tensorflow2.0常用操作记录
tensorflow是非常流行的深度学习框架,其2.0版本与其1.0版本也有较大不同,因此笔者就近期对tensorflow2.0的基本操作的学习进行记录,以供日后查阅。
创建tensor
tf.constant(1)
tf.constant(1.)
tf.constant(2.2, dtype=tf.double)
tf.constant(2.2, dtype=tf.float16)
tf.constant([True, False])
tf.constant('Hello World!')
判断变量创建在cpu还是gpu上
c = tf.constant([1,2,3])
d = tf.range(5)
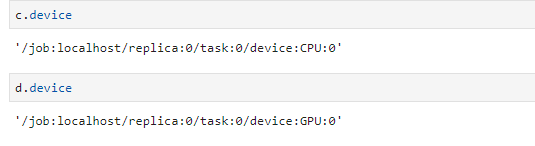
c.device
d.device
输出如下:
也可以强制变量创建在cpu或者gpu上
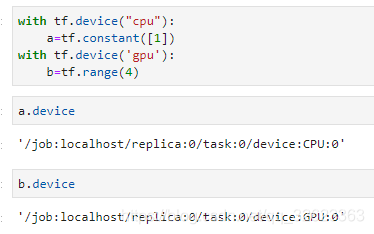
也可以将cpu上的变量换到gpu上,同理也可以将gpu上变量换到cpu上,现在新版本tensorflow允许cpu和gpu上变量进行计算了,老版本则不允许,此时需要将cpu的变量保存到gpu上才能和gpu上变量进行运算。如下:


张量基本操作
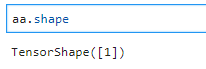
查看张量大小可以用shape()
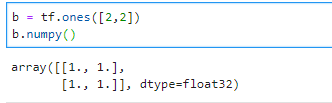
查看张量的值用numpy()
判断一个变量a是不是张量,用isinstance(a, tf.Tensor),或tf.is_tensor(a),推荐使用后者,因为前者在判断Variable类型时会返回False而后者返回True
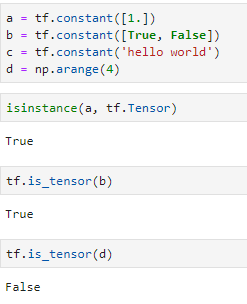
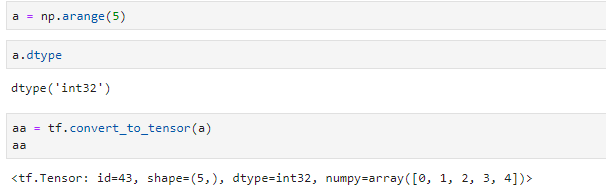
将普通变量转为tensor,可以使用tf.convert_to_tensor(a)
张量内部数据类型转换,用cast(a, dtype=xxx)

查看张量内部数据类型,用a.dtype,还有个已经废弃的属性,即name属性,同时张量也可以很容易转换成Variable类型,事实上不严谨地说可以把Variable当成Tensor的子类(其实不是而且区别挺大的)。且Variable类型的变量具有trainable属性,且默认为true且不能修改
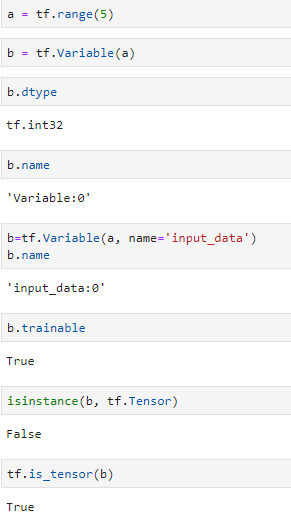
张量的生成函数
# tf.zeros系列
tf.zeros([]) #<tf.Tensor: id=70, shape=(), dtype=float32, numpy=0.0>
tf.zeros([1]) # <tf.Tensor: id=76, shape=(1,), dtype=float32, numpy=array([0.], dtype=float32)>
a = tf.zeros([2,3,3])
tf.zeros_like(a) # 生成与a的维度相同的全零张量
tf.zeros(a.shape) # 与tf.zeros_like(a)作用相同
# tf.ones系列
tf.ones([1,2,3])
tf.ones_like(a)
# tf.fill系列
tf.fill([2,2],0)
# tf.random系列
# tf.random.normal是正态分布,mean是均值,stddev是标准差(方差开根号)
tf.random.normal([2,2], mean=1, stddev=1)
# tf.random.truncated_normal是截断正态分布,其数据分布限制在均值±2倍标准差的范围
tf.random.truncated_normal([2,2], mean=0, stddev=1)
# tf.random.uniform是均匀分布
tf.random.uniform([2,2], minval=0,maxval=1)
# tf.range系列
a = tf.range(10)
# 将张量内部顺序随机打乱,用tf.random.shuffle
idx=tf.range(10)
idx=tf.random.shuffle(idx)
# <tf.Tensor: id=151, shape=(10,), dtype=int32, numpy=array([8, 7, 1, 6, 2, 5, 9, 3, 4, 0])>
数据打乱整形技巧shuffle与gather
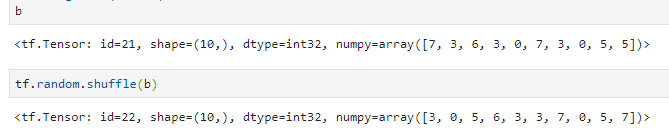
比如给定一个一维张量,要把其元素随机打乱,要如何处理?
如下图,假设给定的一维张量为b,长度为10,idx为打乱后的索引值,则可以根据一个给定的索引列表idx来打乱张量b。
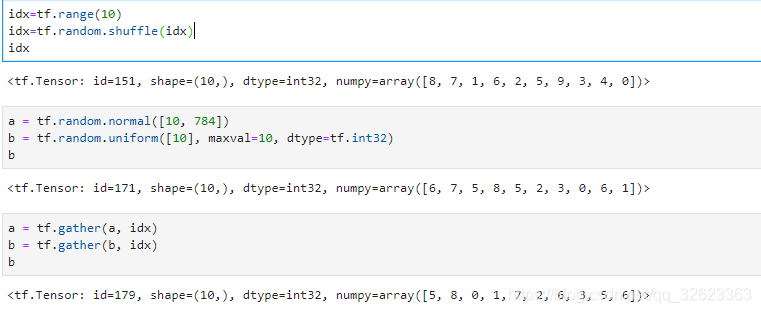
当然如果只是单纯的要打乱b的话可以使用如下方法,使用gather的好处是知道和原列表的对应关系:
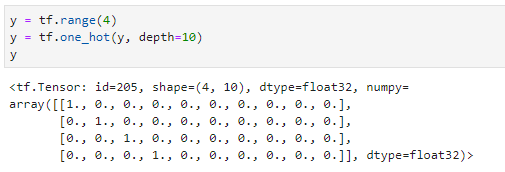
one_hot编码
mse
下图为计算y与out之间的MSE

