C++的引用
“引用”即“别名”,即是某对象的另一个名字。引用的主要用途是为了描述函数的参数(就是形参)和返回值。特别是用于运算符的重载。
引用的定义格式:
类型& 引用名=变量名;
废话少说,看个例子:
#include<iostream>
using namespace std;
int main()
{
int i=9;
int& ir=i;
cout<<"i= "<<i<<" "<<"ir="<<ir<<endl;
ir=20;
cout<<"i="<<i<<" "<<"ir="<<ir<<endl;
i=12;
cout<<"i="<<i<<" "<<"ir="<<ir<<endl;
cout<<"&i: "<<&i<<endl;
cout<<"&ir: "<<&ir<<endl;
return 0;
}
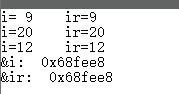
这说明了引用和原来的那个变量指向的是同一个地址,也就是说引用其实是和指针是很相似的。
先说点注意事项,再说引用和指针的区别。
- 引用不是值,不占据存储空间
- 引用必须在声明的时候就初始化,否则编译会报错
- 引用可以视为隐式指针,但不分配空间
- 引用的初始值可以是一个变量,也可以是一个引用
- 引用一旦被初始化赋值后,不可以重新赋值
- 不可以有引用的引用,因为引用的变量的类型必须为一个已知类型,而不存在某种基本类型的引用类型。这个有点绕,举个栗子:
int b = 2;
int &a=b;
int &&ra = a; // 这个是不行的
- 可以有指针变量的引用,不能有指向引用的指针,看下面代码,有点绕,慢慢理解吧。
int a=9;
int *p;
int *&rp = p; // rp是指针变量的引用
int &*ra = a; // 这个是错的,ra是一个指向引用的指针
指针和引用的区别:
- 指针是一个变量,只不过它存储的内容是它所指向的变量的地址罢了,因此指针是有自己额外的存储单元的;然而引用却没有这个存储单元,引用只是一个别名,和原变量一模一样。
- 指针可以为空,也可以随意赋值;引用不可以为空,必须在声明时就给定初值,并且给定之后还不能改。
- 可以有多级指针;只能由一级引用。
- 指针和引用的自增(++)运算含义不同。
sizeof(指针)得到的是指针变量的大小;sizeof(引用)得到的是被引用变量的大小。- 还有就是想必大家都很熟悉的,单独定义一个函数来交换a和b变量的值,以前C语言里这个问题就牵扯出来传值和传址,而现在又多了一个传引用,下面放上两种写法,可以看出传引用写起来方便很多。
void zhizhen_swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void yinyong_swap(int &a, int &b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int a = 1, b = 2;
zhizhen_swap(&a,&b);
cout<<a<<" "<<b<<endl;
yinyong_swap(a,b);
cout<<a<<" "<<b<<endl;
return 0;
}
引用参数相比于传值参数的优点有两点:
- 传值的话需要将所有参数复制一遍,如果传入的参数过大,那么会对内存造成比较大的不必要的消耗,而传引用的话就没有这个问题;
- 传引用的话可以让函数同时返回多个参数。这不是指可以return很多次,而是因为传引用的话,在函数中对参数的修改会直接影响到实参,这样就可以同时修改很多个实参的值了。
然后讲一下引用与const结合

不难理解,这里的意思就是,如果是const的引用,那么会先将想要引用的那个变量的值copy一份到一个临时变量中,并让这个引用指向这个临时内存。
其实下面代码中的后两行产生的效果是一样的。
int a = 5;
const int &b = a;
const int c = a;
更通俗点的话就看图吧:

最后讲一下函数返回值是引用的情况
这是一种很特殊也很神奇的方式,我们一般都是这样写的代码:int a = func(xxx);,即函数肯定是在右边,似乎很难想象这样的写法:func(xxx) = 6;,但是如果返回值是引用,这个看似荒谬的写法却是成立的。
看如下代码:
int &add(int a,int b,int& sum)
{
sum = a + b;
return sum;
}
int main()
{
int a=1, b=2,sum;
add(a,b,sum);
cout<<sum<<endl; // 3
cout<<"====="<<endl;
add(a,b,sum) = 5;
cout<<sum<<endl; // 5
return 0;
}
这是因为返回值是一个真真正正存在的能访问的变量啊,所以对返回值赋值就相当于对这个变量赋值,所以上述代码是正确的。
但是!如果上面代码中的 sum是在add函数内部定义的,这样就不行了,这是因为这样的话sum变量的作用域不够大,退出函数后他就被销毁了,所以这样的话理论上会返回一个随机值,但是,如果是简单的尝试,我们会发现它产生了一个类似把局部变量给全局化了的情况(当然这是不准确的,下面详述),直接看一下例子吧

看起来似乎这里就像把里面定义的那个sum变量变成了一个全局变量,不然&s_sum为什么会随着函数的调用而发生变化呢?
这就和C++的变量回收机制有关了,它回收的是那一个变量,但是并没有将那个变量原来所在的位置(这里指物理位置,即磁盘上的位置)上的数据清空或改变,上述代码在刚刚回收了这个变量后又立刻执行了这个函数,然后又马上声明了一个局部变量s_sum,这就让刚刚被释放的物理位置又重新被占用了,这是一个巧合,即如果中间执行了很多别的程序,让别的变量的地址占用了这一个地址,那么s_sum的值就会显露出它的随机性了(不是真的随机,而是没有意义了),因为s_sum它是指向那一个地址单元的,而这个例子中那个地址单元只不过刚好又被下一次执行的add函数中的temp变量所申请并占用了而已。

