
Redis的使用
今天学习一下Redis的功能以及常用指令
一.Redis的作用
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统,属于一种NoSQL数据库(Not Only SQL),适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序,作为缓存数据库可以完成多进程之间的内存数据共享。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
二.Redis的安装
可以看看这里,讲了Redis的安装方法和环境设置。
在python中,我们需要用pip下载Redis对应的操作模块——redis,在下面分别讲了在python里和linux的shell里Redis的用法。
三.python里Redis的使用
1.直接连接
import redis r =redis.Redis(host='192.168.233.131',port=6379)
但是在使用Redis时,常常伴随的是大量的数据交互,在每次存取数据时都要建立一个socket的链接,就占用了大量的资源。这里就用到了另一种连接方法——连接池
import redis pool = redis.ConnectionPool(host = '192.168.233.131',port = 6379) r = redis.Redis(connection_pool=pool)
三.Redis的数据操作
Redis支持的数据格式操作:
string操作
list操作
set操作
hash操作
sortset操作
由于我们在上面一节里一ing实例化了一个redis连接r,在下面的语法中没有注明的有r.的都是python的语法。
1.string操作
1设置值
r.set(name='key',value='123,ex|px=10,nx|xx=False)\set key value [EX|PX time] [NX|XX]
ex过期时间(s),可用r.setex(key,value,time)或setex keyvalue time替代
px过期时间(ms),可用r.psetex(key,value,time)或psetex keyvalue time替代
nx为True时,当key不存在时执行set操作,也可以用r.setnx(key,value)或setnx keyvalue替代
xx为True时,当key存在时才执行set操作
r.mset({key1:value1,key2:value2...}) / mset key1 value1 key2 value2.... #批量设置值
r.setrange(key,start,end) / setrange key start end #字符串切片设置
r.setbit(key,offiset,value) /setbit key offset value #把对应的位进行位操作
2获取值
r.get(key) / get key #获取key对应的value
r.key() / keys * #获取所有的key
r.getset(key,value) / getset key value #返回key的value并附一个新的值
3.string值操作
r.setbit(key,offiset,value) /setbit key offset value #把对应的位进行位操作
r.incr/decr(key,amount) / incr/decr key #把key对应的值(必须是整形)进行加/减运算,amoun默认为1,在Redis里如果要给加数赋值要用incrby key amount 语句
r.incrbyfloat(key,amount) / incrbyfloat key amount #把key对应的value(必读是浮点型)进行加运算,如果key对应的值为空,则创建运算后的值
r.append(key,value) /append key value #在key对应的value后追加字符串
4.有个比较牛B的用法,我们可以大概了解一下!
2.hash操作
hash的数据类型和python里的dict数据有些类似,可以存储一组关联性较强的数据,每个 hash 可以存储 232 - 1 键值对 。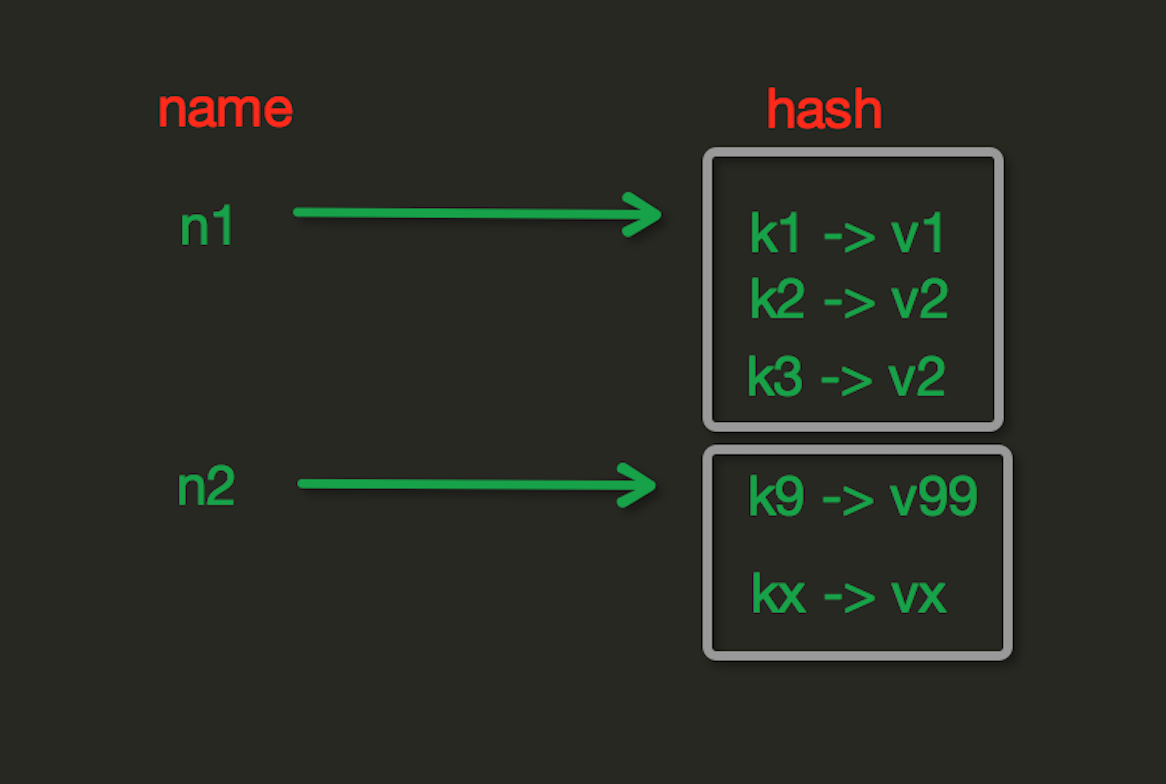
1.设定
r.hset(name,key,value) / hset(name,key,value) #name对应的hash中存储(修改或创建)一个键值对
r.hmset(name,{key1:value1,key2:value2...}) / hmset name key1 key2 #批量设置
2.获取
r.hget(name,key) / hget name key #获取值
r.hmget(name,{key1,key2}) / hmget name key1 key2 #批量获取
r.hgetall(name) / hgetall name #返回name下hash存储的所有键值
r.hkeys(name) / hkeys name #返回name下所有的key
r.hlen(name) / hlen name #返回name中键值对的个数
r.hexists(name,key) / hexists name key #判断name中是否有key的存在(返回值为布尔量)
r.hdel(name,key) / hdel name key #删除name中的key
3.值操作
hincrby[float](name,key,amount) / hincrby[float] name key amount #加操作,同字符串
scan name cursor 关键字 count 按照迭代的方式匹配和关键字匹配的key(可以用*代替),对于超大的数据量比较有用
3.list操作
1.设定
r.lpush(name,value1,value2...) / lpush name value1 value2 #从前端向队列加载数据(取的时候先进后出)
