并发编程-ConcurrentHashMap
ConcurrentHashMap是J.U.C包里面提供的一个线程安全并且高效的HashMap,所以ConcurrentHashMap在并发编程的场景中使用的频率比较高,那么这一节课我们就从ConcurrentHashMap的使用上以及源码层面来分析ConcurrentHashMap到底是如何实现安全性的
ConcurrentHashMap的源码分析
JDK1.7和Jdk1.8版本的变化
ConcurrentHashMap和HashMap的实现原理是差不多的,但是因为ConcurrentHashMap需要支持并发操作,所以在实现上要比hashmap稍微复杂一些。
在JDK1.7的实现上,ConrruentHashMap由一个个Segment组成,简单来说,ConcurrentHashMap是一个Segment数组,它通过继承ReentrantLock来进行加锁,通过每次锁住一个segment来保证每个segment内的操作的线程安全性从而实现全局线程安全。
static class Segment<K,V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; final float loadFactor; Segment(float lf) { this.loadFactor = lf; } }
当每个操作分布在不同的segment上的时候,默认情况下,理论上可以同时支持16个线程的并发写入。
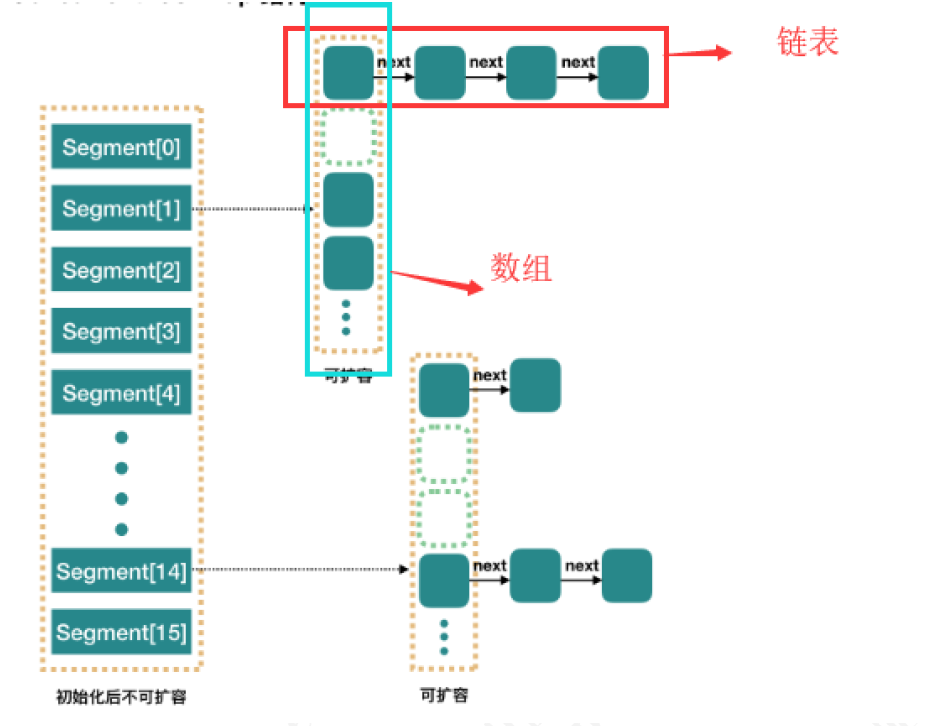
相比于1.7版本,它做了两个改进
1. 取消了segment分段设计,直接使用Node数组来保存数据,并且采用Node数组元素作为锁来实现每一行数据进行加锁来进一步减少并发冲突的概率
2. 将原本数组+单向链表的数据结构变更为了数组+单向链表+红黑树的结构。为什么要引入红黑树呢?在正常情况下,keyhash之后如果能够很均匀的分散在数组中,那么table数组中的每个队列的长度主要为0或者1.但是实际情况下,还是会存在一些队列长度过长的情况。如果还采用单向列表方式,那么查询某个节点的时间复杂度就变为O(n); 因此对于队列长度超过8的列表,JDK1.8采用了红黑树的结构,那么查询的时间复杂度就会降低到O(logN),可以提升查找的性能;
put方法第一阶段
public V put(K key, V value) { return putVal(key, value, false); }
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //计算hash值
int binCount = 0; //用来记录链表的长度 for (Node<K,V>[] tab = table;;) { //这里其实就是自旋操作,当出现线程竞争时不断自旋
Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0)//如果数组为空,则进行数组初始化
tab = initTable(); 初始化数组 //通过hash值对应的数组下标得到第一个节点; 以volatile读的方式来读取table数组中的元素,保证每次拿到的数据都是最新的
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //如果该下标返回的节点为空,则直接通过cas将新的值封装成node插入即可;如果cas失败,说明存在竞争,则进入下一次循环
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } 点击跳转->执行到这个 阶段,数据结构图 。。。 }
假如在上面这段代码中存在两个线程,在不加锁的情况下:线程A成功执行casTabAt操作后,随后的线程B可以通过tabAt方法立刻看到table[i]的改变。原因如下:线程A的casTabAt操作,具有volatile读写相同的内存语义,根据volatile的happens-before规则:线程A的casTabAt操作,一定对线程B的tabAt操作可见
initTable
数组初始化方法,这个方法比较简单,就是初始化一个合适大小的数组
sizeCtl这个要单独说一下,如果没搞懂这个属性的意义,可能会被搞晕
这个标志是在Node数组初始化或者扩容的时候的一个控制位标识,负数代表正在进行初始化或者扩容操作
-1 代表正在初始化
-N 代表有N-1有二个线程正在进行扩容操作,这里不是简单的理解成n个线程,sizeCtl就是-N,这块后续在讲扩容的时候会说明
0标识Node数组还没有被初始化,正数代表初始化或者下一次扩容的大小
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
//被其他线程抢占了初始化的操作,则直接让出自己的CPU时间片
Thread.yield(); // lost initialization race; just spin
//通过cas操作,将sizeCtl替换为-1,标识当前线程抢占到了初始化资格
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//默认初始容量为16
