

jetson-nano环境配置
目录
基本环境配置
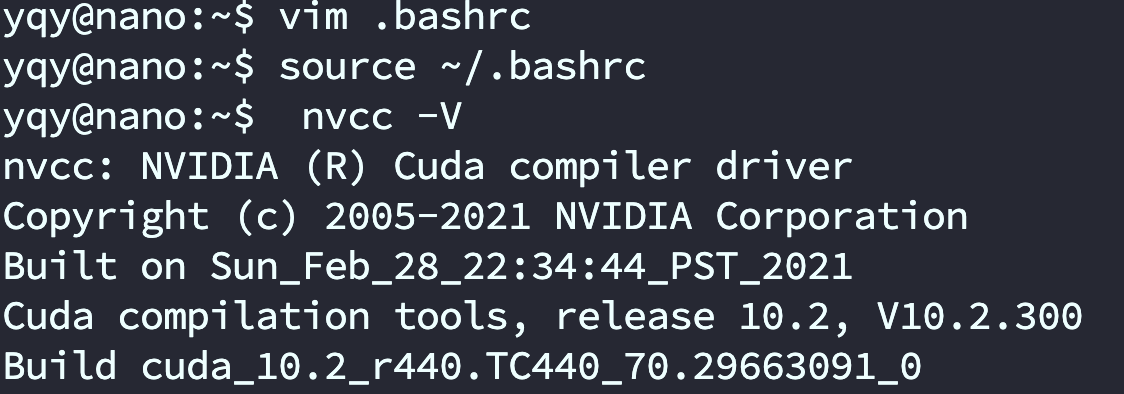
检查nvcc
jetson nano是原装了CUDA的,但是需要用户导入环境变量(导入相关的路径)才可以使用,只有环境变量导入成功后,方可在命令行使用 nvcc -V
sudo vim .bashrc
在最后添加这三行
#选择一个即可
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda/bin:$PATH
export PATH=/usr/local/cuda-10.2/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存后退出,执行 source ~/.bashrc,使得环境变量生效。
在命令行输入 nvcc -V 如果正常输出,说明CUDA路径配置成功
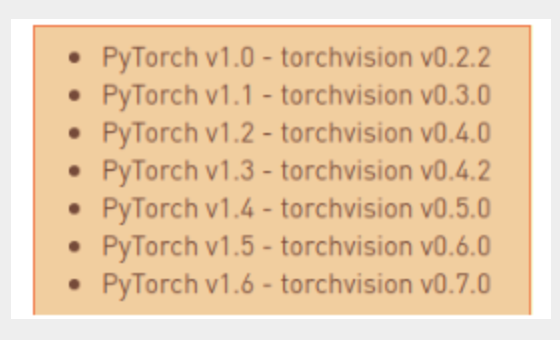
安装torch和vision(可忽略)
安装好后测试如图:
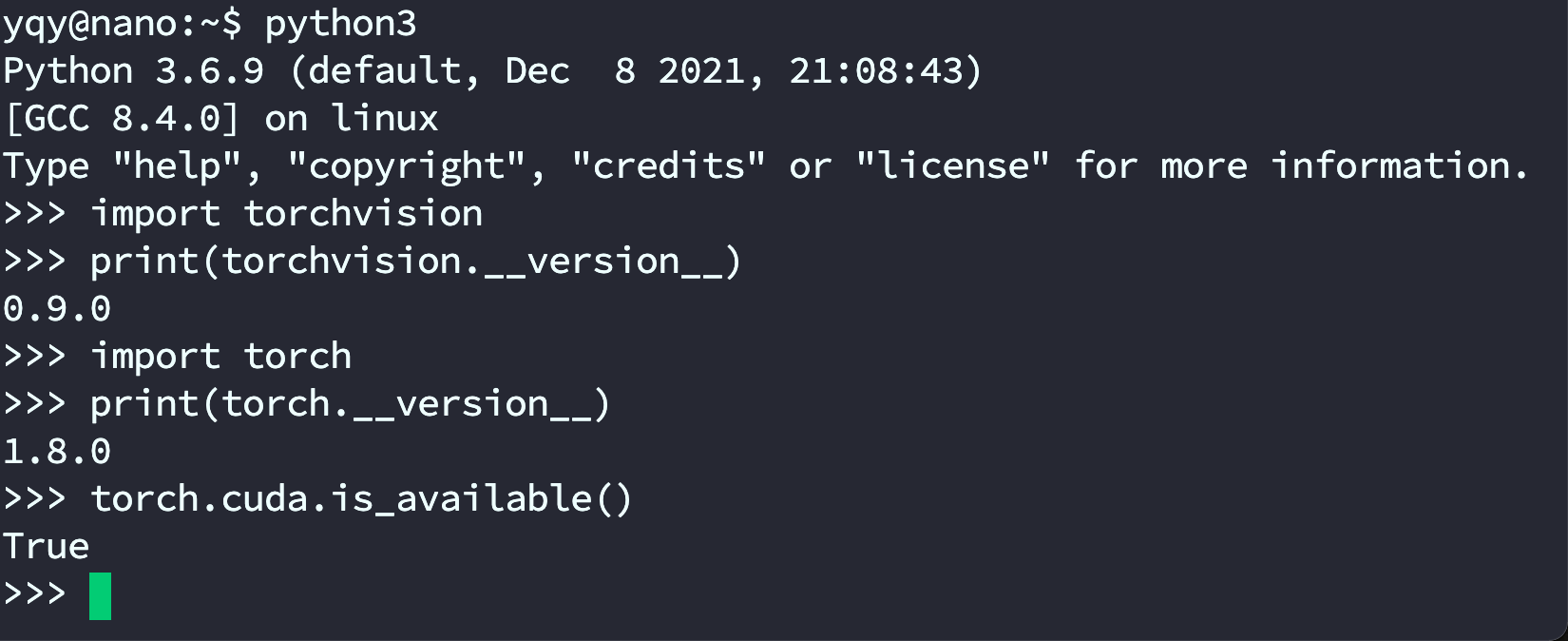
安装pytorch,首先CUDA的步骤得过一下可以看到nvcc -V
安装pytorch跟CUDA的版本要对应
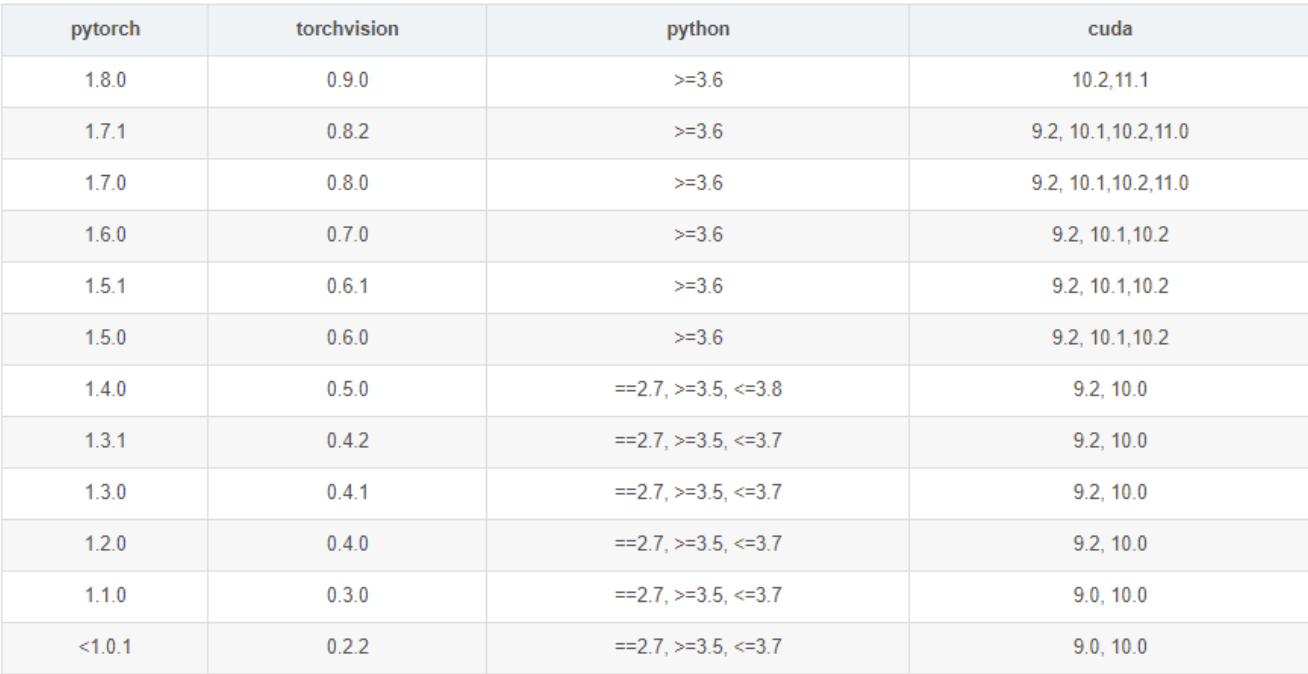
网上找了个1.6.0的安装包通过winscp上传到jetson后离线安装下,该离线包可以到资料5、常用库和模型中获取
sudo pip3 install torch-1.6.0a0+b31f58d-cp36-cp36m-linux_aarch64.whl
sudo pip3 install torchvision
sudo pip install boto3
终端输入python3进入到python3的运行环境中测试下,import torch,我遇到的报错是ImportError:libopenblas.so.0:无法打开共享对象文件或目录,看了下这个教程:https://www.cnpython.com/qa/77454
尝试安装了OpenBlas系统库问题解决了
sudo apt-get install libopenblas-dev
到python环境中
import torch
print(torch.version)
查看安装的版本
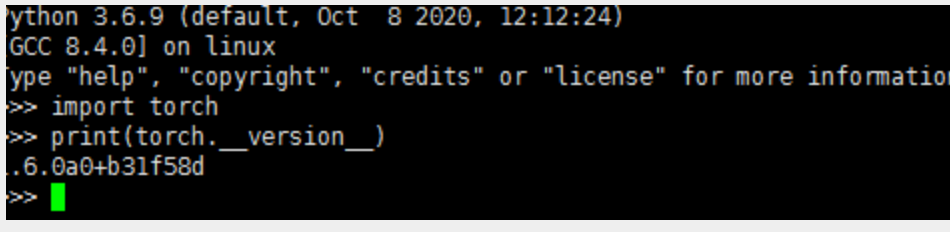
接下来继续在python3环境中测试下pytorch的功能
from future import print_function
import torch
x = torch.rand(5, 3)
print(x)
输出
tensor([[0.3380, 0.3845, 0.3217],
[0.8337, 0.9050, 0.2650],
[0.2979, 0.7141, 0.9069],
[0.1449, 0.1132, 0.1375],
[0.4675, 0.3947, 0.1426]])
另外,要检查你的GPU驱动程序和CUDA是否启用,并通过PyTorch访问,运行以下命令返回是否启用CUDA驱动程序