reduce系列
reduce_min, reduce_max, reduce_mean, reduce_sum
分别求一个张量中的最小值、最大值、平均值、和
可以指定axis,默认是求全局,之所以前面加上reduce是因为该函数必然会导致降维
最大最小值的索引
采用tf.argmax(a,axis=xx)可以获得a沿着xx维上的最大值的索引,tf.argmin同理。
取张量中数据的操作
a = tf.ones([1,5,5,3])
a[0][0]
a[0, 0] # 和上式效果相同,推荐这种写法
a[-1:, :]
a[0::2] # 隔一个取一个
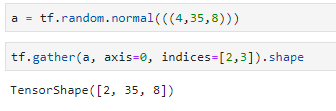
gather和gather_nd
tf.gather在上面已经见过了,但是其实它的真正用法在于从张量中抽取数据,可以指定抽取的维度,和某个纬度上抽取的元素的索引。
gather_nd可以取多个维度指定索引的数据(图源网络)

boolean_mask
boolean_mask可以取指定维度标为true的数据(图源网络)

维度变化
转置:
# 将a中元素按指定轴的顺序转置,此处为将axis=0和axis=1进行转置
tf.transpose(a, [0,2,1,3])
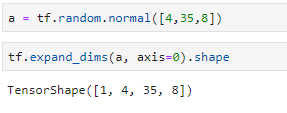
维度扩展:
维度降低(将长度为1的维度删除):
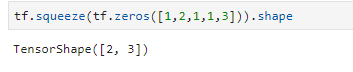
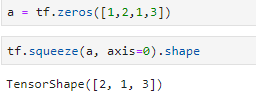
指定删除维度:
矩阵乘法
A@B 或 tf.matmul(A, B)
张量连接与取消连接
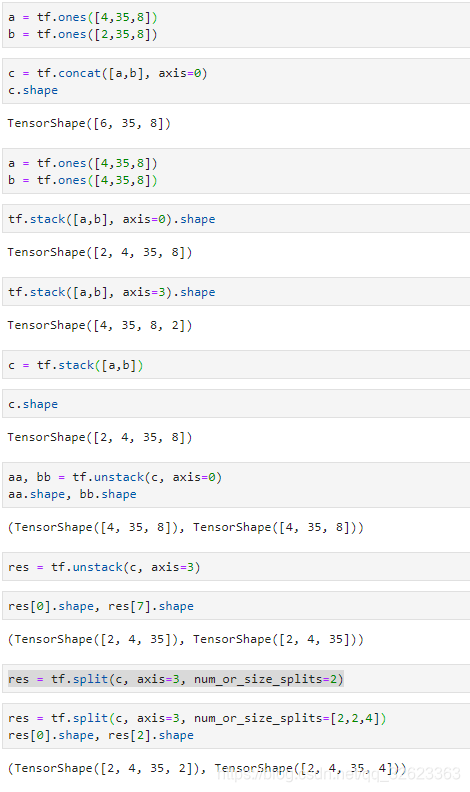
引入:concat,stack,unstack,split
concat不扩展维度,只增加长度,要求指定维度以外的维度的长度都相同
stack扩展维度,要求所有维度都相同
unstack降低纬度,将指定维度分为指定维度的长度个低维张量
split纬度分割,可以将指定维度分为指定长度的几个部分
范数
# 求张量a沿着第3(2+1)个维度上的1范数
tf.norm(a, ord=1, axis=2)
张量列表不重复元素
使用unique可以获得不重复元素和其索引组成的tuple,可以用gather给它还原

参考资料:https://github.com/dragen1860/TensorFlow-2.x-Tutorials