r.rpush(name,value1,value2...) / rpush name value1 value2 #从后端向队列加载数据(取的时候先进后出)
r.l|rpushx(name,value) / l|rpushx name value #只有当name存在时数据进入list
2.获取
r.lrange(name,start,end) / lrange name start end #对list里切片
r.llen(name) / llen name #显示list元素个数
r.lindex(name,Index) / lindex name Index #获取list内索引对应的元素
3.操作
r.linsert(name,'before|after',refvalue,value) / linsert name before|after refvalue value #在refvalue前|后插入value
r.lset(name,Index,value) / lset name Index value #把索引为Index的值更改为value
r.lrem(name,count,value) / lrem name count value #删除list内指定数量的value,如果制定数量超出存在的值,全部删除,如果list内不存在value,返回原list
r.ltrim(name,start,end) / ltrim name start end #list只保留start至end的元素
r.l|rpop(name) / l|rpop name #删除list内左/右边第一个元素并将其返回
r.rpoplpush(name1,name2) / rpoplpush name1 name2 #将name1中最右边元素取出返回并存入name2最左边
r.blpop(name,blocktime) / blpop name blocktime #牛B的作用:把name最右边的元素删除并返回,如果list空了就block,可以等待另外的进程对这个list操作
r.bpoplpush #和rpoplpush的作用基本一致,也是加了bolck,可以多个进程之间操作该list
4.set操作
set就是去重的无序的列表
1.设定
r.sadd(name,value) / sadd name value
2.获取
r.scard(name) / scard name #获取name内元素个数
r.smembers(name) / smembers name #获取name内所有元素(返回值为集合{})由于集合是无序的,不能切片获取
r.srandmember(name,number) / srandmember name number #从name里随机获取number个元素
3.操作
r.sdiff(name1,name2) / sdiff name1 name2 #返回name1中和name2不重复的元素
r.sdiffstore(name1,name2,name3) / sdiffstore name1 name2 name3 #将name2中和name3不重复的元素赋给name1,并返回个数
r.sinter(name1,name2) / sinter name1 name2 #返回name1和name2的交集
r.sinterstore(name1,name2,name3) / sinterstore name1 name2 name3 #将name2和name3的交集存入name1
r.ismember(name,value) / ismember name value #查询value是否在name中
r.spop(name) / spop name #随机删除一个元素
r.srem(name,value) / srem name value #删除指定的元素
r.sunion(name1,name2) / sunion name1 name2 #返回多个集合的并集
r.sunionstore() / sunionstore #用法同sinterstore
r.sscan() #迭代匹配,用法同list内的lscan
5.有序集合
Redis里还有一种数据结构是有序的集合,t它由分数(score)和值(value)组成
1.设定
r.zadd(python的语法着实不知道) / zadd name score member... #score为优先级,member为值
2.获取
r.zcard(name) / zcard name #获取元素个数
r.zcount(name,min,max) / zcount name min max #获取name中优先级从min到max的个数
r.zrange(name,start,end,withscore=) / zrange name start end withscore #对集合切片获取(加上withscore带分数获取)
r.zrank(name,value) / zrank name value #返回value在name的排名(从0开始)
r.zscore(name,value) / zscore name value #返回name的分数
3.操作
r.zrem(name,value) / zrem name value #删除value
r.zremrangebyrank(name,start,end) / zremrangebyrank name start end #按排名删除指定范围
r.zremrangebysrcoe #用法同上条,按分数区间删除
r.zinterstore(dest,keys={name1,name2},aggregate=) / zinterstore dest count name1 name2 aggregate 对集合比较相同的value,把他们的分数进行操作后存在dest(在Redis里要先指定被操作集合的个数count),aggregate包含sum,max,min,就像两个集合是两门学科的分数,元素就是名字对应分数,就可以计算个人总分数
6.其他的语法
r.flushall() / flushall 删除所有的key
