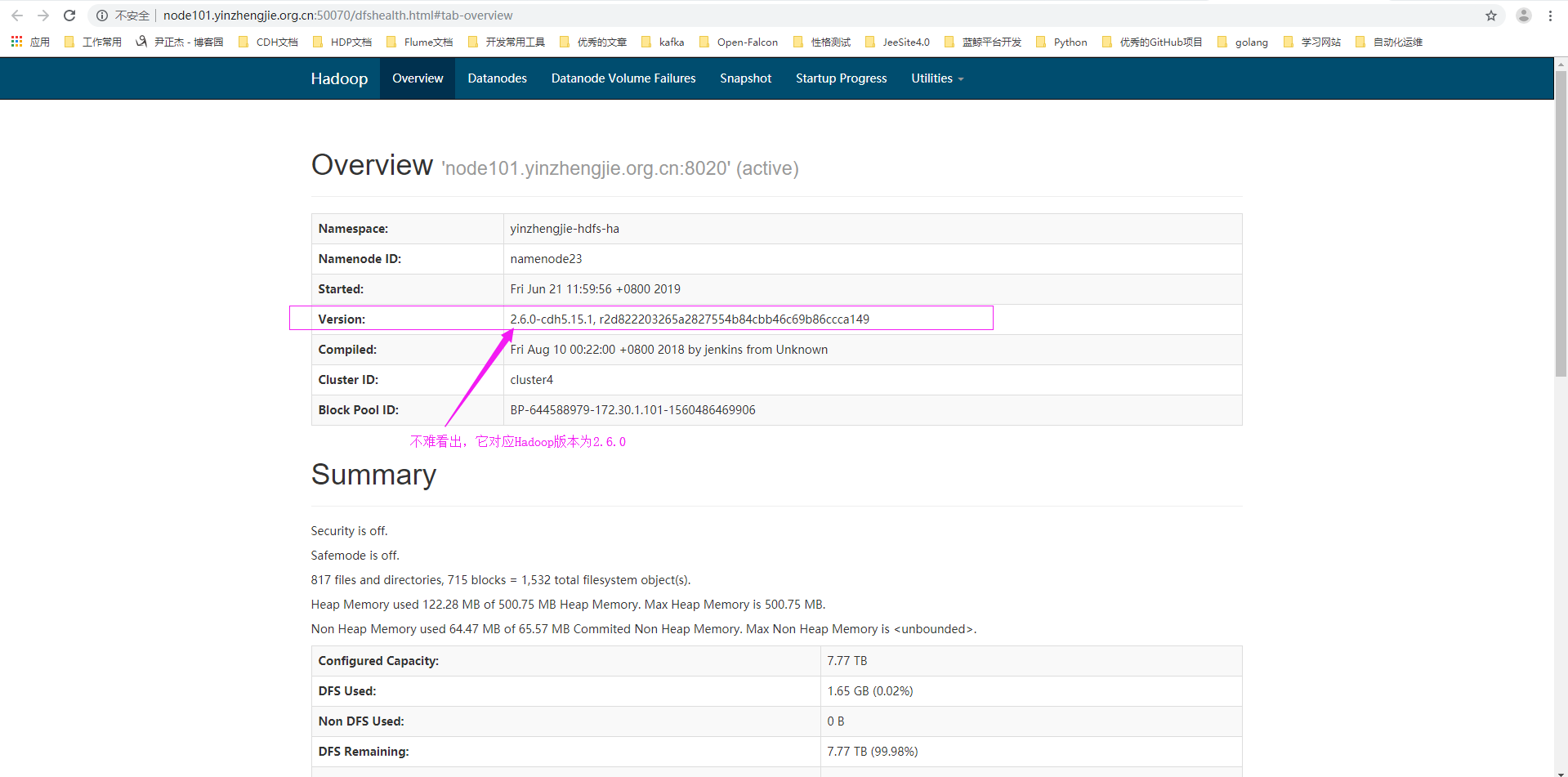
3>.查看Hadoop版本
4>.除了上面的方式查看Hadoop版本,我们还可以用以下的方式查看
5>.随机选中一个节点
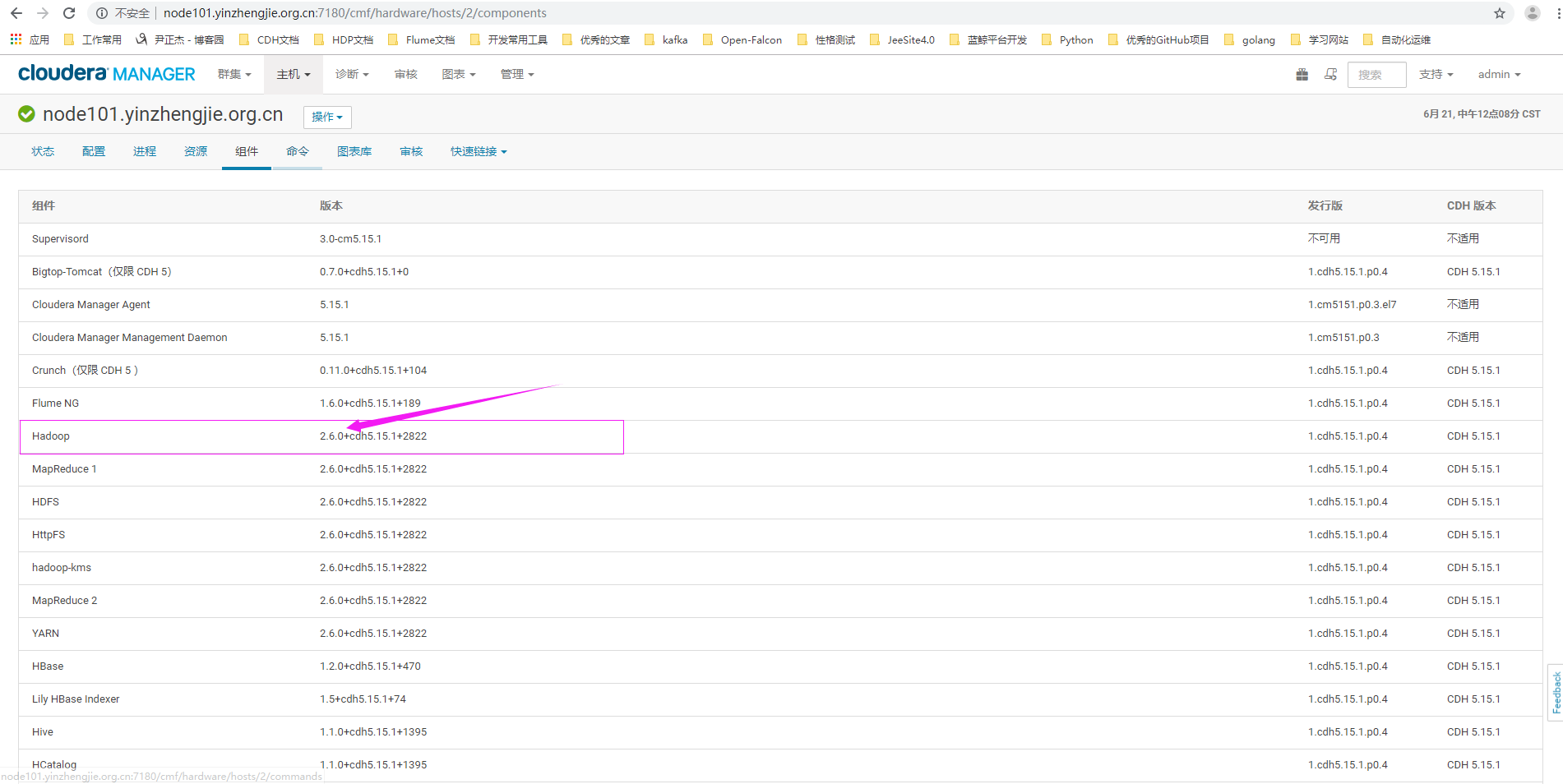
6>.点击"组件",可以查看各个软件的版本
二.HDFS配置文件详解
1>.以下参数讲解以社区版2.6.0的参数名和默认值为准(配置文件为:hdfs-default.xml / hdfs-site.xml )。
链接地址:http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
2>.dfs.namenode.name.dir
指定一个本地文件系统路径,决定NN在何处存放fsimage。可以通过逗号分隔指定多个路径,在Hadoop1.0时代这是一种为NN做高可用的方法,但目前有更完善的Journal Node解决方案,留默认值即可。
3>.dfs.permissions.enabled
默认为true。如果为true,则启用HDFS的权限检查,否则不启用。在生产 环境,一定要启用,测试环境可以自行决定。
4>.dfs.permissions.superusergroup
默认supergroup,指定HDFS的超级用户组的组名,可按需设置。
5>.dfs.datanode.data.dir
默认file://${hadoop.tmp.dir}/dfs/data,指定DN存放块数据的本地盘路径,可以通过逗号分隔指定多个路径。在生产环境可能会在一个DN上挂多块盘,因此需要修改该值。
6>.dfs.replication
块副本数,默认为3。默认值是一个比较稳妥的值。
7>.dfs.blocksize
块大小,默认为134217728,即128MB。对大多数生产环境来说是一个比较稳妥的值。因为该值决定了MR的默认map数,也会影响NN消耗的内存量, 需要谨慎修改。
8>.dfs.namenode.handler.count
NN处理rpc请求的线程数,默认为10,对大多数集群来说该值过小,设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。例如对100个节点的集群该值可以设到90。
当然,我们可以通过python帮我们计算合适的值。 [root@node101.yinzhengjie.org.cn ~]# python -c 'import math ; print int(math.log(100) * 20)' 92 [root@node101.yinzhengjie.org.cn ~]#
