
Django学习笔记一十四——页面数据分页的实现
我们常常在页面上发现有分页的效果,具体的实现方法是怎么样的呢?
为了演示,创建一个Django项目,主要是配置好数据库,这里用了一个最简单的ORM的类
class Books(models.Model): id = models.AutoField(primary_key=True) title = models.CharField(max_length=16) def __str__(self): return "<object:{}>".format(self.title
然后创建一个python文件,用下面的代码生成50条数据
''' 创建书籍数据 ''' import os if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "分页.settings") import django django.setup() from app1 import models for i in range(1,50): t = '书籍'+str(i) book = models.Books(title=t) book.save()
然后我们的模板和视图是这样的,模板里调用了Bootstrap了组件,其中调用了一些静态的文件,如果有的话还好,没有就直接放个表格就行。


<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>书籍列表</title> <link rel="stylesheet" href="/static/bootstrap/css/bootstrap.min.css"> </head> <body> <div class="container"> <table class="table table-bordered"> <thead> <tr> <th>序号</th> <th>id</th> <th>title</th> </tr> </thead> <tbody> {%for book in books%} <tr> <td>{{forloop.counter}}</td> <td>{{book.id}}</td> <td>{{book.title}}</td> {%endfor%} </tr> </tbody> </table> </body> </html>
def book(request): all_book = models.Books.objects.all() return render(request,'book.html',{'books':all_book})
url就随便设置把,只要能映射到视图里的函数就可以了。
运行项目,访问地址,会发现所有的数据都显示了
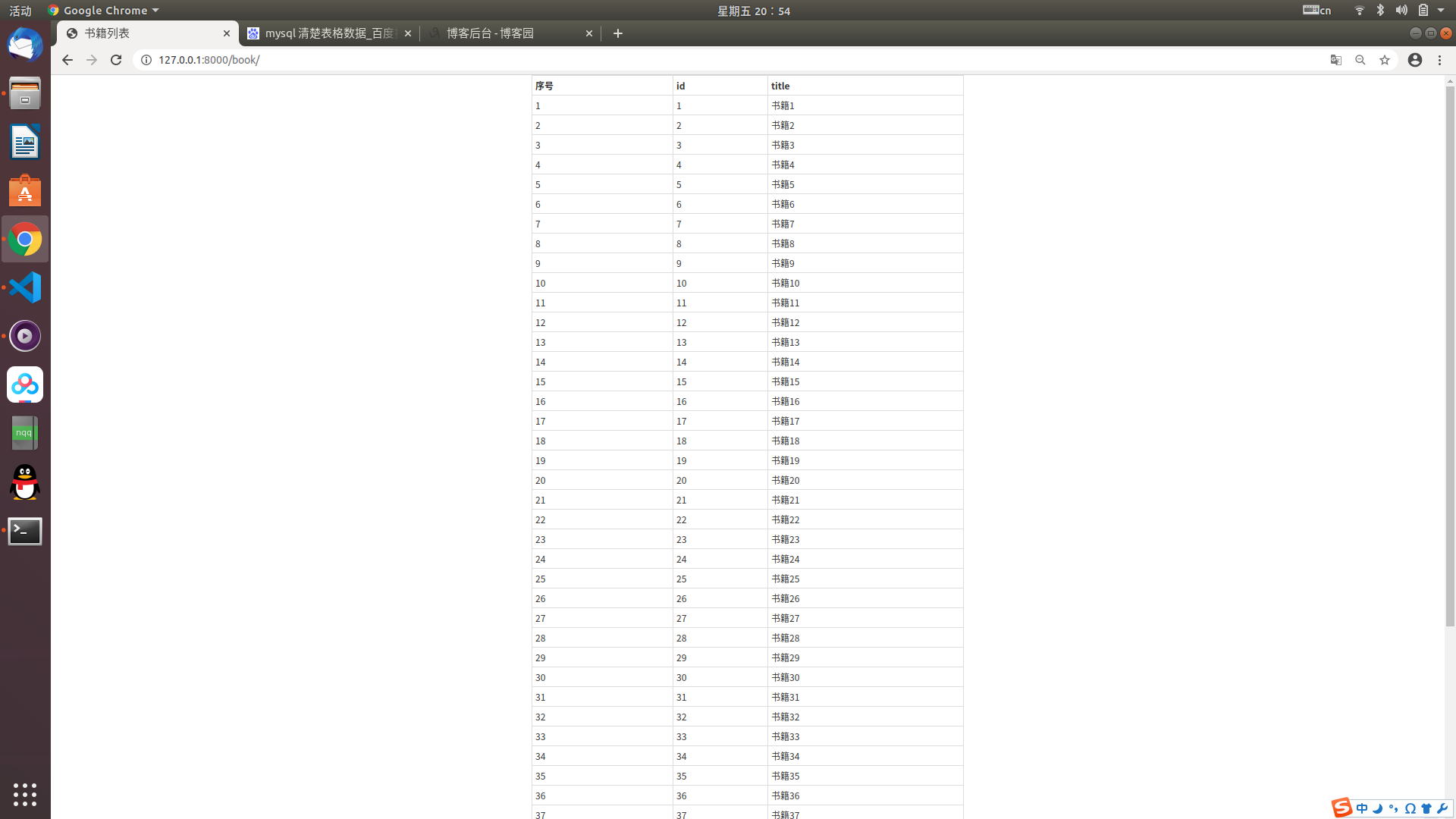
这样明显不符合我们最常见到的状态,所以必须加上分页的效果
我们先基于这50条数据试一下如何达到分页的效果:
显示部分数据
在获取了所有的数据以后,我们可以用切片的方式显示一部分数据
