数据库性能优化技法
数据库大家都熟悉,但是一般很少会去考虑它的性能问题,毕竟几万几十万条记录的处理,即便性能有差异那也几乎感觉不到,但是若是进入某些大企业,需要处理的数据量非常大,那样如何保证数据库能够持续高速运行、使得用户满意呢?
下面介绍两个方面,一个是大量数据插入的优化,一个是数据查询时的优化。
大量数据插入优化技法
本部分参考资料:
一、删索引
我们都知道索引是帮助提高查询效率的工具,但是索引的存在往往会对数据更新产生很大的影响。
每当我们插入一条数据后,都需要去修改整个索引的结构。现在一般关系型数据库的默认索引都采用的是B树或B+树算法,如果熟悉这种算法的都知道,它们更新起来往往有可能会让树的结构产生很大的变化,那样会非常降低效率,而即便是hash算法,也要不断地进行冲突避免,特别是大量数据插入时,对插入速度的影响就很大了。
所以,在大量数据插入时,如果没有特殊需求的话,先删除索引,等数据全部插入完成后再重新建立索引即可。
二、 一条SQL插入多条数据
如下面的SQL语句:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
可以将其修改为:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
修改后的插入操作可以大大减少插入频率,降低了网络I/O频率与SQL执行次数,也减少了日志刷新磁盘的数据量和频率,因此对效率的提高还是很明显的。
下面是一些测试数据的对比,分别是一条一条地插入和转换成一条SQL进行插入,分别测试100、1000、10000条记录。
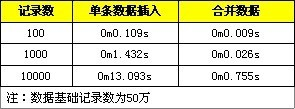
三、在事务中进行插入
即将插入修改为:
START TRANSACTION;
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
...
COMMIT;
我们正常的SQL插入时,mysql内部会建立一个事务,在事务内部才进行真正的插入处理,这也是为了保证数据的安全性嘛,不过如果直接插入,就需要一次一次地创建事务,对速度也会有很大的影响,下面就是使用事务和不使用事务的对比:
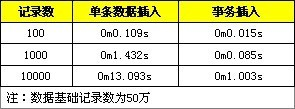
四、数据有序插入
或许大家听过一个叫做聚簇索引的东西,它就是指数据库中数据的物理存储和该索引所指的列的逻辑存储在顺序上是一样的,而且比如在mysql数据库中,主键索引默认就是聚簇索引。
因此我们若是在插入数据的时候就保证数据按主键顺序有序,那么插入数据自然也会有所提高。
比如可以将如下代码进行修改:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);
修改为:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);
下面是随机数据和顺序数据的插入的性能对比,不过暂时在这里看来差距不大:
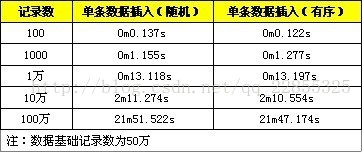
五、“二三四”三种方式综合测试
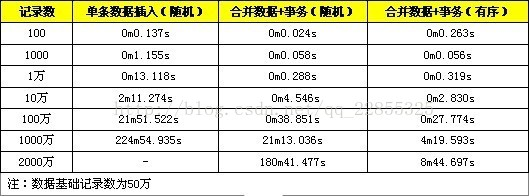
前面的第四种方法在单独使用时貌似没什么影响,可是如今综合起来面对超大数据时,优势就出来了。
可以看到合并数据+事务的方式在小数据量时的表现是非常好的,但是当数据量比较大时(1千万以上)性能就急剧下降,而合并数据+事务+有序数据的方式则可以在面对千万量级的数据时依然能够游刃有余。
需要注意的是:
-
SQL语句是有长度限制,在进行数据合并在同一SQL中务必不能超过SQL长度限制,通过max_allowed_packet配置可以修改,默认是1M,测试时修改为8M。
-
事务需要控制大小,事务太大可能会影响执行的效率。MySQL有innodb_log_buffer_size配置项,超过这个值会把innodb的数据刷到磁盘中,这时,效率会有所下降。所以比较好的做法是,在数据达到这个这个值前进行事务提交。
六、数据库连接池
这是一种面向工程的操作了,数据库连接池可以维护很多数据库连接,在进行插入的时候可以有效避免建立连接的时间,高并发时采用这种方式插入数据无疑效率很高。
七、多线程插入
就如第六点所言,高并发时采用数据库连接池很显然能够提高效率,那么何不直接将数据分成很多份,然后各开一个线程插入数据库呢?和数据库连接池配合食用效果更佳。
八、避免隐式转换
这个隐式转换和其他语言程序中的隐式转换是一个意思,比如如果数据库中某一个属性保存的都是数字,那么就不要将其设置为CHAR类型,否则有可能会影响索引的效率,而在大量数据插入时不断的类型转换也会占用大量的CPU资源。
好了对于数据插入的方法就到这里了,肯定还有其他很多好方法,日后习得了再慢慢补充。
大量数据查询优化技法
关于大量数据的查询,有兴趣的小伙伴们可以去玩一玩阿里云举办的一个关于慢sql优化的比赛,虽然时间已经过了,但是有兴趣的话可以去试试的。同时在这个页面下方也有非常优秀的优化方法介绍。
放一下它的链接:https://yq.aliyun.com/articles/183749?spm=a2c4e.11154000.rtdmain.1.3a1046c9PF3WGO
下面正式讲一下优化的方法:
一、添加索引
这个没什么好解释的了,索引就像书的目录一样,用得好的话可以指数级地提高查询效率。
二、关于索引建立的方式
建立索引不要对需要查询的每一列都单独建立一个索引,这样会非常占用磁盘空间,因为每一份索引都需要对所有数据单独建立一份不同的数据结构的数据。
建立索引也不要用一个索引将所有的字段全部包括进去,这样建立索引就没有意义了。
其他的优化方式我还是建议多看看阿里云的那篇:https://yq.aliyun.com/articles/183749?spm=a2c4e.11154000.rtdmain.1.3a1046c9PF3WGO
讲的太好了!


