

查询解析
解析会生成一个查询的内部展示。格式检查包含在解析过程中。
每次解析一个SELECT,步骤如下:
1. 从FROM里找到表名,转换成schema.tablename。这一步需要调用目录管理器catalog manager检查表是否在系统目录里,并将表的内部查询结构这类元数据缓存起来。
2. 根据上一步缓存起来的信息,校验属性引用。在这一步中,属性类型用来确定函数、比较运算、常量表达式,举例说明,(EMP.salary * 1,15)<7500 这里乘法和比较符号对应的1.15和7500默认是string类型,在解析过程中会根据salary的类型(整、浮点、金钱)来决定1.15和7500的类型。
3. 非SQL标准的格式检查,翻译不出来,直接贴原话:Additional standard SQL syntax checks are also applied, including the usage of tuple variables, the compatibility of tables combined via set operators (UNION/INTERSECT/EXCEPT), the usage of attributes in the SELECT list of aggregation queries, the nesting of subqueries, and so on.
解析完毕后,开始校验权限,即调用catalog manager检验用户行为是否合规(SELECT/DELETE/INSERT/UPDATE)。这一步也会找出查询中与完全性约束条件相悖的常量表达式,比如说如果设有EMP.salary为正的约束,那么“UPDATE … SET EMP.salary = -1”这条查询就不会通过权限校验。
catalog:数据库元数据,一般以多个表的形式存放在数据库中,记录实体名(用户、数据库schema、表、行、索引)和实体间的关系。
为什么元数据要以这种方式管理?因为对数据库来说,管理元数据可以和管理其它表一样,复用代码;对用户来说。用和数据查询一样的语法就能查看元数据。有很多开发人员早先实现的时候忽略重用代码,后来大呼后悔。
Catalog与普通表待遇一样吗?有点不同。高流量catalog在程序启动时候在主存中以非规范化(不是关系数据库表那种平面关系结构)的形式存放。还有catalog信息因为查询解析和优化步骤而缓存在查询计划中,也是以非规范化的形式存放。此外,catalog表通常服从于特殊情况事务性技巧,以最小化事务处理中热点问题。
catalog在商业应用中可能变得非常大。例如一个主要的企业资源规划应用程序生成超过30,000个表,每个表有4到8列,每个表通常有两到三个索引。
查询重写
查询充血需要在不改变语义的条件下简化和优化查询。这个步骤不需要访问表中的数据,全部是通过查询(查询的内部表示,而不是SQL文本)和catalog信息作决策。
1. 重写视图。
从FROM表达式里找出视图引用,对比catalog manager中视图定义,然后将针对视图的查询替换为针对表的查询、替换针对视图的断言为针对表的断言。以上改写过程是递归的,以全部查询基于表为结束标记。这种视图扩展技术,首先是针对INGRES 中基于集合的QUEL语言提出的,因此需要在SQL中小心处理重复消除,嵌套查询,NULL和其他棘手的细节。
2. 常量算术评估。简化不包含元组变量的算术表达式:例如“R.x <10 + 2”被重写为“R.x <12
3. 谓词(IN/BETWEEN/LIKE/OR/AND)逻辑重写。