def book(request): all_book = models.Books.objects.all()[0:10] return render(request,'book.html',{'books':all_book})
这样就可以显示了部分的数据
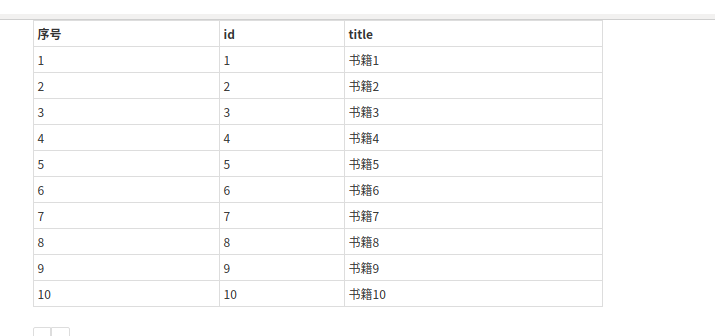
获取页码
页码的获取我们可以通过url里加参数来实现,然后在视图中通过GET方法获取。
URL附带参数http://127.0.0.1:8000/book/?page=1,然后在视图中就可以获取一下对应的参数的值。
def book(request): page_num = request.GET.get('page') print(page_num) all_book = models.Books.objects.all()[0:10] return render(request,'book.html',{'books':all_book})
页码和数据的关系
假设我们每一页上显示10条数据,然后看看怎么排列的
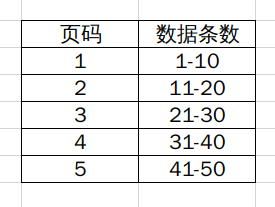
仔细看一下页码和数据之间是有一定的关系的,每一页上开始的数据是(页码-1)×10+1,最后一条的数据是页码*10。然后我们在URL中获取的数据是字符串,需要转换成int(其实这个时候还是要考虑到异常处理的。在这里就先忽略掉吧)
def book(request): page_num = request.GET.get('page') page_num = int(page_num) page_start = (page_num-1)*10+1 page_end = page_num*10 all_book = models.Books.objects.all()[page_start:page_end] return render(request,'book.html',{'books':all_book})
这样就实现了通过URL来显示分页以后的数据了。然后,我们在模板中插入一个最简单的分页组件
分页组件
分页的控件,还是从Bootstrap上找一个最简单的分页效果,把他放在模板中
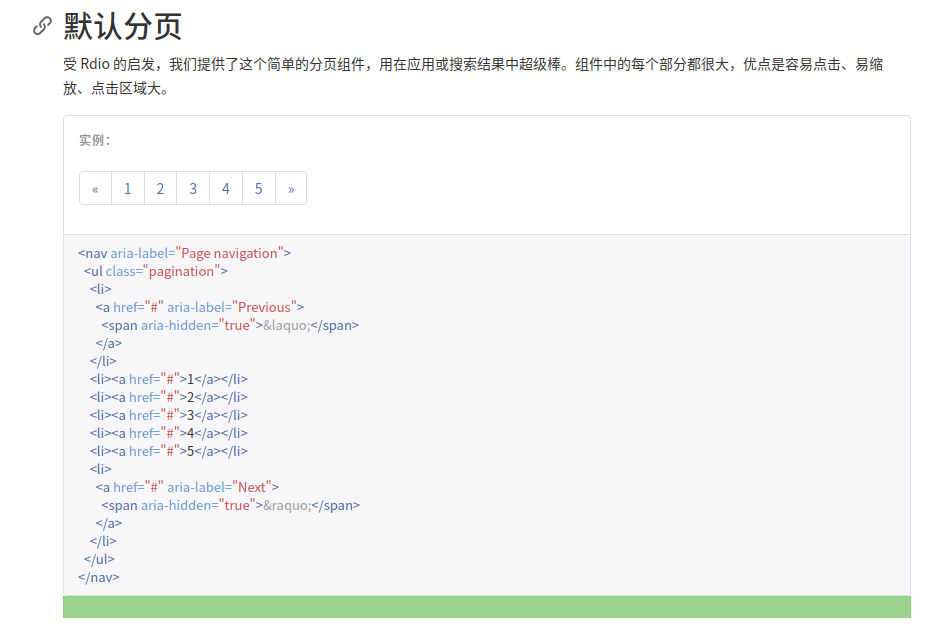
现在这里的组件,是通过a标签来实现页码的切换的,但是模板中还没有对a标签赋链接参数,实现的思路就是在视图中创建一段html代码,然后插到这个模板中,所以就先要修改一下模板的代码,再把上面吗那一段分页的组件添加在table标签后面
<!-- 文件名:book.html --> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>书籍列表</title> <link rel="stylesheet" href="/static/bootstrap/css/bootstrap.min.css"> </head> <body> <div class="container"> <table class="table