import torch
torch.cuda.is_available()
测试完毕后接下来再安装torchvision,根官网介绍,pytorch1.6吻合的torch版本为0.7.0
sudo apt-get install libjpeg-dev zlib1g-dev
git clone --branch v0.7.0 https://github.com/pytorch/vision torchvision
cd torchvision
export BUILD_VERSION=0.7.0
sudo python3 setup.py install
注意:安装可能会确实一些文件,这个可以安装相应的文件来解决,例如笔者遇到的是确实一下三个文件所以按了一下三个包

sudo apt install libavcodec-dev
sudo apt install libavformat-dev
sudo apt install libswscale-dev
重新sudo python3 setup.py install
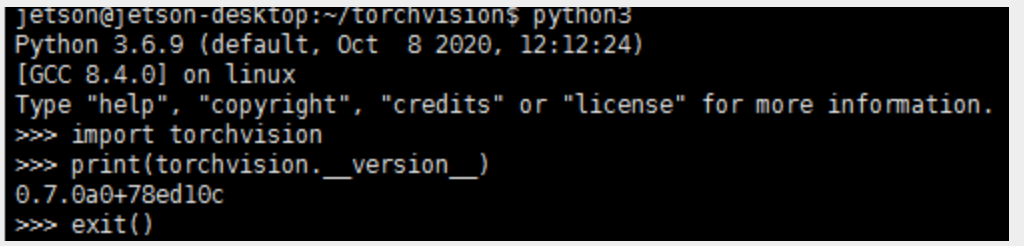
到python环境中输入下代码可以查看版本是否对应
import torchvision
print(torchvision.version)
jetson nao其他配置
更新镜像源
apt
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo vim /etc/apt/sources.list.bak
ggVG 全选
dG 删除
- 源:
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main multiverse restricted universe
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main multiverse restricted universe
sudo apt-get update //更新
pip
sudo apt-get install python3-pip python3-dev
sudo apt-get install python-pip python-dev
- pip换源
sudo mkdir .pip #创建隐藏文件夹
ls -a #查看所有文件
cd .pip #进入文件夹
sudo touch pip.conf
sudo vim pip.conf
- 源:
[global]
timeout = 6000
index-url = http://pypi.doubanio.com/simple/
trusted-host = pypi.doubanio.com
docker
cat /etc/issue #查看ubantu版本
查看Ubuntu系统版本号
根据Ubuntu的版本号,配置相关的源镜像。跳转到源文件所在的目录
cd /etc/apt/
可以试用文件编辑工具打开sources.list文件
