
Python之线程与进程
今天我们来了解一下Python的线程和进程的管理机制
首先,我们要了解下线程跟进程的概念:
线程(Thread)是操作系统能够进行运算调度的最小的单位,是一堆cpu的指令。他被包含在进程中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个i安城,每条线程用来执行不同的任务。
进程(Process)程序不能够单独运行,只有将程序加载到内存中,有系统为他分配资源才能够运行。而这种执行的程序就是进程。也就是说进程就是一堆线程的集合。
一个软件程序运行时要以一个整体的形式暴露给OS管理,里面包含了对各种资源的调用,内存的分配、网络接口的调用等,对各种资源管理的集合就可以称为进程。
我们还要有一些概念:
1.进程不具备执行的条件,他只是资源的集合。进程要有行为,必须先创建一个线程,这个线程时用来表述进程的执行的行为的。
2.线程的工作方式:举个例子,假设我要看一本书,看一会儿我要休息一下,只要记住了页码,行数和字数(上下文),在下回还能接着断点继续看。这时候又有一个人要看这本书,他也看了一半,也是记录了这三个值,我们两个就可以分时的复用这一本书。同理,CPU在运行的时候,只要记住了上下文,就可以通过在多个程序间不停的切换,就可以给我们一种CPU在同时处理多个任务的假象。而这个上下文就是线程。
这是个用线程的最简单的案例。


1 import threading,time 2 def test(n): 3 print('in threading %s'%n) 4 time.sleep(3) 5 print('thread %s is finish'%n) 6 t1 = threading.Thread(target=test,args=('t1',)) 7 t2 = threading.Thread(target=test,args=('t2',)) 8 t1.start() 9 t2.start() #这两个是用的多线程 10 test('t1') 11 test('t2') #直接运行
运行一下,可以发现用多线程跟直接调用函数的区别。在程序一开始,调用的两个函数就同时并发了,而分别调用的是在1执行完成后再执行第二个。
还有一种用类定义线程的方法,不过这个方法不太常用!
1 import threading 2 import time 3 class Mythread(threading.Thread):#要继承threading.Thread的属性,并重构 4 def __init__(self,n): 5 super(Mythread,self).__init__() 6 self.n = n 7 8 def run(self): #用类的方式定义时必须把函数名定位run 9 print('in thread %s.'%self.n) 10 time.sleep(1) 11 print('thread %s is finished! '%self.n) 12 13 test1 = Mythread('t1') 14 test2 = Mythread('t2') 15 test1.start() 16 test2.start()
多线程
了解了线程,我们现在要看看多线程。
首先我们试一试用for循环启动多个线程,并计算程序运行时间
1 import threading,time 2 def test(n): 3 print('in thread:%s.'%n) 4 time.sleep(2) 5 print('thread %s is finished'%n) 6 start_time = time.time() 7 for i in range(50): 8 t = threading.Thread(target=test,args=(i,)) 9 t.start() 10 stop_time = time.time() 11 print('totletime:%s'%(stop_time-start_time))
运行后发现totletime值不对啊!并且在totletime打印完成2秒后剩余线程还在执行。
in thread:45. in thread:46. in thread:47. in thread:48. in thread:49. totletime:0.010995626449584961 thread 0 is finished thread 1 is finished thread 2 is finished thread 4 is finished
显然主线程没有等子线程的执行,原因是主程序也是一个线程,主线程和其启动的子线程是并行的关系,不会等带子线程是否执行完毕。所以如果需要主线程等待子线程的等待结果时,需要用join将子线程加入主线程。
我们试一下最简单的那个线程程序段