table-bordered"> <thead> <tr> <th>序号</th> <th>id</th> <th>title</th> </tr> </thead> <tbody> {%for book in books%} <tr> <td>{{forloop.counter}}</td> <td>{{book.id}}</td> <td>{{book.title}}</td> {%endfor%} </tr> </tbody> </table> <nav aria-label="Page navigation"> <ul class="pagination"> <li> <a href="#" aria-label="Previous"> <span aria-hidden="true">«</span> </a> </li> {{page_html}} <li> <a href="#" aria-label="Next"> <span aria-hidden="true">»</span> </a> </li> </ul> </nav> </body> </html>
在视图函数中,就要把这一段分页的HTML代码生成出来,然后推到模板中。注意我们在这里用了个求模运算,因为有可能最后剩了几条数据,还是要把他显示出来的。
总之视图函数就是这样的:
def book(request): page = request.GET.get('page') page_num=10 #每页显示数据条数 page = int(page) totle_num = models.Books.objects.all().count() #ORM方法,获取数据总条数 totle_page,m = divmod(totle_num,page_num) #求模运算,求出页数和最后一页的数据数量 print(totle_page) if m: #求总页数:如果最后一页上的数据数量不为0,则为页数+1 totle_page += 1 print(totle_page) all_book = models.Books.objects.all()[10*(page-1):10*page] html_str = [] for i in range(1,totle_page+1): temp = "<li><a href='/book/?page={0}'>{0}</a></li>".format(i) #format的用法,前面用两个被传值对对象是通过一个变量传值的 html_str.append(temp) page_html = ''.join(html_str) print(page_html) return render(request,'books.html',{'books':all_book,'page_html':page_html})
发现一个问题:

添加进去的并不是li标签而是一段字符串,原因在这里:我们要告诉模板生成的是安全的html代码,所以要在模板那里加上过滤器:
{{page_html|safe}}
这样就好了!