9>.dfs.datanode.balance.bandwidthPerSec
HDFS做均衡时使用的最大带宽,默认为1048576,即1MB/s,对大多数千兆 甚至万兆带宽的集群来说过小。不过该值可以在启动balancer脚本时再设 置,可以不修改集群层面默认值。
10>.dfs.hosts / dfs.hosts.exclude
指定连接NN的主机的白/黑名单。通常黑名单比较有用,例如在对DN进行 更换硬盘操作时,可以先将其加入黑名单进行摘除,等运维操作结束后再放行。
参考链接:https://www.cnblogs.com/yinzhengjie/p/10693499.html。
11>.dfs.datanode.failed.volumes.tolerated
DN多少块盘损坏后停止服务,默认为0,即一旦任何磁盘故障DN即关闭。 对盘较多的集群(例如每DN12块盘),磁盘故障是常态,通常可以将该值设置为1或2,避免频繁有DN下线。
12>.dfs.ha.automatic-failover.enabled
是否启用HDFS的自动故障转移,默认为false。像CDH等发行版,如果打开 HDFS HA后,该值会被自动更新为true,因此通常不需要自己改动。
13>.dfs.support.append
是否启用HDFS的追加写入支持,默认为true。老版本Hadoop上append功能有bug,因此该值曾经默认为false,但现在已经可以放心使用true,有老集群升级上来的需要调整。
14>.dfs.encrypt.data.transfer
HDFS数据在网络上传输时是否加密,默认为false。如果Hadoop集群运行 在非安全网络上,可以考虑开启该参数,但会带来一些CPU开销。通常 Hadoop都会在私有网络内部署,不需要动该值。
15>.dfs.client.read.shortcircuit
是否开启HDFS的短路本地读,默认为false。像CDH等发行版会默认将该参 数打开,并且如果在任何一种Hadoop上安装Impala,也需要打开该参数。 打开后,还需要设置dfs.domain.socket.path参数以指定一个Unix Socket文件的路径。
16>.dfs.datanode.handler.count
数据节点的服务器线程数,默认为10。可适当增加这个数值来提升DataNode RPC服务的并发度。 在DataNode上设定,取决于系统的繁忙程度,设置太小会导致性能下降甚至报错。线程数的提高将增加DataNode的内存需求,因此,不宜过度调整这个数值。