WHERE子句中的谓词和常量应用逻辑重写。布尔谓词:例如NOT Emp.Salary >1000000改写为Emp.Salary <= 1000000,Emp.salary < 75000 AND Emp.salary > 1000000改写为false。这两个查询看起来很假,其实是可能出现的,比如说对高管Executives视图(salary>1000000)查询低薪员工,就可能重写出例2的愚蠢SQL。添加新谓词:例如“R.x <10 AND R.x = S.y”表示添加附加谓词“AND S.y <10”。添加这些传递谓词可以提高优化器选择在执行早期过滤数据的计划的能力,尤其是通过使用基于索引的访问方法。
4. 语义优化。
表的完整性约束存放在catalog中,可用于帮助重写某些查询。举一个消除冗余连接的例子,当从Emp.deptno的列到另一个Dept表存在外键约束时,代表每个Emp只有一个Dept,那么“SELECT Emp.name, Emp.salary FROM Emp, Dept WHERE Emp.deptno = Dept.dno”这个查询可被重写为“SELECT Emp.xxx FROM Emp”。上面这个愚蠢的查询,可能是在EMPDEPT视图(Emp和Dept联合)上查询引起的。
当对表的约束与查询谓词不兼容时,语义优化还可能导致查询执行短路。
5. 子查询展平和其他启发式重写。
大多数优化器独立地对各个查询块(一个SELECT-FROM-WHERE语句称为一个查询块。而将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询)进行操作,从而放弃了跨块优化的可能机会。与其进一步复杂化查询优化器(在商业DBMS中已经非常复杂),一种自然的启发式方法是在可能的情况下展平嵌套查询,以便为单块优化提供更多机会。由于重复语义,子查询,NULL和相关性等问题,某些情况下展平钱韬查询变得非常棘手。其他启发式重写也可以跨查询块进行,例如谓词传递性可以允许跨子查询复制谓词。值得注意的是,相关子查询的扁平化对于在并行体系结构中实现良好性能尤其重要,因为相关子查询的“嵌套循环”执行通过循环的迭代固有地序列化。
优化
优化器存在的意义就是,给执行器生产高效的查询计划。
查询计划是一个数据流图,数据从从基础关系流入,经过一系列查询运算。在大多数系统中,查询被分解为SELECT-FROM-WHERE查询块,如何在查询块内优化查询,可参见Selinger等人的《System R optimizer》。在每个查询块内GROUP BY,ORDER BY,HAVING和DISTINCT子句在最后执行,这些执行块间以直接的方式将拼接。
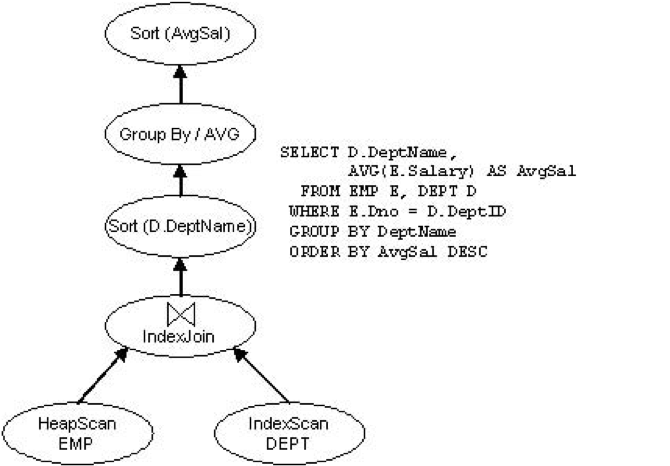
System R原型将查询计划编译成机器代码,而早期的INGRES原型生成了一个可解释的查询计划。 为了实现跨平台可移植性,现在每个系统都将查询编译成某种可解释的数据结构; 如今不同系统上的唯一区别在抽象级别:有些系统里查询计划轻量到看起来就是一个由数据访问方法名称、join算法等组成的关系代数表达式;有些系统里使用了和java二进制代码一样底层的代码来表示查询计划。为了方便讨论,后期论文将讨论类代数表达式查询表示。
下图为System R查询优化算法,图片出处已遗忘,罪过罪过。

Selinger关于System R的论文被视为圣经,不同系统在实现System R时做了扩展,主流的扩展包括:
计划空间:System R 优化器通过只关注“left depth”查询计划(这要求join的右手必须是基表)和“延迟笛卡尔积”(postponing Cartesian products,暂时不知道是什么含义)来限制其计划空间。在当今的商业系统中“浓密的”计划树(有嵌套的右手输入)和早期使用笛卡尔产品在某些情况下是有用的,因此这两种选择在大多数系统中都被考虑。
选择性估算:选择行估算是指给定区域D上的某个值a或者区间r,估算出A=a或者a属于r的概率,用于选择查询优化和近似查询处理。进行选择性估算的前提是获得数据分布或数据分布近似值。Slinger论文里的选择性估计基于简单表和索引基数(uniq(S)),当今DBMS有以下改进:
1. 有专门的后台进程通过柱状图和其它汇总信息定期分析和汇总属性中的值分布,以便进行基表JOIN的选择性估计。
2. 综合考虑列之间的相关性。
因为选择性估计在优化计算早期,估计错误会导致错误呈倍数的传播,因此选择性估算比较重要。
查询算法: 一些商业产品(微软和Tandem)放弃了Selinger的动态编程算法,转而采用基于级联框架的目标导向的“自上而下”搜索方案。在某些情况下,自顶向下搜索可以降低优化器所考虑的计划数,但也可能对提高优化器内存消耗产生负面影响。这两种算法优化效果都可以,并且两个优化器的运行时间和内存需求在查询中的表数中仍然是指数级的。
如果表太多,有些产品会退化到启发式查询,据说商业DB产品的启发式查询算法是不公开的(MySQL借鉴了早期了oracle,MySQL最后的检查是完全启发式的,主要依赖于利用索引和键/外键约束);有的产品则直接放弃执行这类查询,除非用户在SQL中提示“hint”以指明选择哪种优化器。
并行性:主要是查询内并行性(对单个单循使用多个处理器),因此查询优化器需要决定如何调度CPU、share-nothing或shared-disk情况下甚至需要通过交换算法调度高速网络下多台机器。
可扩展性:考虑到现在SQL支持嵌套元组、集合、数组、XML树、用户定义的函数,因此商业优化器不能忽略这些昂贵方法。工业界一般来说是用启发式算法,但是学术界也有一些面向对象和XML查询处理的文献。
自动调整:工业界关注的问题。一般是通过手机查询工作负载,然后使用优化器通过假设分析来查找查询计划成本。
查询预处理
好处是同一个connection不需要每次查询都执行解析、重写和优化。实际上预处理使用量比点对点查询更多。
预先编译的查询计划也是需要维护的。
最基本的例子,删除某索引后,所有使用了该索引的计划都要相应的被删除,这样才能保证下次查询使用新的查询计划。
不同厂商重新优化的策略也不相同。
例如IBM致力于提供可预期的性能,直到查询计划不可用(如索引被删除)才会触发重新优化;而微软则致力于自调节性,甚至值分布直方图改变(影响选择性估算)也会触发重新优化。微软这种策略不可预测,但是应对动态环境可以表现出更佳的性能。
为什么微软和IBM两家公司产品的决策呈现哲学性差异?
IBM一直面向雇有高水平DBA和高水平程序员的高端买家,对这些买家来说他们喜欢自己对数据库设计和设置进行精细调节,DBA尤其不希望优化器自发的更改查询计划,这对DBA来说是不可预期的;相反,微软进入DB行业时瞄准的是低端市场,这些买家的IT预算和专家都不够,需要DB能尽快的自我调节查询计划。
查询器
出于对早期的关系型系统路径依赖的问题,现在所有的查询执行器都使用迭代器模型。查询计划里每个操作符都继承超类iterator(见下图),包含一个用于定义数据流图边界的inputs数组;同时操作符还有自己的功能,例如文件扫描、索引扫描、nested-loops jioin、排序、merge-join、hash-join、duplicate-elemination、grouped-aggregation。每个操作符的逻辑与父类、子类都不相关,他们的input是其它操作符,因此这些操作符可以随意组合。
了解迭代器可以去看PG代码,因为PG对迭代器的实现复杂度适中、且覆盖了几乎所有的标准查询算法。

迭代器的特点是将数据流与控制流耦合在一起,通过get_next()将元组引用返回通过调用堆栈返回给调用方,也就是说控制流返回后元组被返回给查询图的父级。迭代器这种工作方式不需要队列、也不需要做迭代器之间的速率匹配,可以单线程的完成工作,所以说迭代器模型的数据库查询器带来以下好处:
1. 架构简单。不像网络这种数据流体系结构那样依赖各种协议在并发生产者和消费者之间进行排队和反馈。
2. 对于单点查询执行也很有效,假设I/O不是瓶颈(现代DB都有专门的进程处理磁盘预读),那么由于查询器中始终有一个迭代器处于活动状态,因此资源利用率可以最大化。
迭代器模型的查询器如何实现并行?