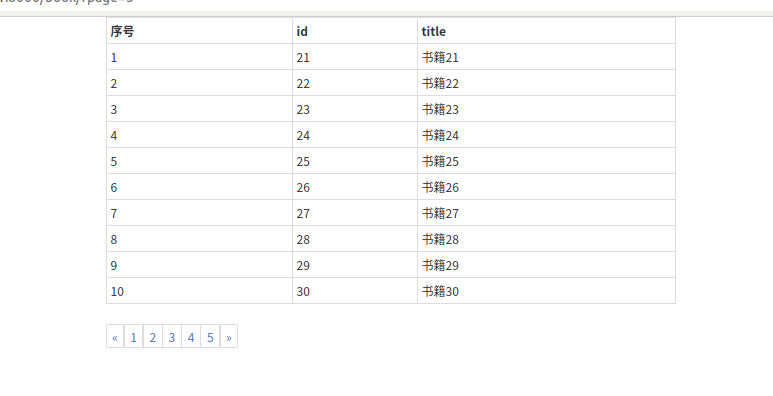
用上面的方法已经实现了最基本的 分页了,但是有一个问题:我们的数据量还是比较少的,如果我们有1000条数据的话会怎么样?我们在数据库里用truncate把刚才的50条数据删除
mysql> truncate app1_books;
然后重新在那个test.py里创建1000条数据,重新访问一下页面,看看成什么样子了!
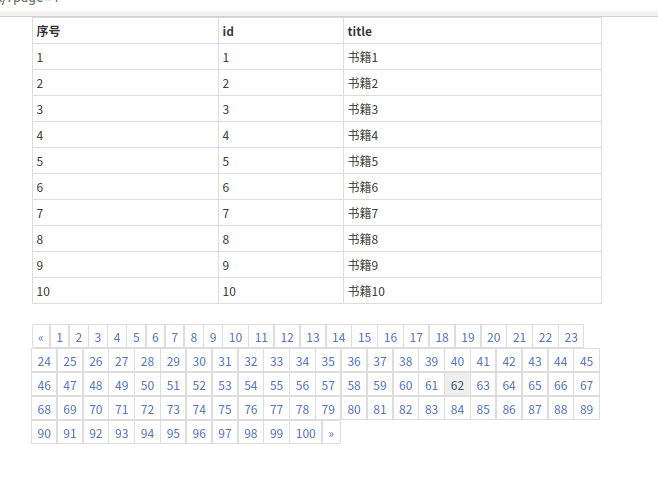
明显和我们平时看到的效果是不同的,那么就需要对刚才的视图函数进行修改了!我们就以博客园的分页效果来看一看是什么形式的

我们先不管最后那个200的页码,一般情况,为了看起来比较美观我们显示的分页标签都是奇数数量的,就可以做到按照中心对中的效果(中间一个,左边5个右边5个,一共11个)
其实也没什么难得,只要是了解了上面的思路,看看下面代码的思路就可以了(注意改了函数的名字,要修改路由)
def book(request): page = request.GET.get('page') page_num=10 #每页显示数据条数 page = int(page) totle_num = models.Books.objects.all().count() #ORM方法,获取数据总条数 totle_page,m = divmod(totle_num,page_num) #求模运算,求出页数和最后一页的数据数量 print(totle_page) if m: #求总页数:如果最后一页上的数据数量不为0,则为页数+1 totle_page += 1 print(totle_page) all_book = models.Books.objects.all()[10*(page-1):10*page] html_str = [] for i in range(1,totle_page): temp = "<li><a href='/book/?page={0}'>{0}</a></li>".format(i) #format的用法,前面用两个被传值对对象是通过一个变量传值的 html_str.append(temp) page_html = ''.join(html_str) return render(request,'book.html',{"books":all_book,"page_html":page_html}) #指定显示分页标签数量的分页方式 def book2(request): page = request.GET.get('page') page = int(page) #当前页码 page_num = 10 #每页显示数量 page_max = 11 #最大页码数 page_half = page_max //2 #中间页码数 page_start = page - page_half page_end = page+page_half books_totle = models.Books.objects.all().count() page_totle,m = divmod(books_totle,page_num) page_totle = page_totle+1 if m else page_totle if page_start <= 1: page_start = 1 page_end = page_max if page_end >= page_totle: page_end = page_totle page_start = page_totle - page_max +1 all_book = models.Books.objects.all()[10*(page-1):10*page] for i in range(page_start,page_end+1): temp = "<li><a href='/book2/?page={0}'>{0}</a></li>".format(i) html_str.append(temp) page_html = ''.join(html_str) return render(request,'book.html',{"books":all_book,"page_html":page_html})
注意里面的这一段代码
if page_start <= 1: page_start = 1 page_end = page_max if page_end >= page_totle: page_end = page_totle page_start = page_totle - page_max +1
