pythonⅣ
package:针对代码结构的组织,一个包里面可以拥有很多的python文件
module:一个python文件就是一个模块
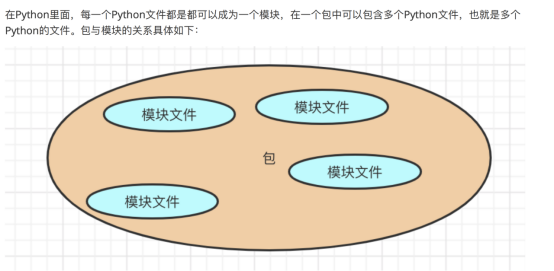

一个模块想引用另外一个模块里的代码,怎么实现
from package.module import 变量,函数
同一个包和不同包的引用是一样的
在移动包之后,package.module会自动更改,如果包下还有包则从第一个包开始层层递进
'''
#使用*表示导入asd中的所有的变量函数
from zxc.asd import *
print(name)
print(age)
login()
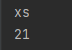
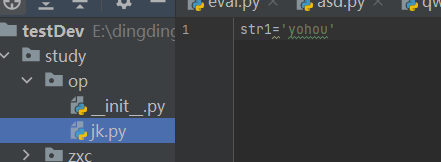
from study.op.jk import *
print(str1)
库:
1、标准库 安装Python环境后自带的
2、第三方的库 第三方的个人以及公司发布
selenium:WEB自动化测试框架
requests:API测试框架
flask:轻量级WEB开发框架
django:全栈WEB开发框架
fastapi:异步WEB框架
pip install 库的名称(pip install pytest)
pip uninstall 库的名称
3、自定义的库
'''
文件操作:
1、写
2、读
操作文件三个步骤:
1、打开文件
2、读/写
3、关闭文件
文件操作的模式:
a :追加
w :写(假设文件里面有内容,先清空再写)
r :读
'''
'''
open函数写文件逻辑:
1、如果被操作文件不存在,它会自动给创建文件
2、如果文件存在,并且里面有内容,模式是w,先清空再写
'''
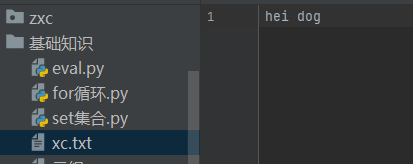
x=open('xc.txt','w')
x.write('hei dog')
x.close()
x=open('xc.txt','a')
x.write('\nhahaha')
x.close()
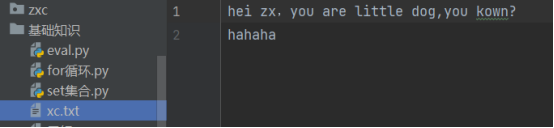
# 写入文件必须是字符串
list1=[y for y in range(10)]
x=open('xc.txt','w')
for item in list1:
x.write('\n'+str(item)
x.close()
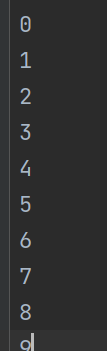
#如果出错,文件路径有问题
# 写中文出错的时候需要加上encodings='utf-8' x=open('xc.txt','r',encoding='utf-8'),
# utf-8不行的时候使用gbk,或者gb2312
x=open('xc.txt','r')
#read()读取文件里面所有内容
print(x.read())
# #默认读取第一行
print(x.readline())
x.close()
#按行读取
for item in x.readlines():
print(item.strip())
x.close()
for item in x.readlines():
if '你' in item:
print(item)
x.close()
#with上下文:它的内部会自动关闭文件
with open('xc.txt','r') as x:
# x.write("ok")
for item in x.readline():
print(item.strip())
'''
序列化:把python对象(list&tuple&dict)转为字符串的过程 dumps()
反序列化:字符串转为python对象的过程 loads()
'''
import json
#字典的序列化与反序列化
dict1={'name':'xw','age':'18'}
dict_str=json.dumps(dict1)
print(dict_str,type(dict_str))
str_dict=json.loads(dict_str)
print(str_dict,type(str_dict))

#列表的序列化与反序列化
list1=[x for x in range(10)]
list_str=json.dumps((list1))
print(list_str,type(list_str))
str_list=json.loads(list_str)
print(str_list,type(str_list))

#元组的序列化与反序列化
tuple1=(1,2,3)
tuple_str=json.dumps(tuple1)
print(tuple_str,type(tuple_str))
#元组在反序列化以后不会变回元组,而是列表
str_tuple=json.loads(tuple_str)
print(str_tuple,type(str_tuple))

#文件的序列化:把第三方的内容写到文件里面 dump()
#文件的反序列化:把文件的内容读取出来 load()
dict1={"token":"eyJ0eXAi","user":{"uid":"adGw32EcTpNmbYrN2mXCkA","telephone":"13484545195","username":"无涯","email":None,"avator":"","date_joined":"2022-01-08T15:07:01.003115+08:00","is_active":True}}
json.dump(dict1,open('xc.json','w',encoding='utf-8'))
print(json.load(open('xc.json','r')))


import time
#休眠五秒
time.sleep(5)
#获取当前时间的时间戳
print(time.time())

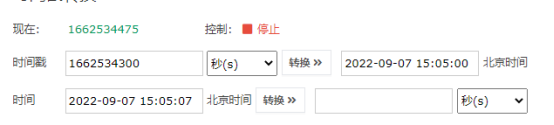
#时间戳转换为当前时间
t=time.localtime(time.time())
print(t.tm_year,t.tm_mon,t.tm_mday,t.tm_hour,t.tm_min,t.tm_sec)

#获取当前时间
print(time.strftime('%y-%m-%d %H:%M:%S',time.localtime()))

import datetime
#获取当前时间
print(datetime.datetime.now())
#在当前的实践基础上加(减)时间
print(datetime.datetime.now()+datetime.timedelta(days=-1))
print(datetime.datetime.now()+datetime.timedelta(days=1))
print(datetime.datetime.now()+datetime.timedelta(hours=-1))
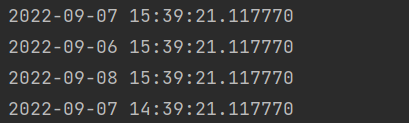
'''
open api:开放平台接口
1、正对请求参数进行ascil码排序
2、把请求参数处理成key1=value1&key2=value2
3,进行md5的加密、
'''
import hashlib
from urllib import parse
import time
def sign():
dict1={'name':'xc','age':18,'sex':'boy','time':time.time()}
dict1=dict(sorted(dict1.items(),key=lambda item:item[0]))
print(dict1)
data=parse.urlencode(dict1)
print(data)
m=hashlib.md5()
m.update(data.encode('utf-8'))
print(m.hexdigest())
sign()



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架