


#论文笔记# [pix2pixHD] High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
摘要:
我们提出了一个新方法,使用CGANs从语义标签图生成高分辨率的逼真图像。CGANs已经被应用在多种场景,但是其结果总是局限在低分辨率,还不够真实。在这个工作中,我们通过一个新的对抗损失,新的多尺度生成器和判别器架构,来生成2048x1024的吸引人的结果。此外,我们还通过两个附加特性将框架扩展到交互式可视化操作。首先,我们合并了物体的实例分割信息,它支持对物体的操作,例如删除/添加对象和更改对象类别。此外,我们提出了一种方法,在相同的输入条件下生成不同的结果,支持用户交互式地更改物体外观。人类的意见研究表明,我们的方法明显优于现有的方法,提高了深度图像合成和编辑的质量和分辨率。
介绍
实现以下功能:
主功能:通过一个新的对抗损失和多尺度生成器、判别器来生成高清图像,同时perceptual loss可进一步略微提高合成效果。
交互式拓展1:使用实例级物体分割信息,可进一步提高图像质量,实现对物体的灵活修改(物体增删,换类别)。
交互式拓展2:提取实例级特征,实现一对多的图像生成,支持物体的特征编辑。
方法
1. 主功能
主功能是一个coarse to fine的过程。分为三个部分:coarse-to-fine generator, multi-scale discriminators, improved adversarial loss。
-
coarse-to-fine generator
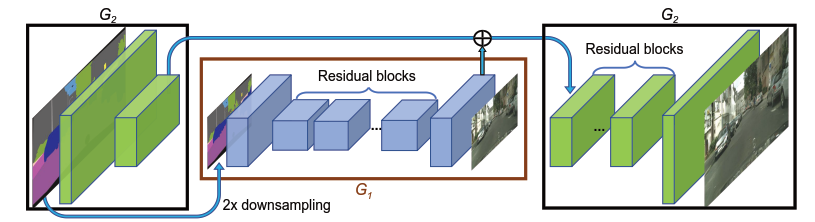
生成器由两个子网络G1和G2组成,其中G1是全局生成器,G2是局部增强生成器。
G1的架构是基于[22]的,有三部分:a convolutional front-end G1(F) , a set of residual blocks G1(R) [18], and a transposed convolutional back-end G1(B)。输入输出的分辨率均为1024*512。
G2的结构与G1相同,三部分G2(F), G2(R), G2(B)。不同于G1的是,G2的输入标签图和输出图像分辨率为2048*1024。另一个不同点是,G2(R)的输入是G2(F)和G1(B)的输出(最后一层)的feature map的element-wise sum。
训练过程中,先训练G1,后训练G2,再一起fine-tune。
-
multi-scale discriminators
使用多尺度判别器做高分辨率判别器,即3个相同网络架构但处理图像尺寸不同的判别器。处理图像的尺寸分别是2048*1024,1024*512,512*256。训练时分别用三种尺度的真假图像训练判别器。
其中,处理coarsest尺度的判别器有最大的感受野,更全局的视野,能使生成器生成全局一致(连续)的图像。处理finest尺度的判别器能使得生成器产生更精细的细节。 -
improved adversarial loss
添加一个基于判别器的feature matching loss,稳定训练。即从判别器的中间层提取特征,学习匹配真实图像和生成图像的这些中间表示。(具体含义还得看代码参透)
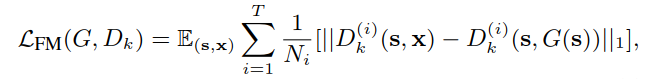
这个feature matching loss 和perceptual loss相关。实验中讨论了两个loss一起提高性能的效果。
加入了feature matching loss的目标函数如下:
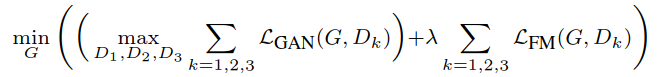
2. 交互式扩展1
原理:提出实例图中最重要的信息是物体边界,因此计算实例边界图(instance boundary map)。
计算方法:一个像素点与周围四个像素标签全部相同则赋值0,否则赋值1。即边界处为1,物体内部为0。
具体实现:实例边界图和语义标签图(原输入)的one-hot vector表示串联,输入生成器。同样,判别器的输入是实例边界图、语义标签图和真假图像这三者的通道级串联。
效果:加入实例边界图的模型能生成更真实的物体边界。
3. 交互式扩展2
原理:提出添加低维特征通道作为生成器的输入,从而可以通过修改这些特征来对生成图像进行灵活控制。
计算方法:训练一个编码器网络E,来寻找对应于图像中每个实例的目标的低维特征向量。编码器架构是标准的encoder-decoder网络。在encoder的输出层加上实例级的平均池化层来计算实例的平均特征,然后平均特征传播给该实例的所有像素点。
具体实现:训练中,编码器和生成器判别器一起训练。一旦编码器训练好,就在训练集中所有实例上运行编码器来记录得到的特征。然后对每个语义类别的所有特征执行k-means聚类算法,从而每个聚类都编码了一个特定风格的特征。在推断阶段,随机选取一个聚类中心作为特征,这个特征将和标签图一起输入到生成器中。
实现
实现细节:lambda = 10,K = 10(k-means),
Baselines:pix2pix,CRN
评价准则:语义分割scores,MTurK
论文中方法较多,n个问题有待解答。看代码后再补充。
