
while循环补充说明,流程控制之for循环使用,range方法使用,数据类型内置方法与操作,整型内置方法与操作,浮点型内置方法与操作,字符串内置方法与操作,列表内置方法与操作,可变类型和不可变类型,字典的内置方法与操作,元组的内置方法与操作,集合的操作,字符编码,文件操作方式,文件读写发放,文件操作方式,使用文件的方法,文件内光标的移动
while循环使用不当就会死循环
死循环
真正的死循环是一旦执行CPU功耗会急速上升直到系统采取紧急措施尽量不要让CPU长时间不间断运算
嵌套及全局标志位
一个break只能结束它所在的那一层循环
有几个while的嵌套 想一次性结束 就应该写几个break
如果不想反复写break 可以使用全局标志位
给while介绍的条件
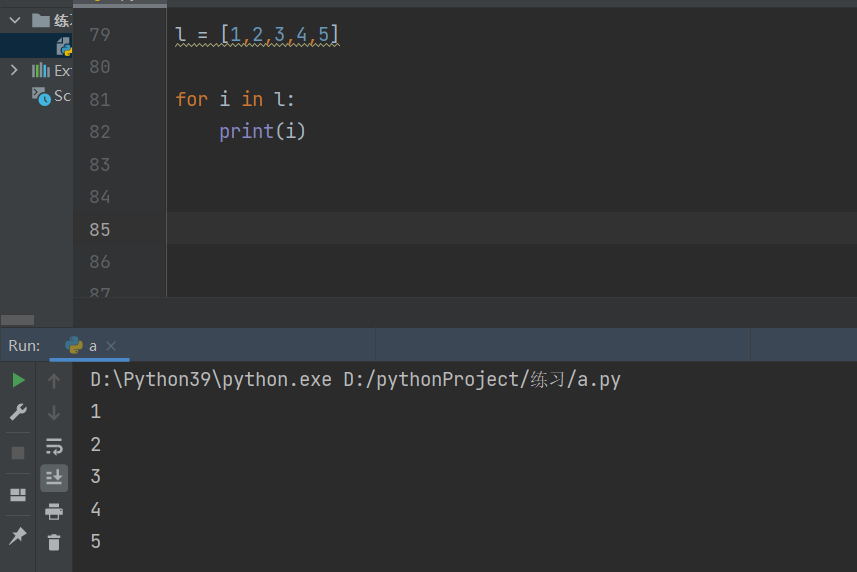
流程控制之for循环使用
for循环语法结构
for 变量名 in 待遍历的数据:
for循环体代码
for循环特点
1.擅长遍历取值
2.不需要结束条件 自动结束(遍历完)
for循环主要遍历的数据类型有(常见有 字符串、列表、元组、字典、集合)
字典for循环只有键参与遍历
注意事项
for循环体代码中如果执行到break也会直接结束整个for循环
for循环体代码中如果执行到continue也会结束当前循环直接开始下一次循环