通过对特殊交换迭代器进行并行化封装和网络通信封装,就可以使单线程的迭代器模型支持并行。
数据如何存放?元组如何存放在内存,如何在迭代器之间传递?
首先,每个迭代器预先有分配定额数量的元组描述器,包括n个输入,1个输出。元组描述器是一个列引用数组,每个列引用由一个指向内存里元组的引用和一个元组内偏移量构成。迭代器的超类不负责动态分配这些元组描述器的内存,子类构造元组描述器的方式有两种:
1. BP-tuple基表元组驻留在缓冲池页面中,迭代器初始化元组描述器的时候增加该页的pin计数;销毁元组描述器的时候减少pin计数。BP-tuple的一个坏处是,如果迭代器长时间引用页面,那么整个页都要存在bufferpool里,对内存是一种消耗。于是还有一种将元组拷贝出buffer poll的方法-M-tuple。
2. M-tuple在内存堆里为元组描述器分配内存,可能是从缓冲区里拷贝行(副本用pin/unpin括起来),也可能是计算具体查询里的表达式(一般是EMP.sal * .1这类算数表达式)得到。表面上看,采用M-tuple的话简化了执行器代码,还避免了缓冲区泄漏(长时间执行容易忘记unpin页面),但是存储那一章讨论过的,内存的拷贝会造成DB严重的性能瓶颈,所以实际一般使用BP-tuple。
所以需要,既支持BP-tuple又支持M-tuple。
DML语句的执行计划看起来像简单的直线查询计划,以单个访问方法作为源,并在管道的末尾使用数据修改操作符。
当DML语句的查询计划需要查询和修改同样的表时就会比较复杂。比方说某年12月30日发现的“圣诞日问题”,“为所有薪水20K以内的人提薪10%”这个操作如果被简单的解析成一个下图左侧查询计划,即一个EMP.salary列的索引扫描遍历器外接一个更新遍历器,那么这条语句的执行结果是所有低收入员工n次涨薪直到薪资超过20K,原因是索引扫描遍历器会不停的发现被修改的元组。
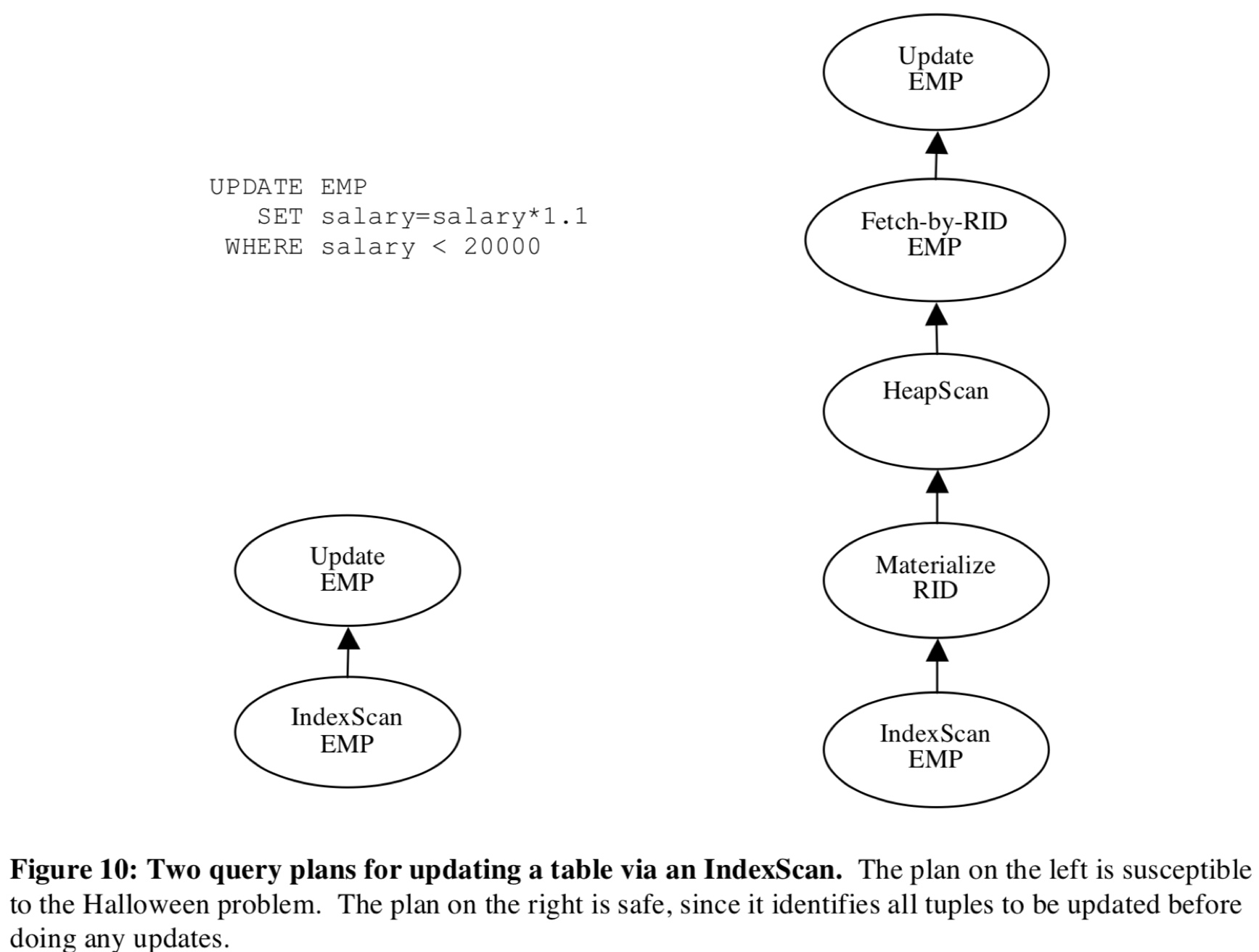
这就引来一个设计问题,如何让DML不能看见被自己更新的数据呢?
1. Pipelined update scheme. 优化器选择避免重复更新的执行计划,有些情况下这种方法不奏效,同时这种方法要求存储引擎支持这种操作。