1 import threading,time 2 def test(n): 3 print('in threading %s'%n) 4 time.sleep(3) 5 print('thread %s is finish'%n) 6 t1 = threading.Thread(target=test,args=('t1',)) 7 t2 = threading.Thread(target=test,args=('t2',)) 8 t1.start() 9 t2.start() 10 t1.join() #这里把t1加入主线程,运行时主线程会等t1的执行 11 print('in main thread')
运行一下,就能发现效果。为了能更深刻的理解他的意义,我们将t1和t2中sleep的时间调整的不一致,可以看看各个线程是怎么工作的
1 import threading,time 2 def test(n,sleep_time): 3 print('in threading %s'%n) 4 time.sleep(sleep_time) 5 print('thread %s is finish'%n) 6 t1 = threading.Thread(target=test,args=('t1',2)) 7 t2 = threading.Thread(target=test,args=('t2',4)) 8 t1.start() 9 t2.start()#t1和t2同时启动,但t2的休眠时间比t1长 10 t1.join() 11 print('in main thread')
in threading t1 in threading t2 thread t1 is finish in main thread thread t2 is finish
我们回到刚才的那个程序中,我们启动了50个线程,join50次可是不现实的,也不能在for循环内
t.start()
t.join()
这样整个循环就成了串行的了,就改变了程序整体结构。所以我们需要创建个临时列表,把所有的线程加在列表中,就像这样搞:
1 import threading,time 2 def test(n): 3 print('in thread:%s.'%n) 4 time.sleep(2) 5 print('thread %s is finished'%n) 6 start_time = time.time() 7 thread_obj = [] #定义临时列表 8 for i in range(50): 9 t = threading.Thread(target=test,args=(i,)) 10 t.start() 11 thread_obj.append(t) #把线程加在列表内 12 for i in thread_obj: 13 i.join() 14 stop_time = time.time() 15 print('totletime:%s'%(stop_time-start_time))
注意的是,for循环启动的第一个线程可不是主线程,我们可以用这个指令检查当前的线程。
1 print(threading.current_thread()) #显示当前线程 2 print(threading.active_count()) #统计活跃线程个数
这里还要有个额外的知识:现在的CPU已经标定了线程数,启动较多的线程后需要cpu在各个上下文间不断切换,并不能提高程序的效率,反而使机器便慢。像socket server就是这样的(2.7版好像还限制了线程数量),同时有多个客户端连接时候一定比一个客户端连接的时候要慢。
这里需要插播一条新的知识:GIL——全局解释器锁(global interpreter lock)。
python在89年创建的时候并没有多核的CPU,所以每次也只能执行一个线程。可是随着多核CPU和多线程任务的兴起,python代码在执行过程中就存在一个问题。
pyhton创建线程是通过C语言的接口,要执行这条线程时需要通过C语言的解释器。python不能控制线程的执行,只能调用。比方说有个变量A,有四个线程要先后对他进行加一的读写,但是在多线程作业的时候会发生什么呢?四个线程读取A的值,线程1执行完毕后将值返回给A,而线程2可能读取的是A原先的值。python并不能控制哪条线程先执行,为了避免数据出错,python解释器就出现了这种全局解释器锁。而Java和C++是自己实现的线程,就没有这种限制。
我们可以通过这副网上的图来了解CPU,线程和GIL的工作方式。
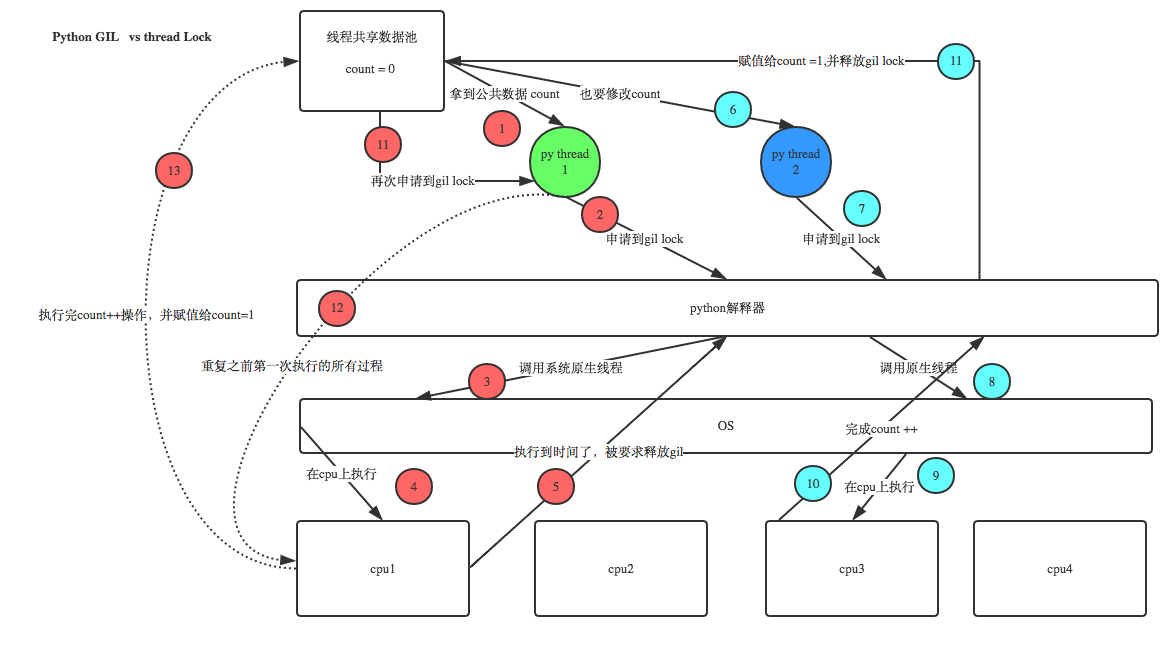
这里还有个文档可以看一下:GIL的说明文档(提取码egs1)
也就是说python的多线程是假的多线程,这就是python(这里只说Cpython,PyPy是没有GIL的,Jpython也没有)的先天缺陷。
插播完毕
守护线程
我们在主线程下定义一些子线程,在不用join的时候主线程不会等待子线程完毕,两个没有依赖关系。我们还可以把子线程变成守护线程,主线程在结束的时候不考虑这些守护线程是否结束。程序结束只等待主线程(和非守护线程)而不会等待这些守护线程。比方socketserver每建立一个新链接时就会分配一个新线程。把这个线程设置成守护线程,每次主线程停止后直接就停止了,不会等待这些子线程是否执行完毕。守护线程就像主线程雇佣的奴隶一样,主线程一旦挂了,守护线程就跟着殉葬了!