for 变量名 in 待遍历的数据:
for循环体代码
else:
for循环体代码没有被break强制结束的情况下运行完毕之后 运行
range方法使用
产生一个内部含有多个数字的数据
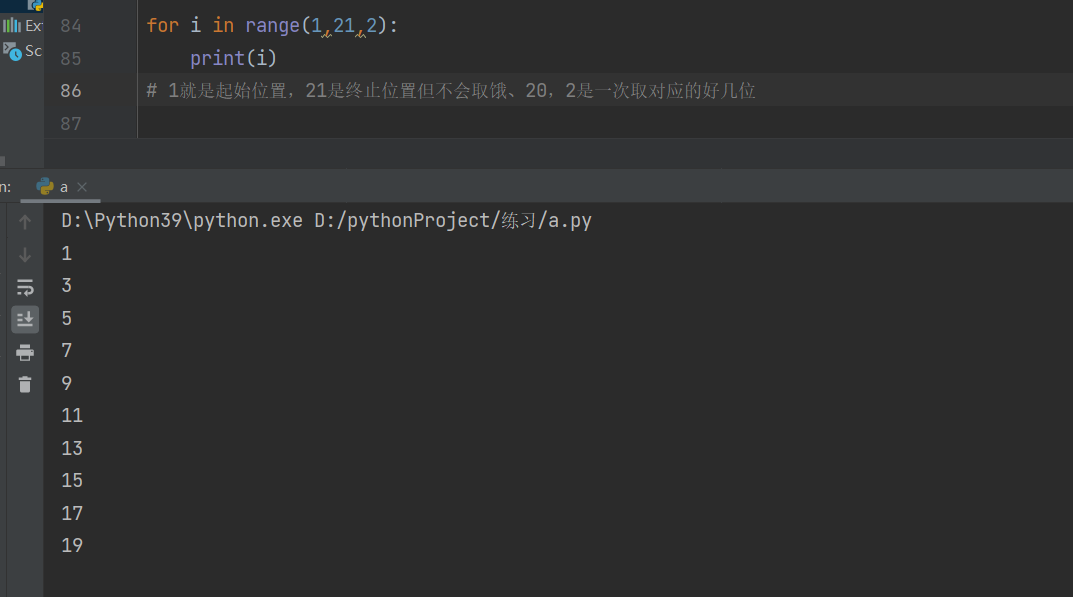
步数不写默认是1
整型内置方法与操作
类型转换(将其他数据类型转换成整型)
int(其他数据类型)
浮点型可以直接转字符串必须满足内部是纯数字才可以
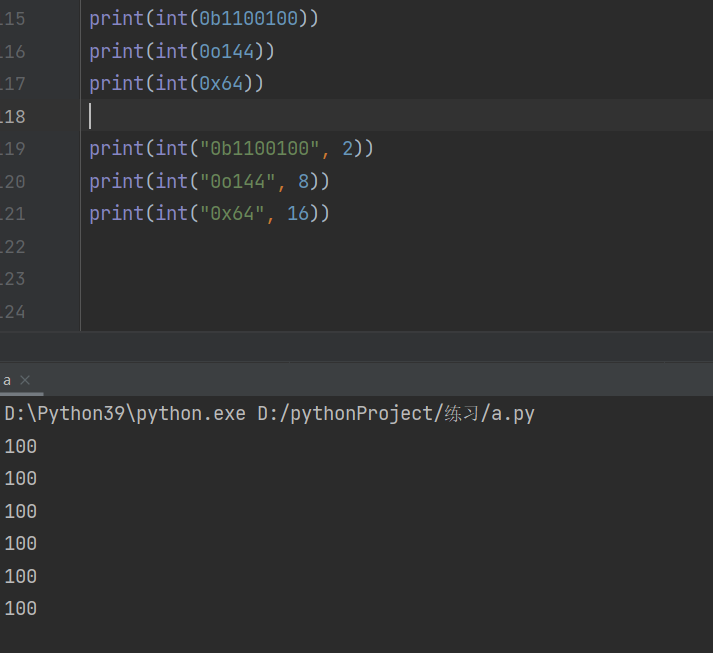
进制数转换
bin(整型)转成二进制