sudo gedit /etc/apt/sources.list
直接用以下内容替换 sources.list文件中的所有内容即可。
deb https://mirrors.ustc.edu.cn/ubuntu-ports/ bionic main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb https://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse
更新了源文件之后,保存退出
sudo apt-get update
安装pytorch和torchvison
-
版本要对应
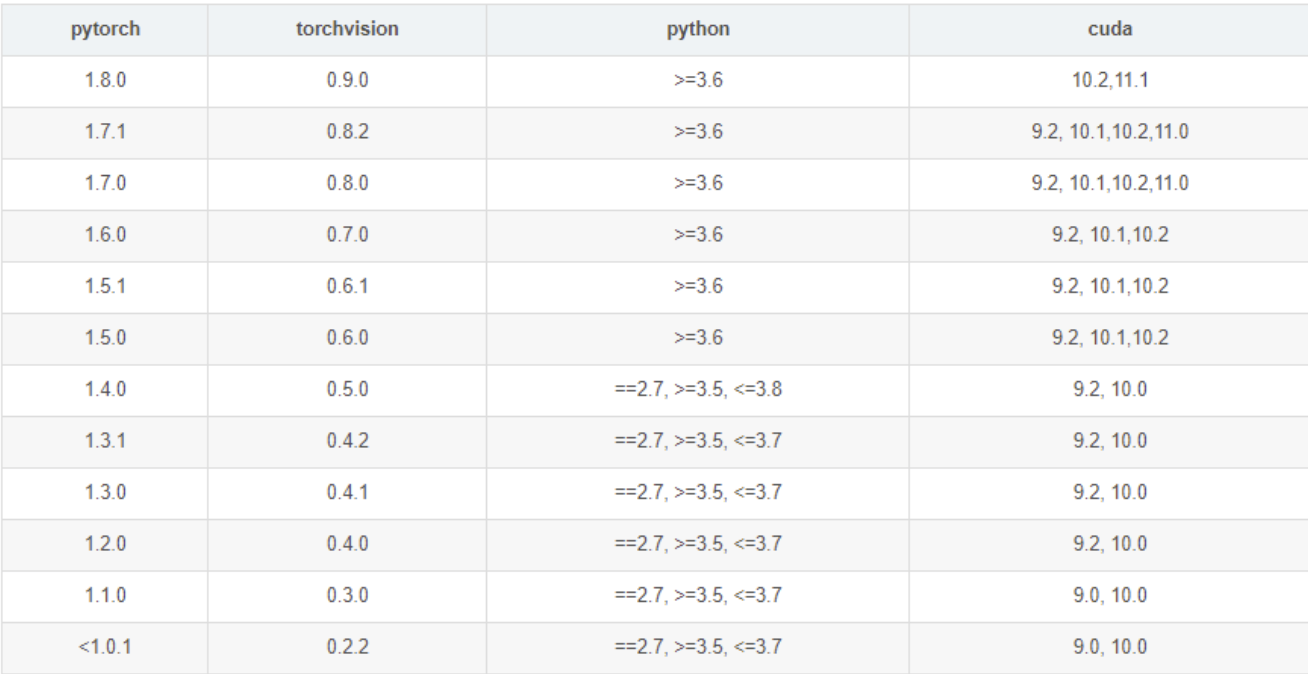
-
按照官方教程输入以下命令
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
pip3 install numpy torch-1.8.0-cp36-cp36m-linux_aarch64.whl # (按照自己torch1.8.0包的下载路径修改,此过程较慢)
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
cd torchvision
export BUILD_VERSION=0.9.0
python3 setup.py install --user #时间较长
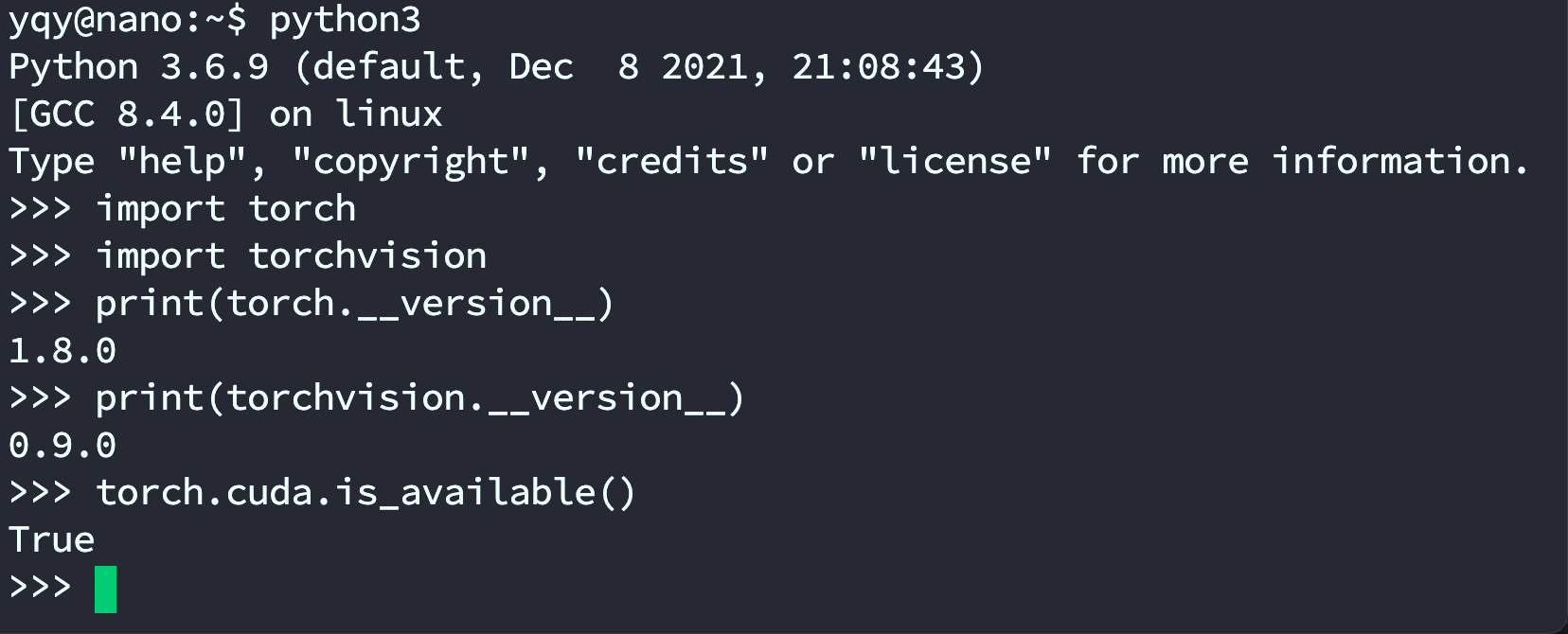
- 检查环境
python3
import torch
import torchvision
print(torch.__version__)
print(torchvision.__version__)
torch.cuda.is_available()
miniforge包管理(选)
‼️此内容为可非必要配置,因为jetson是arm版本无法直接安装anaconda环境,如果需要在jetson上安装anaconda可以接着往下看,若不需要,请跳过
miniforge简介
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。搞深度学习的应该都十分熟悉anaconda,但是NVIDIA Jetson Xavier NX是arm架构的,anaconda及其精简版miniconda并不支持arm64架构。现在主流的CPU架构分为Intel的x86/x64架构和ARM的ARM/ARM64两种,平常用的电脑大部分都是x86/x64的(苹果除外),Xavier使用的是ARM64,所以很多在x86/x64上能用的的东西到了它这里就不能用了。这一点请谨记,如果你在Jetson上遇到什么奇奇怪怪的例如“No such file or directory”之类的问题,第一时间要考虑是不是版本不是ARM64的版本。
在ARM64上的anaconda替代品是miniforge,miniforge与miniconda的区别在于miniforge的下载通道是conda-forge,其他基本没什么不同。
安装miniforge
-
我下载的是
