python3(urlopen)获取网页的坑
首先,python2和python3在导入urlrequest的方式都不一样。
python2是这样:import urllib2
而python3里面把urllib分开了,分成了urlrequest和urlerror,在这里我们只需导入urlrequest即可。from urllib.request import urlopen
然后直接放代码跟着代码讲吧,这个是正确的例子:
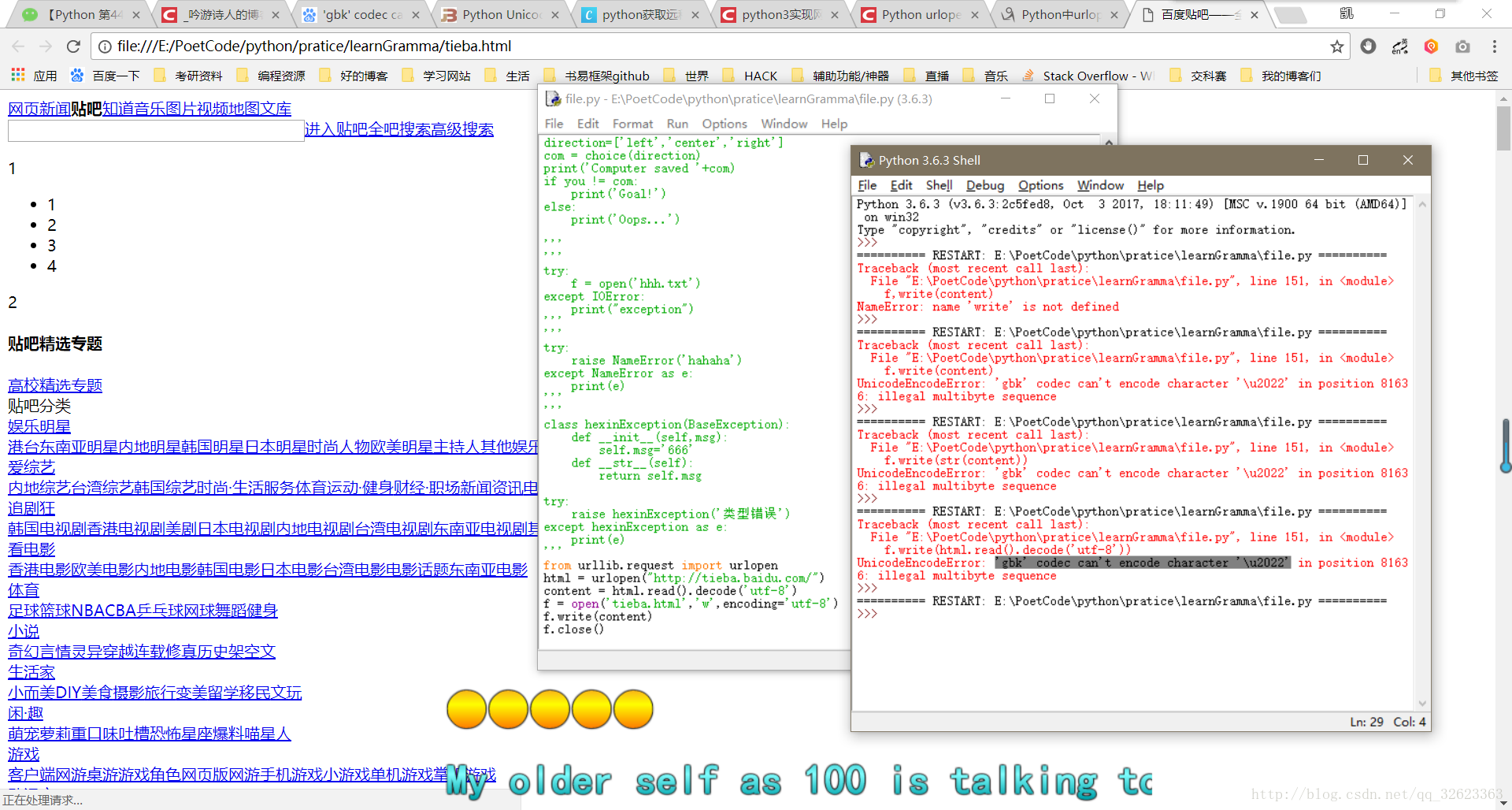
from urllib.request import urlopen
html = urlopen("http://tieba.baidu.com/")
content = html.read().decode('utf-8')
f = open('tieba.html','w',encoding='utf-8')
f.write(content)
f.close()可以看到content=html.read().decode('utf-8')这一句,网上看的全都没有加decode,当我在将其保存进文件时就会提示,不能将byte类型的以str形式存入。
TypeError: write() argument must be str, not bytes当然看到这个错误之后第一想法就是将下面的write函数的参数改成write(str(content))
这么做确实没报错了,但是打开文件后会发现,完全是乱码啊,而且以html格式打开也都是\t\n 之类的乱码。
但是加上decode后就没这个问题啦!!
BUT会有新问题产生
接下来如果参照网上的例子,大多是这样f =open('tieba.html','w'),没有encoding,这又会报错:
UnicodeEncodeError: 'gbk' codec can't encode character '\u2022' in position 81636: illegal multibyte sequence这是因为电脑会默认创建gbk编码的文件,而出于不知名原因存入utf-8编码的文件时就会无法编码,因此只能在open后面设置编码,这样在新创建一个文件的时候就会创建的是utf-8编码的文件了。
如此,才算是正是解决问题。
附一张下载下来运行的图:
python2和3之间差别还是不小的,而且诸多细节网上的教程并未说清,还得自己多研究呀。