oct(整形)转换成八进制
hex(整形)转成十六进制
数字的开头如果是0b则为二进制 0o则为八进制 0x则为十六进制
转回原来的数据
浮点型内置方法与操作
类型转换
float(其他数据类型)
字符串里面可以允许出现一个小数点其他都必须是纯数字
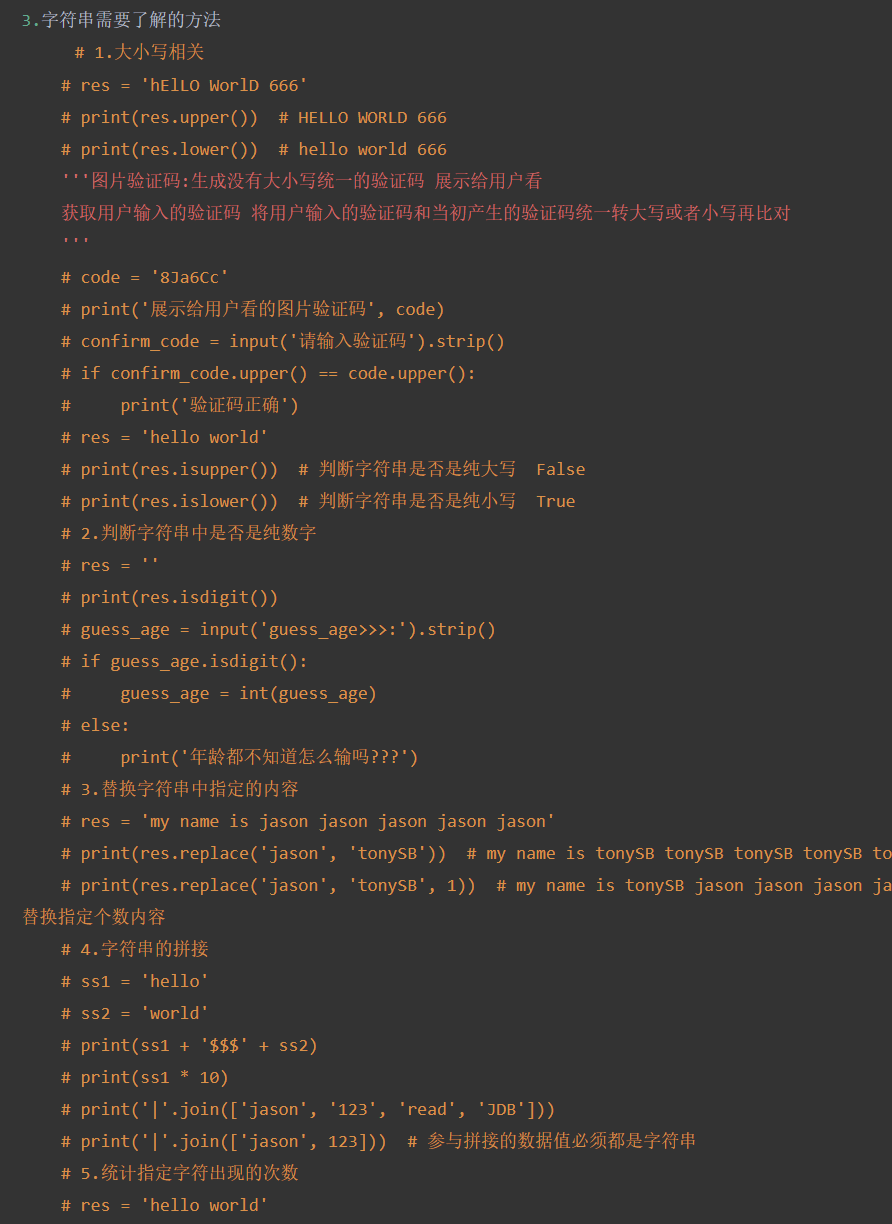
字符串内置方法与操作
类型转换
str(其他数据类型) 可以转任意数据类型(只需要在前后加引号即可)
要掌握的方法
索引取值

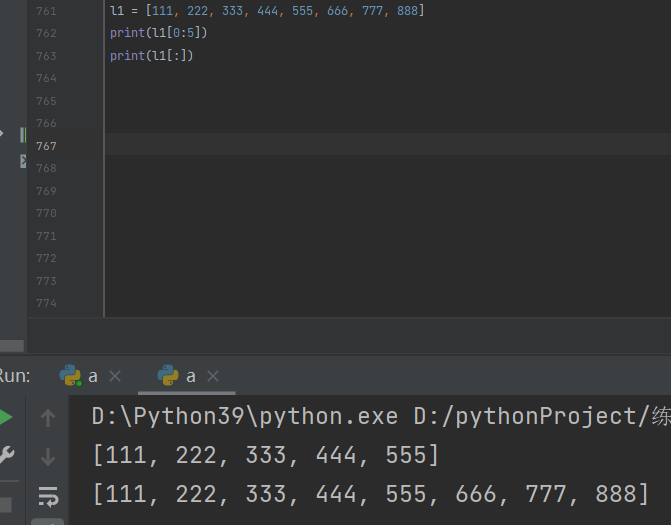