Miniforge-pypy3-4.11.0-0-Linux-aarch64.sh,,代表适用于arrch64架构下的Linux系统。(ARM64对应32位和64位分为arrch32和arrch64) -
进入到miniforge的sh文件所在目录,右键打开Terminal,输入以下命令进行安装:
sh Miniforge-pypy3-4.10.3-3-Linux-aarch64.sh
- 安装完毕后,添加环境变量,否则会出现
bash:conda Command not found的错误。顺便提一下vim编辑器按a是进入编辑模式,编辑完毕后按ESC退出编辑模式,再输入:wq!是保存并退出。
# 编辑环境变量
vim ~/.bashrc
# 增加环境变量, 将<username>换成你的用户名
export PATH=/home/<username>/miniforge-pypy3/bin:$PATH
# 激活环境变量
source ~/.bashrc
# 显示(base)
source activate
- 更换清华源
conda config --prepend channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --prepend channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
安装pytorch、torchvision
安装新的虚拟环境
- 这是在minigorge上安装的pytorch,若不想在虚拟环境上安装。可以参考PyTorch for Jetson - version 1.10 now available - Jetson & Embedded Systems / Jetson Nano - NVIDIA Developer Forums
conda create -n pytorch python=3.6 #创建环境
conda activate pytorch #激活环境
- 其他操作(看即可)
conda deactivate #退出环境
conda remove -n pytorch --all
conda info -e #查看已有环境
激活成功会换名字

pytorch1.8
直接输入命令安装PyTorch,pip3是python3的pip,如果没装,就换成pip。
pip3 install -U future psutil dataclasses typing-extensions pyyaml tqdm seaborn
wget https://nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl -O torch-1.8.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.8.0-cp36-cp36m-linux_aarch64.whl
如果网络不好的话,也可以先把PyTorch的whl文件下载下来,NVIDIA官方网址是:https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-9-0-now-available/72048