定义了超出了最小值和最大值的那一部分,因为最后是通过for循环生成的代码,for循环是顾头不顾腚的,很容易迷糊。
我们前面的方法都是直接点击页码来实现跳转的效果,其实还有一种情况很常见:前后页或者直接跳转首尾页
首尾页的实现
首尾页的实现方法比较简单:我们的分页的html代码是通过一个for循环生成的列表实现的,要实现这个功能就在for循环前后各加一个标签就可以了
def book2(request): page = request.GET.get('page') page = int(page) #当前页码 page_num = 10 #每页显示数量 page_max = 11 #最大页码数 page_half = page_max //2 #中间页码数 page_start = page - page_half page_end = page+page_half books_totle = models.Books.objects.all().count() page_totle,m = divmod(books_totle,page_num) page_totle = page_totle+1 if m else page_totle if page_start <= 1: page_start = 1 page_end = page_max if page_end >= page_totle: page_end = page_totle page_start = page_totle - page_max +1 all_book = models.Books.objects.all()[10*(page-1):10*page] html_str = ["<li><a href='/book2/?page=1'>首页</a></li>"] #跳转首页 for i in range(page_start,page_end+1): temp = "<li><a href='/book2/?page={0}'>{0}</a></li>".format(i) html_str.append(temp) html_str.append("<li><a href='/book2/?page={}'>尾页</a></li>".format(page_totle)) #跳转尾页 page_html = ''.join(html_str) return render(request,'book.html',{"books":all_book,"page_html":page_html})
上下页的实现
上下也的实现也很简单,有两种方法,一种是和前面的首尾页的方法一样,直接把整段li标签嵌套的a标签生成以后填到模板中,还有一种是求出来上一页和下一页的页码,只把这个页码发送到模板中,我比较喜欢第二种方法,这里不放全部的代码,把上面的函数修改一下就可以了。
page_next = page+1 if page<page_totle else page_totle page_last = page-1 if page>1 else 1 print(page,page_next) return render(request,'book.html',{"books":all_book, "page_html":page_html, "page_next":page_next, "page_last":page_last})
因为是直接从上面的函数修改过来的,保持了原函数的缩进,可以忽略!
然后就是模板文件也要大概修改一下
<nav aria-label="Page navigation"> <ul class="pagination"> <li> <a href="/book2/?page={{page_last}}" aria-label="Previous"> <span aria-hidden="true">«</span> </a> </li> {{page_html|safe}} <li> <a href="/book2/?page={{page_next}}" aria-label="Next"> <span aria-hidden="true">»</span> </a> </li> </ul> </nav>
直接把上一页和下一页对应的页码塞进去就行了。注意这里用了三元运算来赋值,留意一下三元运算的格式。
于是乎,前后页和首尾页的效果就实现了

其实上面的这段代码其实是有个小BUG的,因为前面都是满足了可以分出来几页的情况,但是如果数据量不支持能够分这么多页会怎么样呢?