@SuppressWarnings("unchecked") //初始化数组,长度为16,或者初始化在构造ConcurrentHashMap的时候传入的长度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;//将这个数组赋值给table
sc = n - (n >>> 2); //计算下次扩容的大小,实际就是当前容量的0.75倍,这里使用了右移来计算
} } finally {
sizeCtl = sc; //设置sizeCtl为sc, 如果默认是16的话,那么这个时候sc=16*0.75=12 } break;
} } return tab; }
tabAt 该方法获取对象中 offset 偏移地址对应 的对象 field 的值 。 实际上这段代码的含义等价于 t ab[i], 但是 为什么不直接使用 t ab[i] 来计算呢? getObjectVolatile ,一旦看到 volatile 关键字,就表示可见性。 因为 对 volatile 写操作 happen before 于 volatile 读操作,因此其他线程对 table 的修改均对 get 读取可见; 虽然 table 数组 本身是增加了 volatile 属性,但是 volatile 的数组只针对数组的引用具有 volatile 的语义,而不是它的元素 。 所以如果有其他线程对这个数组的元素进行写操作,那 么当前线程来读的时候不一定能读到最新的值 。 出于性能考虑, Doug Lea 直接通过 Unsafe 类来对 table 进行操作。
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); }
put方法第二阶段
在putVal方法执行完成以后,会通过addCount来增加ConcurrentHashMap中的元素个数,并且还会可能触发扩容操作。这里会有两个非常经典的设计
1. 高并发下的扩容
2. 如何保证addCount的数据安全性以及性能
//将当前ConcurrentHashMap的元素数量加1,有可能触发transfer操作(扩容)
addCount(1L, binCount); return null; }
addCount
在putVal最后调用addCount的时候,传递了两个参数,分别是1和binCount(链表长度),看看addCount方法里面做了什么操作
x表示这次需要在表中增加的元素个数,check参数表示是否需要进行扩容检查,大于等于0都需要进行检查
private final void addCount(long x, int check) { CounterCell[] as; long b, s;
判断counterCells是否为空,
1. 如果为空,就通过cas操作尝试修改baseCount变量,对这个变量进行原子累加操作(做这个操作的意义是:如果在没有竞争的情况下,仍然采用baseCount来记录元素个数)
2. 如果cas失败说明存在竞争,这个时候不能再采用baseCount来累加,而是通过CounterCell来记录
if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true;//是否冲突标识,默认为没有冲突
这里有几个判断
1. 计数表为空则直接调用fullAddCount
2. 从计数表中随机取出一个数组的位置为空,直接调用fullAddCount
3. 通过CAS修改CounterCell随机位置的值,如果修改失败说明出现并发情况(这里又用到了一种巧妙的方法),调用fullAndCount
Random在线程并发的时候会有性能问题以及可能会产生相同的随机数,ThreadLocalRandom.getProbe可以解决这个问题,并且性能要比Random高
if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { fullAddCount(x, uncontended); return; } if (check <= 1) //链表长度小于等于1,不需要考虑扩容 return; s = sumCount();//统计ConcurrentHashMap元素个数
} if (check >= 0) { Node<K,V>[] tab, nt; int n, sc; while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { int rs = resizeStamp(n); if (sc < 0) { if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0) break; if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) transfer(tab, nt); } else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null); s = sumCount(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号