- issue:
如果出现Illegal instruction (core dumped)的错误,这是由于numpy 1.19.5和OpenBLAS冲突引起的,修改其中一项即可。选择以下两种做法之一:
(1)降低numpy版本
pip3 install -U "numpy==1.19.4"
(2)设置OpenBLAS
vim ~/.bashrc
加入
export OPENBLAS_CORETYPE=ARMV8
然后激活.bashrc
source ~/.bashrc
orchvision v0.9.0
查看jetson信息 (jtop)
sudo pip3 install jetson-stats
sudo jtop
风扇自动控制
git clone https://gitee.com/yin-qiyu/jetson-fan-ctl.git
cd /jetson-fan-ctl #进入文件夹
sudo apt install python3-dev
sudo ./install.sh
现在你的风扇就可以按照温度自动调整运行速度了
风扇的一些设置在/etc/automagic-fan/config.json目录下。
vim /etc/automagic-fan/config.json
{undefined
“FAN_OFF_TEMP”:20,
“FAN_MAX_TEMP”:50,
“UPDATE_INTERVAL”:2,
“MAX_PERF”:1
}
~
~
增加Swap分区大小
- 先查看初试交换分区大小:
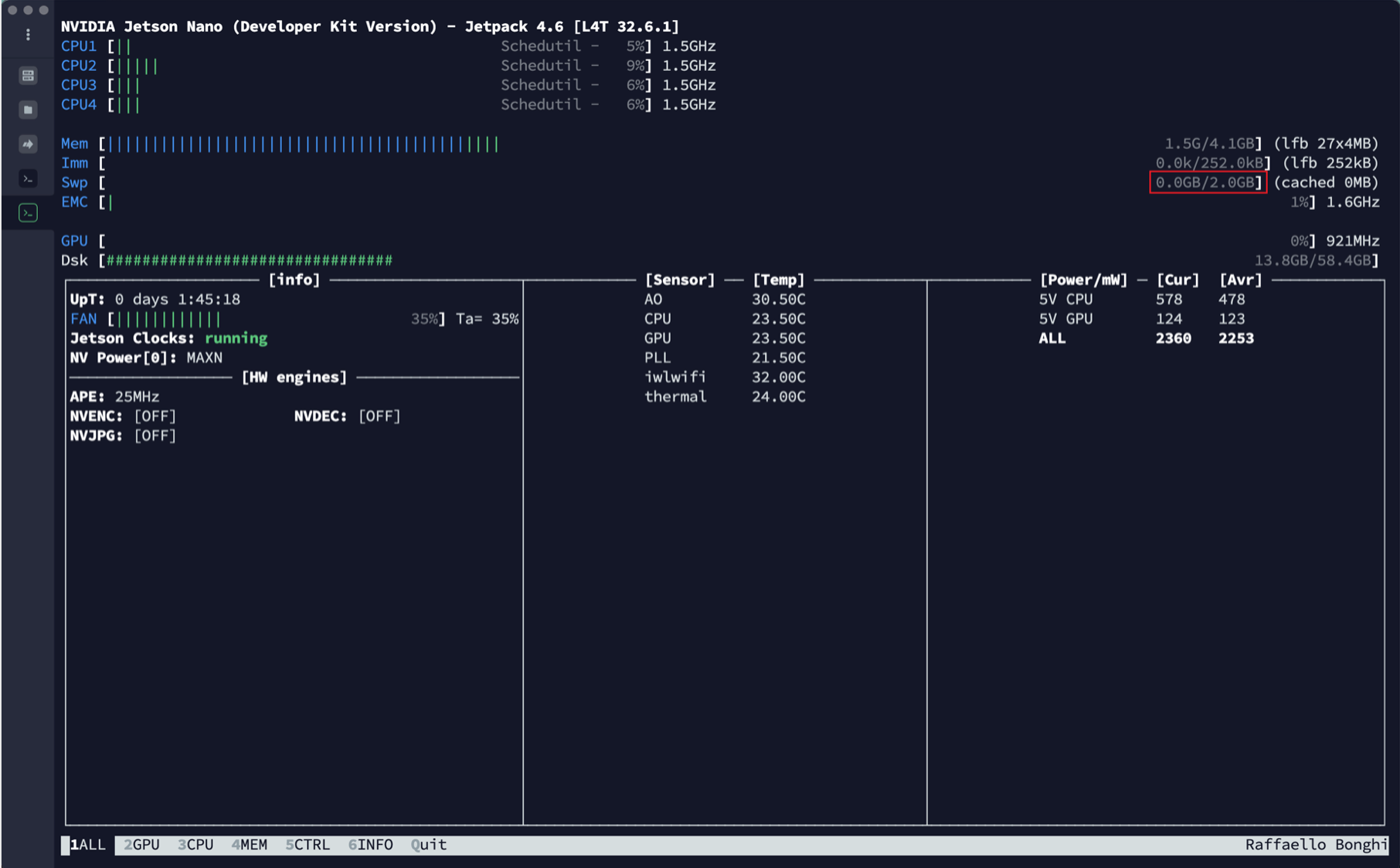
- 生成swapfile文件操作如下
#1)新增swapfile文件大小自定义
sudo fallocate -l 6G /var/swapfile
#2)配置该文件的权限
sudo chmod 600 /var/swapfile
#3)建立交换分区
sudo mkswap /var/swapfile
#4)启用交换分区
sudo swapon /var/swapfile
- 设置为自动启用swapfile
sudo bash -c 'echo "/var/swapfile swap swap defaults 0 0" >> /etc/fstab'
设置成功后:
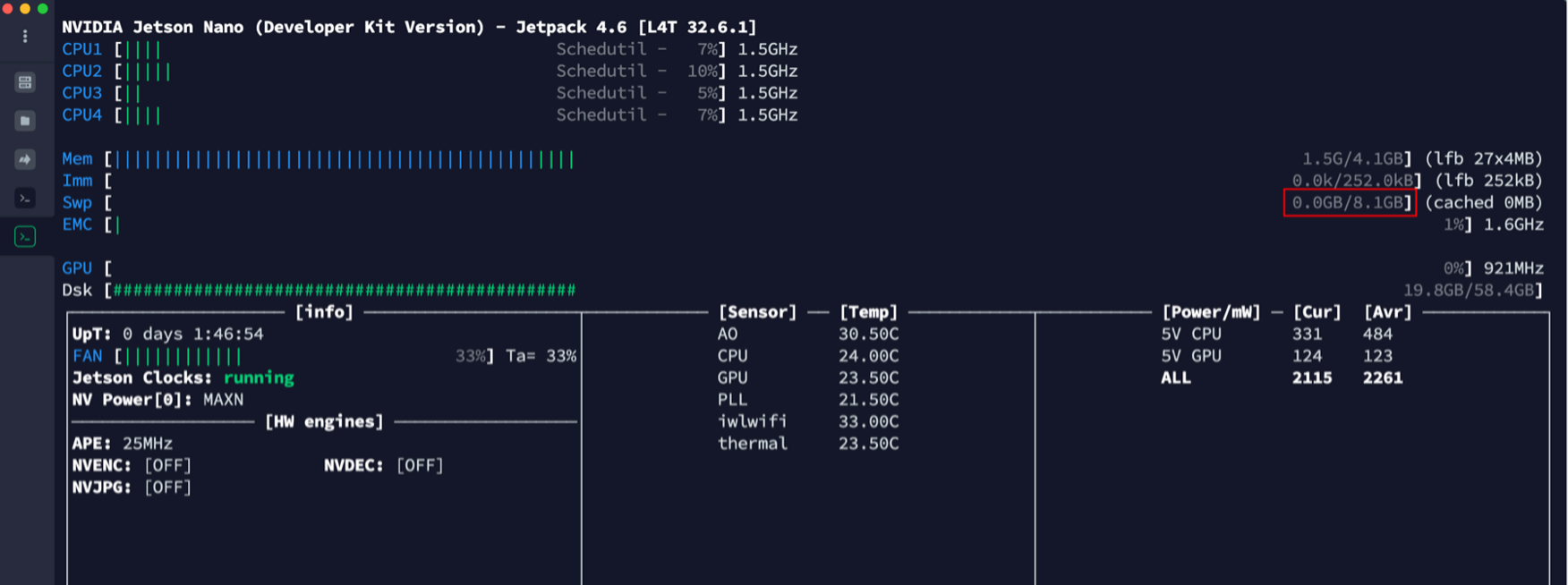
nomachine(虚拟网络控制台)
官网:NoMachine - Free Remote Desktop For Everybody
-
主机上正常安装
-
jetson上
-
下载好对应版本用SFTP传到jetson
-
sudo dpkg -i nomachine_7.6.2_3_arm64.deb
-
-
在同一局域网下即可连接
VNC(虚拟网络控制台)
- 编辑文件
sudo vim /usr/share/glib-2.0/schemas/org.gnome.Vino.gschema.xml
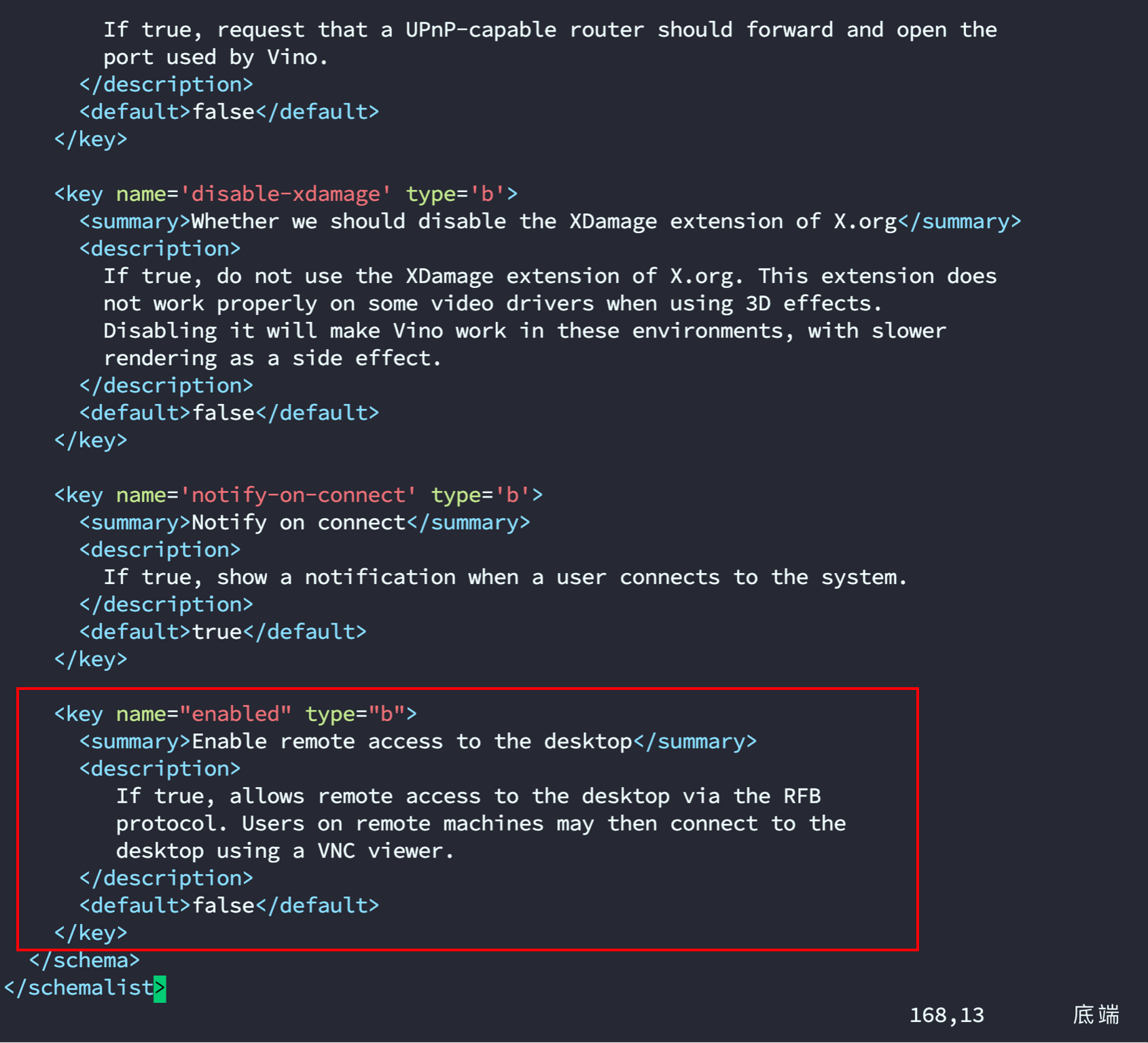