把数据库文件完全删除,然后创建20条数据,因为每页只能显示10条数据,分页只能分2页,看看是不是出问题了
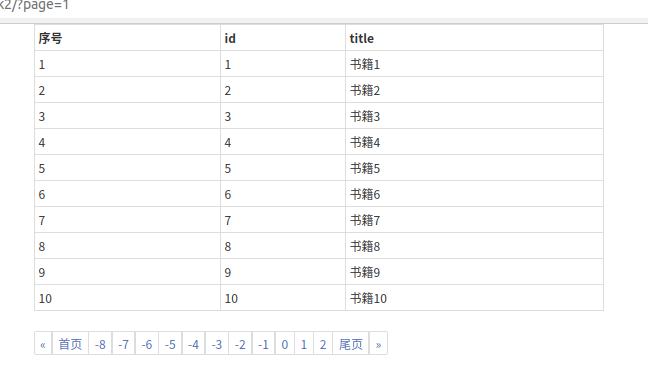
因为我们定义了最大显示的页码数量是11个,但是真实情况是只有2页就完了,那么就不能用这个写死的方法。改一下最大的页码数量就行了,
def book3(request): page = request.GET.get('page') page = int(page) #当前页码 page_num = 10 #每页显示数量 page_max = 11 #最大页码数 books_totle = models.Books.objects.all().count() page_totle,m = divmod(books_totle,page_num) page_totle = page_totle+1 if m else page_totle page_max = 11 if page_totle >page_max else page_totle if page_totle < page_max: page_max = page_totle page_half = page_max //2 #中间页码数 page_start = page - page_half page_end = page+page_half if page_start <= 1: page_start = 1 page_end = page_max if page_end >= page_totle: page_end = page_totle page_start = page_totle - page_max +1 all_book = models.Books.objects.all()[10*(page-1):10*page] print(page_totle,page_start,page_end) html_str = ["<li><a href='/book2/?page=1'>首页</a></li>"] #跳转首页 for i in range(page_start,page_end+1): temp = "<li><a href='/book2/?page={0}'>{0}</a></li>".format(i) html_str.append(temp) html_str.append("<li><a href='/book2/?page={}'>尾页</a></li>".format(page_totle)) #跳转尾页 page_html = ''.join(html_str) page_next = page+1 if page<page_totle else page_totle page_last = page-1 if page>1 else 1 return render(request,'book.html',{"books":all_book, "page_html":page_html, "page_next":page_next, "page_last":page_last})
还是用了一个三元运算
page_max = 11 if page_totle >page_max else page_totle
但是一定要注意这条赋值语句的位置。要先对page_max进行赋值才可以用。
但是还有个问题,现在的页码都是通过a标签跳转的URL获取的,但是我们如果在地址栏输入的page参数不是int类型的字符串呢?程序就报错了,最简单的方法就是对page进行int方法的时候加个异常处理。
page = request.GET.get('page') try: page = int(page) #当前页码 except ValueError as e: page = 1
这样即便出现了输入数据的数据类型不符合要求,还可以处理一下。
同理,当我们输入的值如果超出了所有的页数,也可以再处理一下
page = page if page_totle > page else page_totle
继续升个级
注意观察一下博客园的分页组件的效果

在选中的时候是有个选中的效果的,这个选中效果的实现方法:
就是在for循环中进行一下判断:当page和i相等的时候给li标签加上一个属性就行了
for i in range(page_start,page_end+1): if i != page: temp = "<li><a href='/book2/?page={0}'>{0}</a></li>".format(i) else: temp = "<li class='active'><a href='/book2/?page={0}'>{0}</a></li>".format(i) html_str.append(temp
这样就实现了选中的效果:

如果我们的web页面有很多个都需要这种分页的效果,为了实现程序的复用,我们可以把上面那段分页的代码封装成一个类,然后在视图里进行重复的调用。
先把封装好的代码放下来,再对几个点分析一下
from django.utils.safestring import mark_safe class Page_Cut(): def __init__(self,page,url_prefix,data_totle,data_per_page=10,page_show_num=11): """ :param: page:当前页码 :url_prefix:url前缀 :data_totle:总数据量 :date_per_page:每页显示数据条数,默认值为10 :page_show_num:显示的分页数量,默认值为11 """ self.url_prefix = url_prefix #url前缀 page_totle,m = divmod(data_totle,data_per_page) page_totle = page_totle if not m else page_totle +1 #计算总页码数 self.page_totle = page_totle self.page_show_num = page_show_num if page_show_num < self.page_totle else self.page_totle #显示最大页码数 self.data_per_page = data_per_page page = 1 if page<1 else page page = page_totle if page>page_totle else page self.page = page if page_totle < page_show_num: page_show_num = page_totle page_half = page_show_num // 2 #中间页码数 page_start = page - page_half page_end = page + page_half if page_start <= 1: page_start = 1 page_end = page_show_num if page_end >= page_totle: page_end = page_totle page_start = page_totle - page_show_num +1 self.page_start = page_start self.page_end = page_end @property #静态属性,调用的时候可以省略括号 def ID_start(self): #当前页开始数据ID return (self.page-1) * self.data_per_page @property def ID_end(self): return(10 * self.page) def page_html(self): html_begin = '<nav aria-label="Page navigation"> <ul class="pagination">' last_page = self.page-1 if self.page > 1 else 1 if last_page == 1: html_last = """ <li> <a href="/{0}/?page={1}"> <span aria-hidden="true">«</span> </a> </li>""".format(self.url_prefix,last_page) else: html_last = """ <li> <a href="/{}/?page={}" aria-label="Previous"> <span aria-hidden="true">«</span> </a> </li>""".format(self.url_prefix,last_page) page_cut_html = "<li><a href='/{}/?page=1'>首页</a></li>".format(self.url_prefix) #html开始为跳转首页标签 for i in range(self.page_start,self.page_end+1): page_cut_html += """ <li><a href='/{0}/?page={1}'>{1}</a></li>""".format(self.url_prefix,i) page_cut_html += "<li><a href='/{}/?page={}'>尾页</a></li>".format(self.url_prefix,self.page_totle) html_end = """ <li> <a href="/{0}/?page={1}" aria-label="Next"> <span aria-hidden="true">»</span> </a> </li></ul></nav>""".format(self.url_prefix,self.page_end) page_html = html_begin + html_last + page_cut_html + html_end return mark_safe(page_html)
def func_book(request): page = request.GET.get('page') page = int(page) data_totle = models.Books.objects.all().count() page = pagecut.Page_Cut(page = page,url_prefix = 'book3',data_totle=data_totle) cut_html = page.page_html() print(page.ID_start,page.ID_end) all_book = models.Books.objects.all()[page.ID_start:page.ID_end] print(page.page_start,page.page_end) print(page.page_totle) return render(request,'book3.html',{'books':all_book,'page_html':cut_html})
这里还有一个地方可以修改,我们在视图中直接把url写死了(book3),除此以外还可以使用内置方法直接获取url
path= request.path_info
然后对path进行split就可以了。
构造函数
先看看这个类都定义了几个参数,
因为要实现功能的复用,可以把不同页面要实现分页效果的共用参数提出来
def __init__(self,page,url_prefix,data_totle,data_per_page=10,page_show_num=11): """ :param: page:当前页码 :url_prefix:url前缀 :data_totle:总数据量 :date_per_page:每页显示数据条数,默认值为10 :page_show_num:显示的分页数量,默认值为11 """
可以看出来,必须要的参数就是上面几个:当前的页码,url前缀,数据总量,每页显示的数据量以及一共显示的分页标签数量。有了这几个参数,我们就可以生成一段HTML代码的字符串。最后就把这个字符串返回就好了
mark_safe
我们在前面是把html标签形式的字符串整个发送到模板中进行替换,但是在模板中还要调用safe这个filter,比较麻烦,Django为我们提供了一个方法,对字符串进行处理(页面转义)。处理以后的结果还是字符串,最后把处理以后的字符串直接return就好了。
from django.utils.safestring import mark_safe a = '<a href="www.baidu.com">百度</a>' print(a) b = mark_safe(a) print(b)
上面的代码,变量a传递给模板中的变量以后是要用safe这个filter的,否则浏览器就会按照字符串去渲染,但是b就可以直接传递,浏览器会直接按照标签渲染。
装饰器@property
通过这个装饰器,我们把类中的方法直接变成了属性,在实例化以后调用这个方法的时候可以不用加括号
html字符串的生成
这里就是为了演示如何使用封装的方法来使用,其实在html生成这里还是有值得推敲的地方的,最好的方式是一层层的生成标签,但是上面用的方法是最直接的。但是不利于后期的修改。