1 import threading,time 2 def test(n): 3 print('in thread %s'%n) 4 time.sleep(1) 5 print('thread %s is finish'%n) 6 for i in range(50): 7 t = threading.Thread(target=test,args=('t-%s'%i,)) 8 t.setDaemon(True) #设置线程为守护线程,必须在start前 9 t.start() 10 print('in main thread ,totle thread number:',threading.active_count())
这里没有加join,主线程在完结的时候是不在乎守护线程的死活的,看下运行结果
in thread t-48 in thread t-49 in main thread ,totle thread number: 51
Process finished with exit code 0
在主线程完毕的时候,子线程还没结束,50个子线程加一个主线程刚好51个。如果不用守护线程呢?如果不加join,主线成会等着子线程结束后关闭。
线程锁(互斥锁Mutex)
Python中一个进程内包含的线程是共享内存的,这就存在对数据重复调用时的冲突。我们在这里定义全局变量num,用多线程进行对num加一,
1 #_*_coding:utf-8 _*_# 2 import threading,time 3 num = 0 4 t_obj = [] 5 def test(): 6 global num 7 time.sleep(2) 8 num += 1 9 for i in range(50): 10 t = threading.Thread(target=test,args=()) 11 t.start() 12 t_obj.append(t) 13 for t in t_obj: 14 t.join() 15 print('num',num)
注意这里的运行环境要在linux(还不能是centOS)的python2下,否则就复现不了这个问题了。(据说ubuntu或IOS可以,没试过)。我这个问题也没有试出来,结论应该会比最终要求值小一点。python3好像已经对这种情况优化了。
CPU在执行一个线程时,不是每个线程执行到底。那样显得效率太低。在python2.7中是每100条指令(不是python的指令)。
所以线程在同时修改一份数据的时候,必须加锁(互斥锁mutex)。
1 import threading,time 2 num = 0 3 lock = threading.Lock() 4 t_obj = [] 5 def test(): 6 lock.acquire() #获取锁 7 global num 8 num += 1 9 lock.release() #释放锁 10 for i in range(50): 11 t = threading.Thread(target=test,args=()) 12 t.start() 13 t_obj.append(t) 14 for t in t_obj: 15 t.join() #这里的join必须有,否则主程序执行完时可能有些子线程未执行完毕 16 print('num',num)
要注意一点,在使用互斥锁的时候一定要注意在锁内部不能有类似sleep类的指令,加锁以后程序就变成串行的,这条线程完成后才进行下一条线程,程序就非常慢了。
递归锁(RLock)
很少的时候需要我们用到锁的嵌套,就是递归锁(RLock)。这里有段程序就是用了递归锁。
1 import threading,time 2 def test1(): 3 print('in test1') 4 lock.acquire() 5 global num1 6 num1 += num1 7 lock.release() 8 return num1 9 def test2(): 10 print('in test2') 11 lock.acquire() 12 global num2 13 num2 += num2 14 lock.release() 15 return num2 16 17 def test3(): 18 lock.acquire() 19 res = test1() 20 print('between 1 and 2') 21 res2 = test2() 22 lock.release() 23 print(res,res2) 24 25 num1 ,num2 = 0,0 26 lock = threading.RLock() 27 for i in range(10): 28 t = threading.Thread(target= test3) 29 t.start() 30 while threading.active_count() != 1: #等待所有线程执行完毕,相当于join的作用 31 print(threading.active_count()) 32 else: 33 print('all thread is done!')