- 滑到文末添加下段内容格式如图片所示
<key name="enabled" type="b">
<summary>Enable remote access to the desktop</summary>
<description>
If true, allows remote access to the desktop via the RFB
protocol. Users on remote machines may then connect to the
desktop using a VNC viewer.
</description>
<default>false</default>
</key>
- 编译文件
sudo glib-compile-schemas /usr/share/glib-2.0/schemas
完成以上步骤,正常来说就可以打开桌面共享的图标了。

设置好后(不设置也可以)
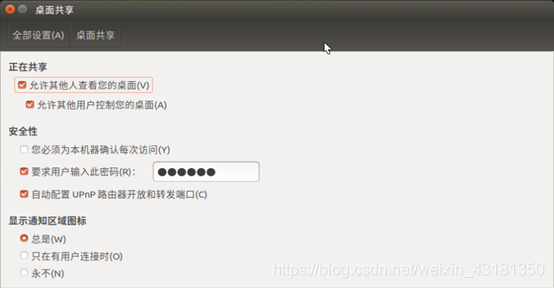
- 配置vnc设置
gsettings set org.gnome.Vino prompt-enabled false
gsettings set org.gnome.Vino require-encryption false
- 设置密码(可以不要)
gsettings set org.gnome.Vino authentication-methods "["vnc"]"
gsettings set org.gnome.Vino vnc-password $(echo -n "请输入你的密码"|base64)
- 配置vnc自启
gsettings set org.gnome.Vino enabled true
mkdir -p ~/.config/autostart
vi ~/.config/autostart/vino-server.desktop
添加下面内容
[Desktop Entry]
Type=Application
Name=Vino VNC server
Exec=/usr/lib/vino/vino-server
NoDisplay=true
- 重启生效
sudo reboot
-
-
配置jetson nano的ip和密码即可连接
-
- 遇到下图提示输入电脑账户魔密码即可(是你主机的密码,不是jetson的)
-
TensoRT
TensoRT介绍
模型加速越来越成为深度学习工程中的刚需了,最近的CVPR和ICLR会议中,模型的压缩和剪枝是受到的关注越来越多。毕竟工程上,算法工程师的深度学习模型是要在嵌入式平台跑起来,投入应用的。在模型的推理(inference)过程中,计算速度是很重要的。比如自动驾驶,如果使用一个经典的深度学习模型,很容易就跑到200毫秒的延时,那么这意味着,在实际驾驶过程中,你的车一秒钟只能看到5张图像,这当然是很危险的一件事。所以,对于实时响应比较高的任务,模型的加速时很有必要的一件事情了。
如果你使用英伟达的产品,比如PX2,那么在平台上部署模型投入应用,很多时候就需要用到专门的模型加速工具 —— TensorRT。
TensorRT下的模型是在做什么?