2. 引入批量read-then-write架构,像右图右侧那样在索引扫描和数据流中的数据修改操作符之间插入记录ID物化和获取操作符。物化操作符会将所有待修改元组的ID存放到零食文件,然后扫描零时文件、将ID映射成物理元组ID,将元组喂给数据修改操作符。只要一次不修改太多元组,这种方法就是高效的。
Access methods 访问方法
数据库需要访问磁盘里各种格式的文件,如无序的元组文件、B+树索引、R树索引、索引专用位图变量。这通过特殊的迭代器“access method”实现。
访问方法最基本的API是iterator,Iterator的init方法里扩展表单列运算符常量为搜索谓词(SearchARGument)。将SARGs传递给访问方法层有两个原因:
1. 为了使用B+树等索引。
2. 为了适用于堆扫描和索引扫描。
假设SARG校验是access method调用方发起的,那么会产生多次CPU循环:每次调用访问方法的get_next(), 要么得到一个缓冲池里元组所在的帧栈(然后这一页会被pin住,以防被换页算法回收),要么得到一个元组的拷贝;之后,调用方检查元组,如果不符合SARG,就要做select的逆操作,要么unpin,要么删除拷贝的tuple,逆操作后需要重新调用get_next()获取下一个元组。以上的call/return、pin/unpin、create/destory步骤需要多次CPU循环,而且要么因为pin浪费了缓冲池、要么因为瞎create/destroy浪费CPU和内存。因此,处于性能考虑,要么应该由access method校验SARGs参数、每次get_next只返回满足SARGs的元组;要么应该一次把缓冲区里某页里所有符合SARGs的元组取出来。
所有的access method都有一个特殊的SARG用于直接查物理记录ID(RID)。fetch-by-RID用于支持二级索引和一些其他“指向”元组的方案(需要定期删除这些指针)。
access methods与事务并发、恢复逻辑有深度交互,后文(第5章)将讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号