17>.dfs.datanode.max.transfer.threads (dfs.datanode.max.xcievers)
DataNode可以同时处理的数据传输连接数,即指定在DataNode内外传输数据使用的最大线程数。 官方将该参数的命名改为dfs.datanode.max.transfer.threads。默认值为4096。推荐值为8192。
18>.dfs.namenode.avoid.read.stale.datanode
指示是否避免读取“过时”的数据节点(DataNode),这些数据节点(DataNode)的心跳消息在指定的时间间隔内未被名称节点(NameNode)接收。过时的数据节点(DataNode)将移动到返回供读取的节点列表的末尾。有关写入的类似设置,请参阅df.namenode.avoint.write.stale.datanode。默认值是flase,推荐设置为true。
19>.dfs.namenode.avoid.write.stale.datanode
指示超过失效 DataNode 时间间隔 NameNode 未收到检测信号信息时是否避免写入失效 DataNode。写入应避免使用失效 DataNode,除非多个已配置比率 (dfs.namenode.write.stale.datanode.ratio) 的 DataNode 标记为失效。有关读取的类似设置,请参阅 dfs.namenode.avoid.read.stale.datanode。 默认值是flase,推荐设置为true。
20>.dfs.datanode.du.reserved
当DataNode向NameNode汇报可用的硬盘大小的时候,它会把所有dfs.data.dir所列出的可用的硬盘大小总和发给NameNode。由于mapred.local.dir经常会跟DataNode共享可用的硬盘资源,因此我们需要为Mapreduce任务保留一些硬盘资源。dfs.datanode.du.reserved定义了每个dfs.data.dir所定义的硬盘空间需要保留的大小,以byte为单位。默认情况下,该值为0,也就是说HDFS可以使用每个数据硬盘的所有空间,节点硬盘资源耗尽时就会进入读模式。因此,建议每个硬盘都为map任务保留最少10GB的空间,如果每个Mapreduce作业都会产生大量的中间结果,或者每个硬盘空间都比较大(超过2TB),那么建议相应的增大保留的硬盘空间。我在生产环境中设置改值的大小为50G字节!
