2、Question about RDD、分区、stage、并行计算、集群、流水线计算、shuffle(join??)、task、executor
2、Question about RDD、分区、stage、并行计算、集群、流水线计算、shuffle(join??)、task、executor
RDD是spark数据中最基本的数据抽象,task是spark的最小代码执行单元?数据不是代码的资源???那为什么RDD又是分区存储?节点中又是对分区(父分区进行流水线计算)?RDD只能转换操作,但是RDD可以分成多个分区,而且这些分区可以被保存到集群中不同的节点,可在不同的节点进行并行计算,那RDD还是高度受限的吗?在一个节点的中以流水线形式计算窄关系的父节点,那RDD还是高度受限的吗?将RDD分成stage,又是为了什么?分配资源吗?优化效率吗?哈希分区和范围分区?shuffle又是什么???task也又是什么???
流水线计算?是transformation??那就是进行数据的筛选??不对,机器学习算法和交互式数据挖掘使用的目的是什么?理解这个能够理解父分区中的流水计算!
shuffle操作中的reduce task需要跨节点去拉取(为什么要跨节点拉取,因为RDD的不同分区都是在不同的节点储存,但宽关联是子RDD的一个分区就需要父RDD的所有分区,肯定要跨节点。而窄关联的子RDD中的一个分区只是有父RDD的一个分区就可,所以不需要跨节点,但是join?????前提组成子RDD的分区的父分区都在同一个节点???不在的join就是shuffle????join分为宽依赖和窄依赖,如果RDD有相同的partitioner,那么将不会引起shuffle,因此我们可以对RDD进行Hash分区。分别对A和B用同一个函数进行Partition,比如按照首字母进行Partition,那么A和B都可以分成26个Partition,并且A1只需要和B1进行join,A1不需要和B剩下的25个Partition进行join,这样就大大的减少了join次数,最好的办法是对表进行分区,每次只取两个对应分区的数据进行join操作。具体的Hash Partition函数需要根据具体的应用场景实现。分区大小需要根据task-nums、num-executors以及executor-cores确定。
用自己的话理解就是在join之前,两个rdd(rdd是跨节点的)用相同的分区策略进行分区,保证相同的key在同一个分区,也就保证分区后相同的key在同一个节点上(spark计算末尾,一般会把数据做持久化到hive,hbase,hdfs等等。我们就拿hdfs举例,将RDD持久化到hdfs上,RDD的每个partition就会存成一个文件,如果文件小于128M,就可以理解为一个partition对应hdfs的一个block。反之,如果大于128M,就会被且分为多个block,这样,一个partition就会对应多个block),这样就可以保证join的时候没有网络传输,没有shuffle,也就是窄依赖)其它节点上的map task结果。这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。通常shuffle分为两部分:Map阶段的数据准备和Reduce阶段的数据拷贝处理。一般将在map端的Shuffle称之为Shuffle Write,在Reduce端的Shuffle称之为Shuffle Read
普通HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件(下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件,如果当前stage有50个task,50x100=5000个磁盘!总共有10个Executor,每个Executor执行5个Task,那么每个Executor上总共就要创建500个磁盘文件,!),进而由大量的磁盘IO操作影响了性能。SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
内存缓冲的大小可以通过参数调整, 参数:io.sort.mb 默认100M
普通HashShuffleManager:shuffle write阶段比如reduceByKey,groupByKey,每个task处理的数据按key进行“分区”。所谓“分区”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于reduce端的stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。下一个stage有多少个task,当前stage的每个task就要创建多少份磁盘文件!
普通HashShuffleManager:由于shuffle write的过程中,task给Reduce端的stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可
普通HashShuffleManager到合并机制的Hash shuffle设置:spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制
普通HashShuffleManager和:shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果
合并机制的Hash shuffle:一个Core中一种类型的Key的数据只有一个buff!在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中。下一个stage总共有100个task,每个Executor只有一个CPU core,此时就会创建100个磁盘文件,10个Executor只会创建1000个磁盘文件。
Sort shuffle的普通机制:溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序,排序过后,会分批将数据写入磁盘文件(首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中)。Reduce端的stage的task准备的数据都在同一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offse。第一个stage有50个task,就只有50个磁盘文件,与第二stage有多少个task无关!