TensorRT只负责模型的推理(inference)过程,一般不用TensorRT来训练模型的哈。
TensorRT能加速模型吗?
能!根据官方文档,使用TensorRT,在CPU或者GPU模式下其可提供10X乃至100X的加速。本人的实际经验中,TensorRT提供了20X的加速。
TensorRT为什么能提升模型的运行速度?
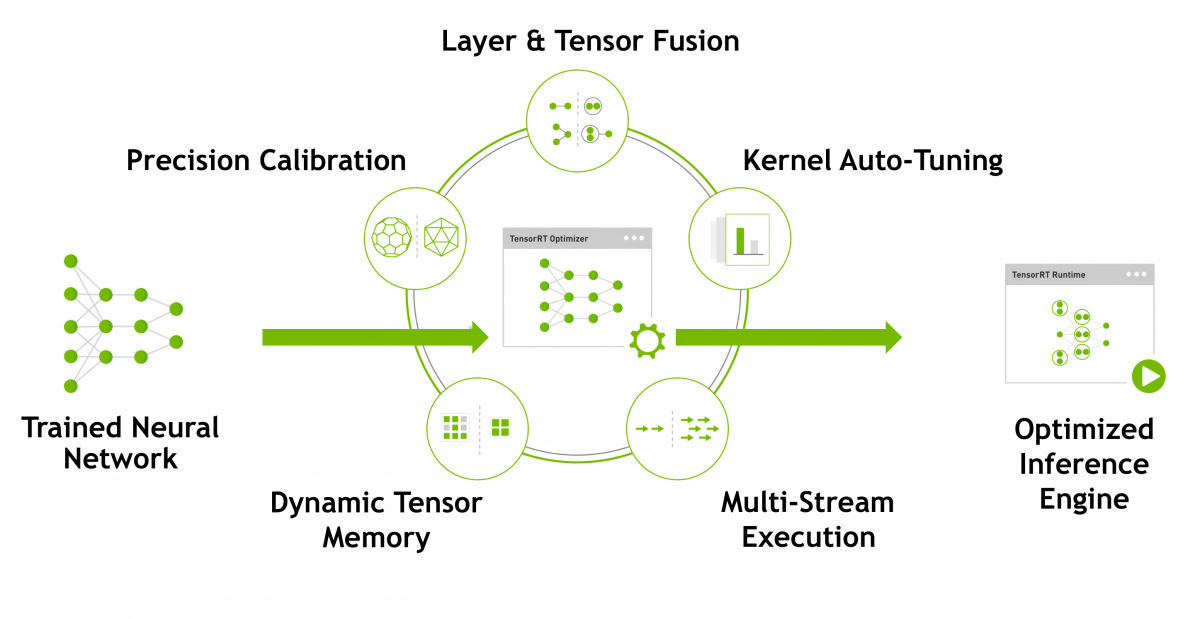
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。
- TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。
- TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,自然就推出了针对自己GPU的加速工具TensorRT。一个深度学习模型,在没有优化的情况下,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。
检查自带TensorRT环境(选)
cd /usr/src/tensorrt/samples
sudo make #编译大约7分钟
../bin/sample_mnist

jetson inference库安装(选)
sudo apt update
sudo apt autoremove
sudo apt upgrade
sudo apt install cmake
mkdir ~/workspace
cd workspace
git clone https://gitee.com/weikun-xuan/jetson-inference.git
cd jetson-inference
git submodule update --init
start
一、获取源码
首先打开终端运行如下代码:
sudo apt-get update
sudo apt-get install git cmake libpython3-dev python3-numpy
git clone --recursive https://gitee.com/weikun-xuan/jetson-inference.git
上面仓库源我全都自己换了,下载会比GitHub快很多。
二、换源
进入到tools文件下:
cd jetson-inference/tools
换下源,依次运行以下代码(均在tools文件下):
1)模型下载国内源:
sed -in-place -e 's@https://nvidia.box.com/shared/static@https://bbs.gpuworld.cn/mirror@g' download-models.sh
2)pytorch国内源:
sed -in-place -e 's@https://nvidia.box.com/shared/static@https://bbs.gpuworld.cn/mirror@g' install-pytorch.sh
sed -in-place -e 's@https://github.com/pytorch/vision@https://gitee.com/vcan123/pytorch@g' install-pytorch.sh
sed -in-place -e 's@https://github.com/dusty-nv/vision@https://gitee.com/vcan123/dusty-nv@g' install-pytorch.sh
三、编译安装
在jetson-infernce文件下执行如下操作:
mkdir build
cd build
cmake ../
接着就会出现:
模型包安装
此步为安装模型包,本人建议【全部取消】,不然会有些慢,之后我们可以去官网手动下载。
我们继续:
pytorch安装
安装pytorch。这时应该只有一个for python 3.6版本,选上然后ok。
完成后还是在build文件下依次执行如下操作:
make
sudo make install
sudo ldconfig
完成。
安装jupyter和jetcam
- 安装nodejs和npm
pip3 install --upgrade pip #更新pip
sudo apt install nodejs npm
但是用直接用上面这个命令安装后的版本是比较低的后续要安装jupyterlab插件可能会报错,用一下版本可以查看,至少要12.3.0版本的node
node -v
npm -v
安装n模块,用这个模块来更新或者指定安装node的版本
sudo npm install -g n
先说明下这个模块的功能,一下命令了解下先,不用操作
清除npm缓存:npm cache clean -f
安装n模块:npm install -g n
安装官方稳定版本:n stable
安装最新官方版本:n latest
安装某个指定版本:n 11.6.0
查看已安装的node版本: n
查看当前node版本:node -v
删除指定版本:n rm 7.5.0
好的,了解完n模块的功能后来安装对应版本的node,也可以安装最新版的例如以下,
sudo n latest
安装好后,node -v 查看下版本,如果版本没有变,那么可以尝试重启下,如果还是没有变,执行
sudo n
会出现一个画面,可以看到我们安装过的node版本名,例如我们这里是v15.0.1,通过上下方向按键控制光标选择这个版本,然后回车镜像安装,然后查看下版本,如果还是没有变,一般再重启下就可以了。
- 安装jupyterlab:(警告忽略,失败多次执行即可)
sudo pip3 install jupyter jupyterlab
sudo jupyter labextension install @jupyter-widgets/jupyterlab-manager
sudo jupyter labextension install @jupyterlab/statusbar
生成相应配置文件:(如果某个文件报权限问题,可以尝试用sudo chmod 777赋予权限)
jupyter lab --generate-config
设置进入notebook的密码(这里会要设置两次,第二次为确认输入的密码):
jupyter notebook password
当第一次登录使用notebook时需要输入你在这里设置的密码才能进入,请务必记住的当前设置的密码!