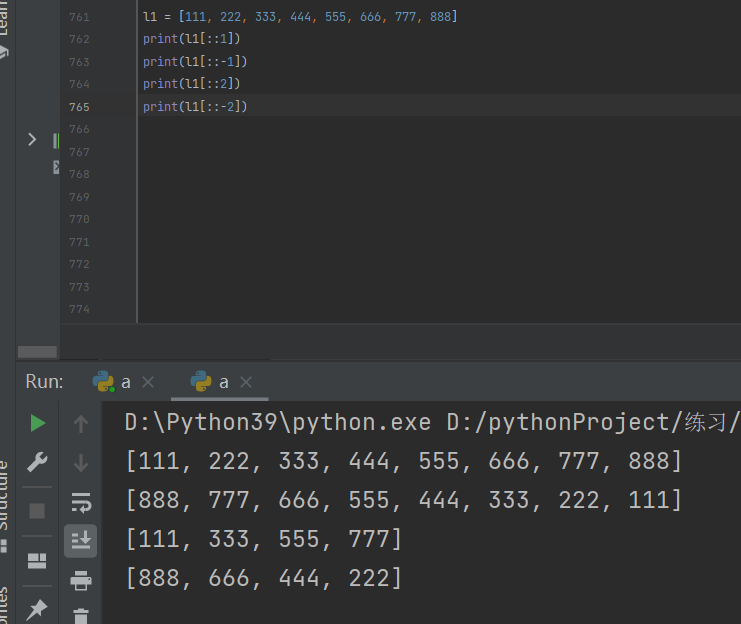
切片操作

修改切片方向(间隔)

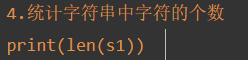
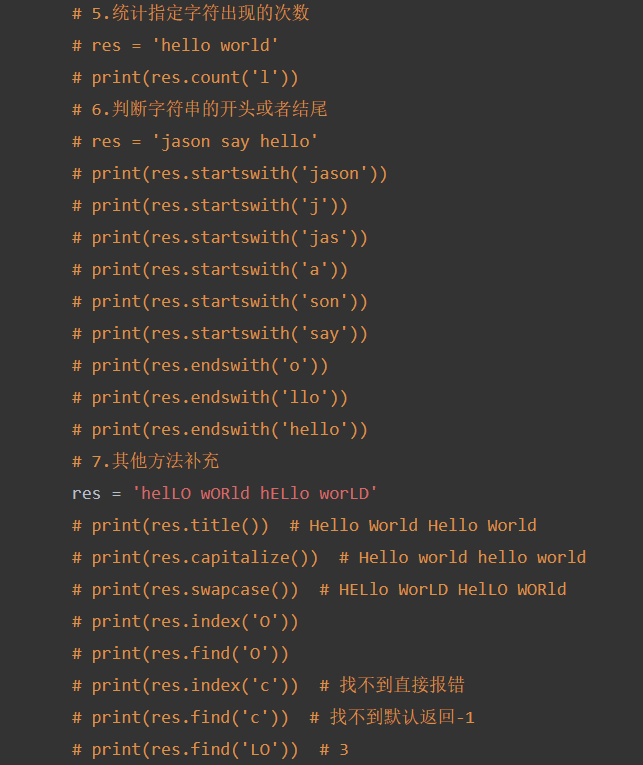
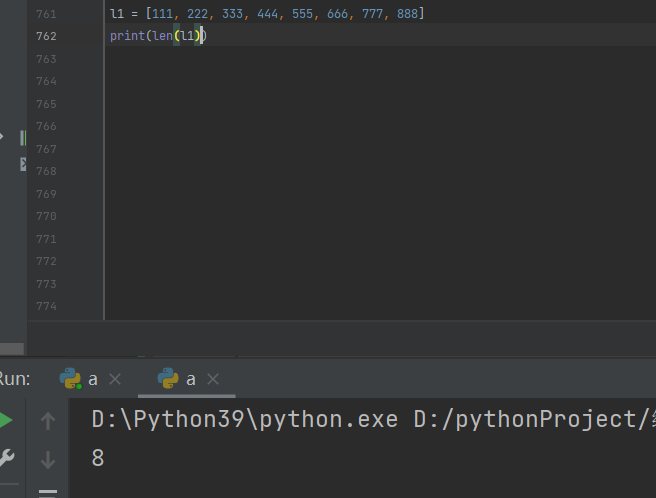
统计字符串中字符的个数
移除字符串首尾指定的字符
.strip()括号内不写默认移除首尾的空格
切割字符串中指定的字符

字符串格式化输出
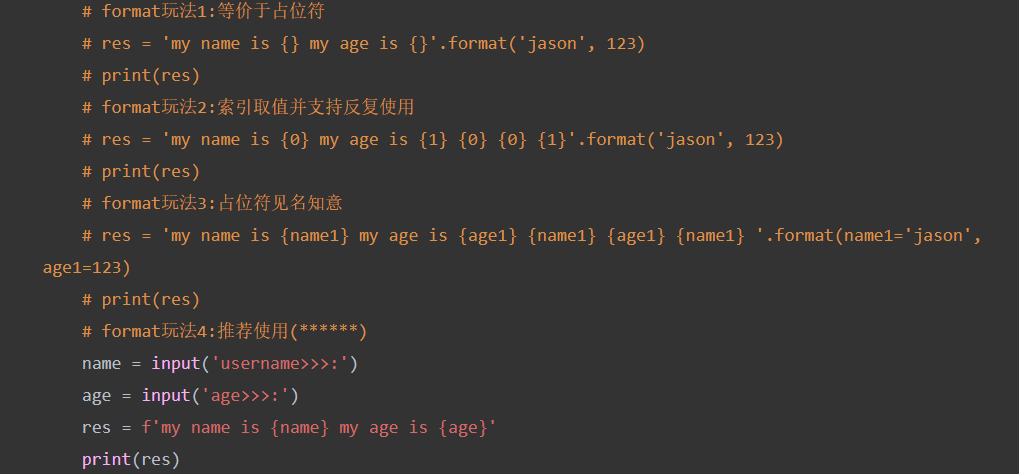
了解的操作
列表内置方法及操作
