使用Pytorch进行单机多卡分布式训练
一. torch.nn.DataParallel ?
pytorch单机多卡最简单的实现方法就是使用nn.DataParallel类,其几乎仅使用一行代码net = torch.nn.DataParallel(net)就可让模型同时在多张GPU上训练,它大致的工作过程如下图所示:
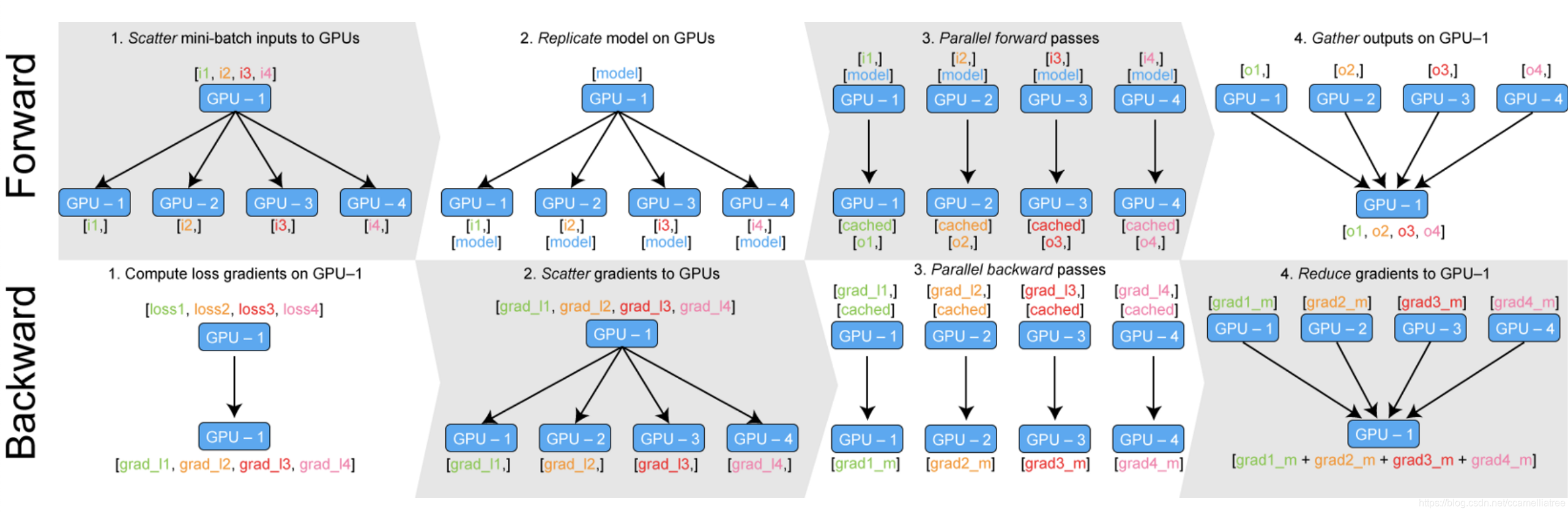
在每一个Iteration的Forward过程中,nn.DataParallel都自动将输入按照gpu_batch进行split,然后复制模型参数到各个GPU上,分别进行前传后将得到网络输出,最后将结果concat到一起送往0号卡中。
在Backward过程中,先由0号卡计算loss函数,通过loss.backward()得到损失函数相于各个gpu输出结果的梯度grad_l1 ... gradln,接下来0号卡将所有的grad_l送回对应的GPU中,然后GPU们分别进行backward得到各个GPU上面的模型参数梯度值gradm1 ... gradmn,最后所有参数的梯度汇总到GPU0卡进行update。
注:DataParallel的整个并行训练过程利用python多线程实现
由以上工作过程分析可知,nn.DataParallel有着这样几个无法避免的问题:
- 负载不均衡问题。gpu0所承担的任务明显要重于其他gpu
- 速度问题。每个iteration都需要复制模型且均从GPU0卡向其他GPU复制,通讯任务重且效率低;python多线程GIL锁导致的线程颠簸(thrashing)问题。
- 只能单机运行。由于单进程的约束导致。
- 只能切分batch到多GPU,而无法让一个model分布在多个GPU上。当一个模型过大,设置batchsize=1时其显存占用仍然大于单张显卡显存,此时就无法使用DataParallel类进行训练。
因此官方推荐使用torch.nn.DistributedDataParallel替代nn.DataParallel.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)