21>.其他配置
有一些操作系统或Linux文件系统层面的配置,本身不属于HDFS,但会对 HDFS的性能或可用性有影响,我们也需要了解:https://www.cnblogs.com/yinzhengjie/p/10367447.html
三.HDFS日常维护
1>.容量管理
理解HDFS的数据都是以普通文件格式写到DN的本地磁盘。HDFS的已使用容量有多种查看方式,比如NameNode页面(默认端口50070的)、hdfs dfs命令、以及集群管理器页面(如Cloudera CM)。
HDFS总使用容量在80%以下是安全的,超过就需要人工干预。另外也要理解,HDFS不可能做到每个DN的每块盘都以相同的百分比写入数据,很可能出现总容量使用80%,但个别盘已经超90%甚至写满的情况,这时候就需要借助balancer脚本(start-balancer.sh)或 hdfs balancer命令来进行均衡。为了管理数据,还需要熟悉常用的hdfs 和Linux命令。 容量管理还涉及到非技术性工作。如企业的数据总量和增量如何? 如何设置清理策略?是否需要对冷热数据采取不同的管理策略(如存储介质、副本数)?如何制定扩容、灾备方案?等等。这些工作无法通过培训传授方案,需要结合企业实际进行规划。
2>.进程管理
HDFS进程管理中,DN的进程比较次要,死掉只需处理完问题再拉起即可。 NN进程的可用性决定了整个HDFS的可用性。目前已有完善的NameNode HA方案,如果是 社区版集群,可参考(QJM方案): http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html。如果是CDH集群,可进入HDFS服务,点击Actions - Enable High Availability,按照指引逐步操作即可,比较直观。 另外,为了保证NN进程的稳定,还需要考虑分配的JVM内存。我们介绍过一般100w个块对应300MB堆内存,按此计算出一个值后,再乘以2就够用了。
3>.故障管理
HDFS最常见的是硬盘故障,停机更换即可,注意同时停机个数<副本数即可,服务起来后做一下fsck。
NN的故障比较棘手。有了Hadoop2.x后的NameNode HA机制后,单点故障不再可怕,但仍会被内存相关问题困扰。最常出现的情况就是出现长时间的full GC,使得NN无法响应其他进程的RPC请求,从而造成严重问题。 推荐使用Java8以上版本的JDK以及G1GC,并分配足够的堆内存,使得每次GC的时间可控。
4>.配置管理
HDFS主要配置的说明已介绍过,其余配置可查询官方文档(以2.6.0为 例): http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml.
需要注意的是大部分配置需要重启HDFS服务生效,小部分需要重启单个DN生效。
5>. 对HDFS日常维护中常用的命令总结
HDFS一般命令,在日常维护中高频使用的:
列出文件 文件(及目录)的复制、追加、删除、读取
文件(及目录)权限和归属的修改
文件(及目录)大小统计
HDFS管理命令,在日常维护中高频使用的:
hdfs fsck
hdfs balancer
namenode系列命令(例如启用HA等)
dfsadmin系列命令(进入退出安全模式、升级HDFS等)
四.课后作业
在你的测试集群(最好有多台虚拟机搭一个全分布集群),测试HDFS接近写满文件时的状态变化
实验配置NameNode HA
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/articles/11063804.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
