
Flink环境部署
Flink环境部署
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Flink简介
1>.什么是Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
在这里,我们解释Flink架构的重要方面。官方地址:https://flink.apache.org/。
2>.处理无界和有界数据(https://flink.apache.org/flink-architecture.html)
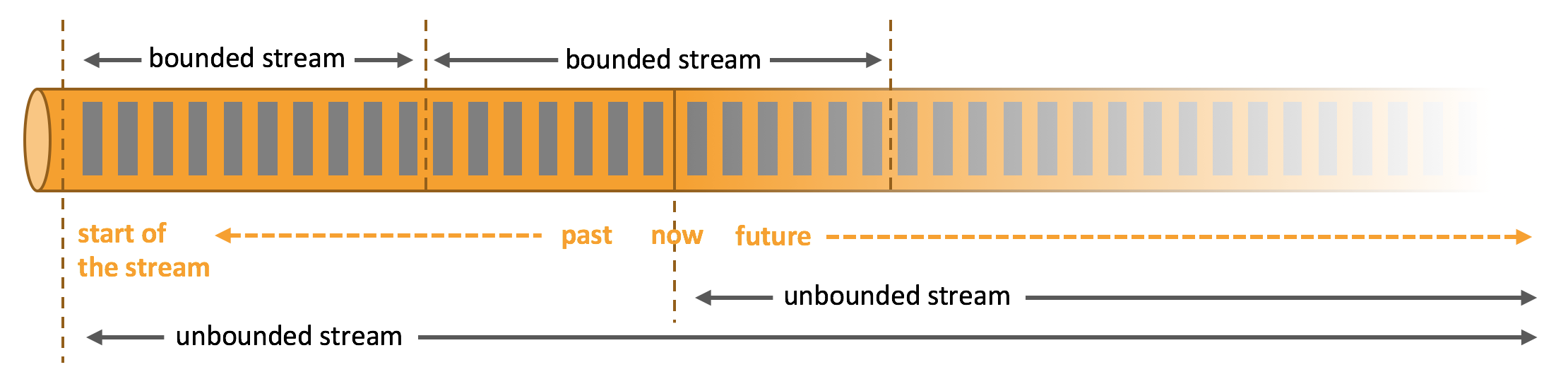
数据可以作为无界或有界流处理。
1>.无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须连续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果完整性。
2>.有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
二.
本文来自博客园,作者:尹正杰,转载请注明原文链接:https://www.cnblogs.com/yinzhengjie/articles/10437473.html,个人微信: "JasonYin2020"(添加时请备注来源及意图备注,有偿付费)
当你的才华还撑不起你的野心的时候,你就应该静下心来学习。当你的能力还驾驭不了你的目标的时候,你就应该沉下心来历练。问问自己,想要怎样的人生。