Sort shuffle的bypass机制,task会为每个reduce端的task都创建一个临时磁盘文件和普通HashShuffleManager类似!但是:磁盘写机制不同!
task是一个流水线操作????一个节点的中以流水线形式计算窄关系的父节点就是task??,executor包含多个task,那executor就在多个节点也就多个个CPU core,所以executor中的多个task同时并行运行。
RDD的计算粒度就是partition(一组分片),每个分片都会被一个计算任务处理,并决定并行计算的粒度。partition(一组分片)默认值就是程序所分配到的CPU Core的数目。
Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量
一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置
当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。该分片是某个RDD中的(父/源??)
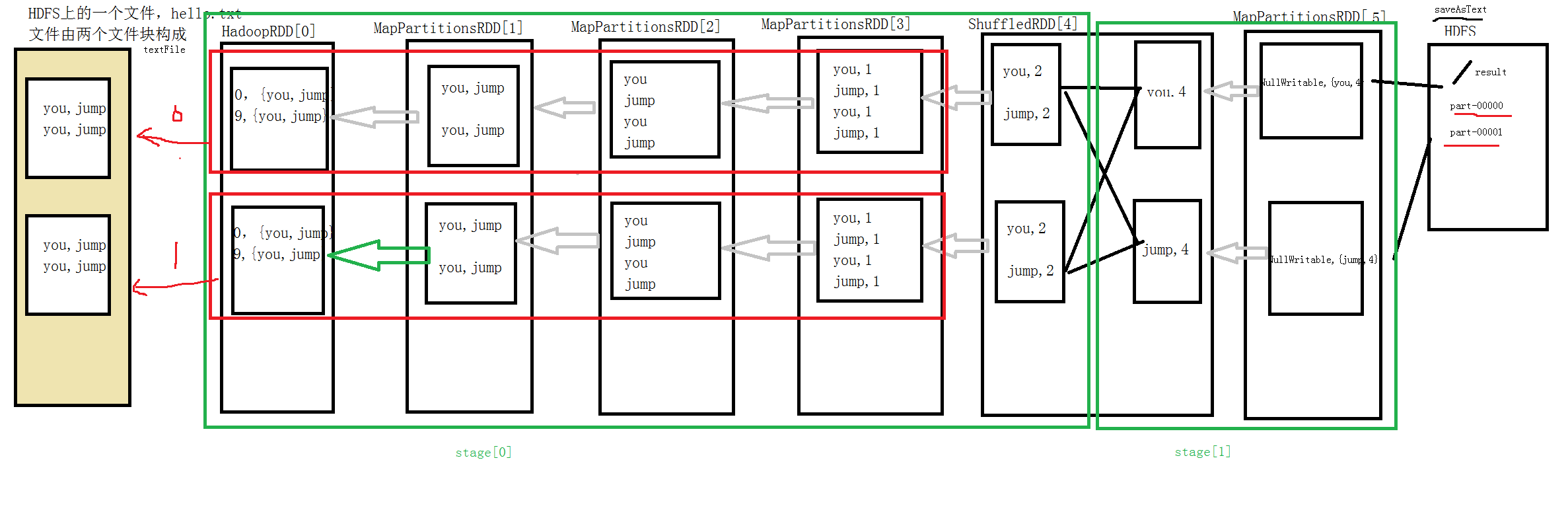
根据numslice在stage内部划分task,task是spark最小代码执行逻辑单元,图中红色部分为task,每个stage包含2个task,stage执行是顺序进行的,不同stage的task不一定相同,需要看shuffle后的分区数目??这句话啥意思?