我们可以大致的了解一下,有三个函数,函数3调用了函数1和2,三个函数内都加了锁。启动了10个线程执行函数3.
值得注意的一点,这里用了一个while循环,循环查询活动的线程数,效果跟join是一样的。
信号量(Semphore)
互斥锁里只允许了1个线程更改数据,而Semphore是同时允许一定数量的线程同时更改数据
1 import threading,time 2 def run(n): 3 semaphore.acquire() #获取信号量 4 time.sleep(1) 5 print('run the threrad:%s\n'%n) 6 semaphore.release() 7 num = 0 8 semaphore = threading.BoundedSemaphore(5)#同时允许5个线程访问数据 9 for i in range(20): 10 t = threading.Thread(target=run,args=(i,)) 11 t.start() 12 while threading.active_count()!=1: 13 pass 14 else: 15 print('-----all threads done--------')
注意我们把信号量定成5,就是一次可以有5个线程同时访问数据,但是不是5个完成再进5个,是只要有一个完了就再进一个,就像去洗手间一样,有5个坑,蹲了5个人,只要有一个人出来就可以有另外一个补进去。像mysql线程池之类的就用的上。注意在python3中使用信号量时要和锁配合使用。
事件(event)
事件就像触发器一样,常用的方法有这几个:
event = threading.Event() #实例化事件 event.wait() #等待标志位 event.set() #标志位置1 event.clear() #标志位置0
看看是怎么用的
1 import threading 2 event = threading.Event() 3 event2 = threading.Event() 4 def test1(): 5 n = 10 6 while n>5: 7 n=int(input('start>>>')) 8 event.set() 9 def test2(): 10 print('wait for trig...\n') 11 event.wait() 12 print('start DAQ...') 13 14 t2 = threading.Thread(target=test2,) 15 t2.start() 16 t1 = threading.Thread(target=test1,) 17 t1.start()
起两个线程,一个用事件等待触发,另外一个不停的循环获取值,当输入的数小于5,启动采集。
再举个例子吧,有两个车道在等一个红绿灯(这里应该做成十字路口,但程序比较复杂不太好演示,就做成一个路口等红绿灯吧),然后就有三个线程,一个红绿灯,两个车道。
1 import threading,time 2 event = threading.Event() #设置事件。 3 def lighter(): 4 count = 0 5 while True: 6 if count >20 and count < 30: 7 event.clear() 8 print('\033[41;1mred light on...\033[0m') 9 elif count >30: 10 event.set() 11 count = 0 12 else: 13 print('\033[42;1mgreen light on...\033[0m') 14 time.sleep(0.5) 15 count += 1 16 def cross(name): 17 event.set() #启动时先把事件启动 18 while True: 19 if event.is_set(): 20 print('cross %s past!'%name) 21 time.sleep(1) 22 else: 23 print('cross %s is waiting...'%name) 24 event.wait() 25 print('green light on,cross%s past'%name) 26 27 way1 = threading.Thread(target=cross,args=('to south',)) 28 way1.start() 29 way2 = threading.Thread(target=cross,args=('to north',)) 30 way2.start() 31 light = threading.Thread(target=lighter,) 32 light.start()