设置开机自启动jupterlab,create_jupyter_service.py文件
运行create_jupyter_service.py文件产生jupyter_service.service文件
python3 create_jupyter_service.py
然后将产生的该服务文件移动至系统服务
sudo mv nano_jupyter.service /etc/systemd/system/nano_jupyter.service
使能该服务
sudo systemctl enable nano_jupyter.service
手动开启该服务
sudo systemctl start nano_jupyter.service
- 安装jetcam
JetCam是用于NVIDIA Jetson的易于使用的Python相机界面。使用Jetson的Accelerated GStreamer插件可与各种USB和CSI摄像机配合使用。轻松读取图像作为numpy数组image = camera.read()。设置相机以running = True将回调附加到新框架。JetCam使在Python中创建AI项目的原型变得容易,尤其是在JetCard中安装的Jupyter Lab编程环境中。
接下来开始安装:
git clone https://github.com/NVIDIA-AI-IOT/jetcam
cd jetcam
sudo python3 setup.py install
详细的使用即函数可以到https://github.com/NVIDIA-AI-IOT/jetcam查看
darknet框架(选)
git clone https://github.com/AlexeyAB/darknet.git #下载darknet框架
cd darknet
sudo vim Makefile #修改Makefile
- 将
Makefile的前三行修改一下
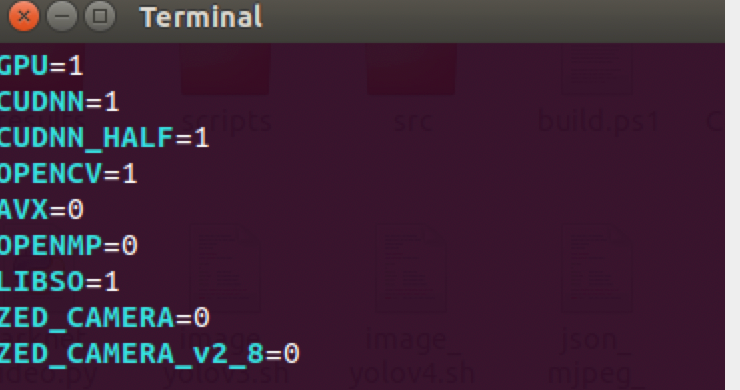
- 和如图所示的nvcc位置(若前面配置了环境变量则无需这一步操作)

-
修改好猴按
esc左下角出现冒号后wq保存退出 -
在darknet路径下编译
make -j4
编译完成如图

在命令行下输入 ./darknet

在yolo官网下载yolov4和yolov4-tiny的权重文件放入文件夹
#Yolov4图片的检测
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg # 简写版
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/dog.jpg # 完整版
#Yolov4-tiny图片的检测
./darknet detect cfg/yolov4-tiny.cfg yolov4-tiny.weights data/dog.jpg # 简写版
./darknet detector test cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights data/dog.jpg # 完整版
# 改变检测阈值
# 默认情况下,YOLO仅显示检测到的置信度为.25或更高的对象。您可以通过将-thresh标志传递给yolo命令来更改此设置。
#例如,要显示所有检测,您可以将阈值设置为0.1:
./darknet detect cfg/yolov4-tiny.cfg yolov4-tiny.weights data/dog.jpg -thresh 0.1
#Yolov4摄像头实时检测方法:
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights /dev/video1
#Yolov4-tiny摄像头实时检测方法:
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights /dev/video1
#Yolov4视频的检测(github下来的data里面并没有该视频文件,需要用户自行上传要检测的视频文件到data文件夹下)
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights data/123.mp4
#Yolov4-tiny视频的检测
#Yolov4-tiny视频的检测(github下来的data里面并没有该视频文件,需要用户自行上传要检测的视频文件到data文件夹下)
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights data/xxx.mp4
- 若要调用csi摄像头需要gstream的支持
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
解决Jetson Nano使用CSI摄像头在Darknet下实时检测绿屏_
Nvidia Jetson Nano 安装 GStreamer
sudo add-apt-repository universe
sudo add-apt-repository multiverse
sudo apt-get update
sudo apt-get install gstreamer1.0-tools gstreamer1.0-alsa gstreamer1.0-plugins-base gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav
sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-good1.0-dev libgstreamer-plugins-bad1.0-dev
配置GStreamer管道
首先说一下思路:由于yolov3本身不支持csi摄像头,因此需要通过GStreamer来对csi摄像头获取的视频进行预处理,然后提交给yolov3进行识别判定,而这一过程重点就是GStreamer管道的配置,以下是博主的管道配置
# 仅适用于jetson-nano运行yolov4-tiny demo。注意请在darknet的文档页下打开terminal输入
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
原版:
./darknet detector demo ok/new.data ok/yolov4-tiny-new.cfg ok/yolov4-tiny-new_last.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
口罩
./darknet detector demo cfg/obj.data cfg/yolov4-tiny-masks.cfg yolov4-tiny-obj_last.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
yolo:
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
sudo add-apt-repository universe
sudo add-apt-repository multiverse
sudo apt-get update
sudo apt-get install gstreamer1.0-tools gstreamer1.0-alsa gstreamer1.0-plugins-base gstreamer1.0-plugins-good gstreamer1.0-plugins-bad gstreamer1.0-plugins-ugly gstreamer1.0-libav
sudo apt-get install libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libgstreamer-plugins-good1.0-dev libgstreamer-plugins-bad1.0-dev
官方:
./darknet detector demo ok/new.data ok/yolov4-tiny-new.cfg ok/yolov4-tiny-new_last.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
// 仅适用于jetson-nano运行yolov3-tiny demo。注意请在darknet的文档页下打开terminal输入
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"
./darknet detector demo cfg/coco.data cfg/yolov4-tiny.cfg yolov4-tiny.weights "nvarguscamerasrc ! video/x-raw(memory:NVMM), width=1280, height=720, format=NV12, framerate=30/1 ! nvvidconv flip-method=2 ! video/x-raw, width=1280, height=720, format=BGRx ! videoconvert ! video/x-raw, format=BGR ! appsink"