类型转换
变量名 = list(其它类型数据)
能够被for循环的数据类型都可以转成列表
内置方法
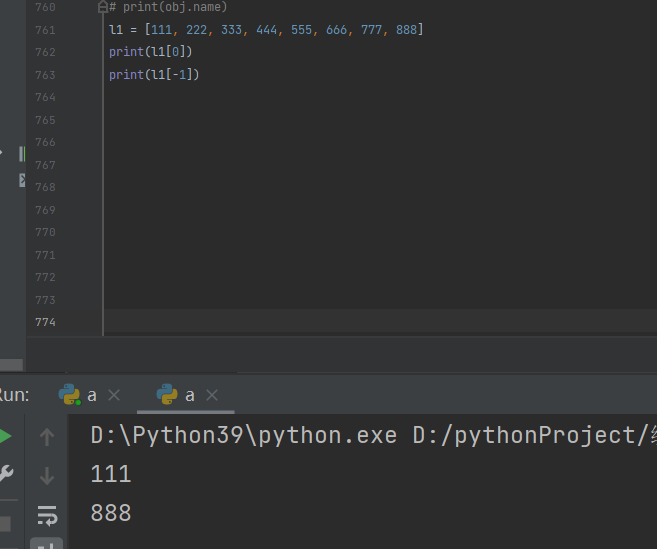
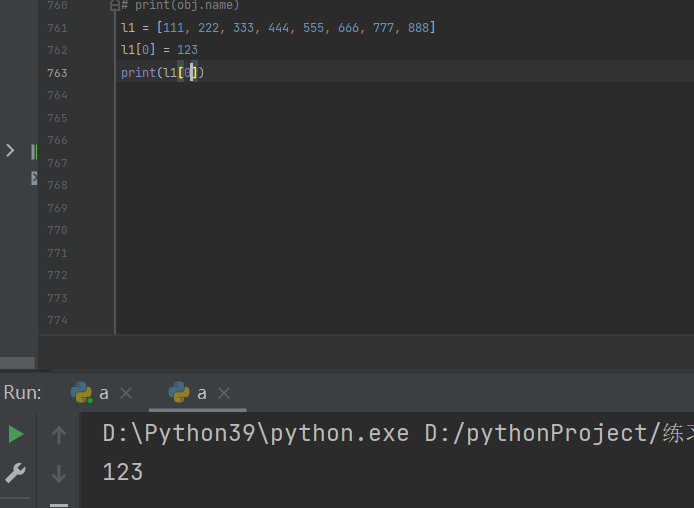
索引取值(正负数)
切片方法
间隔数
统计列表数据的个数
数据值修改
列表添加数据值
1.尾部追加
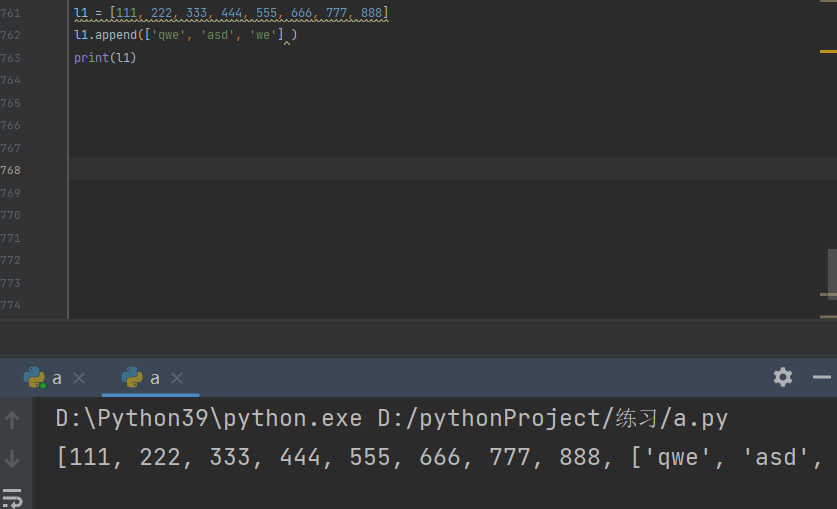
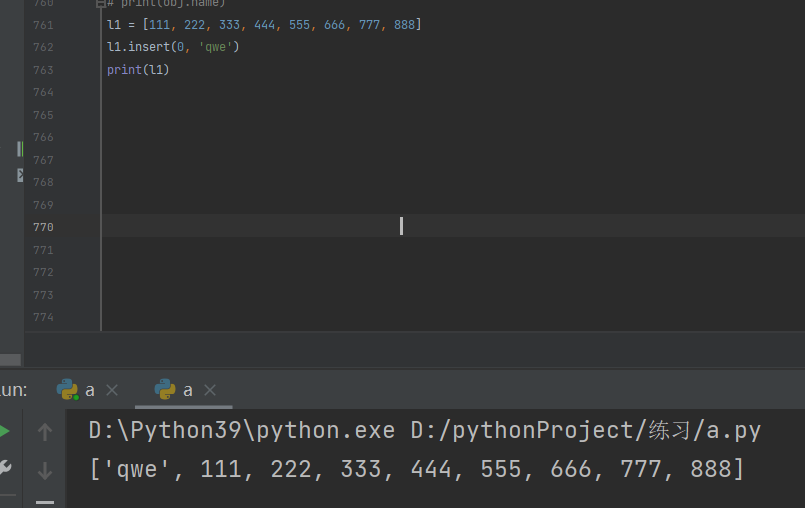
2.任意位置插入.insert(位置,数据)
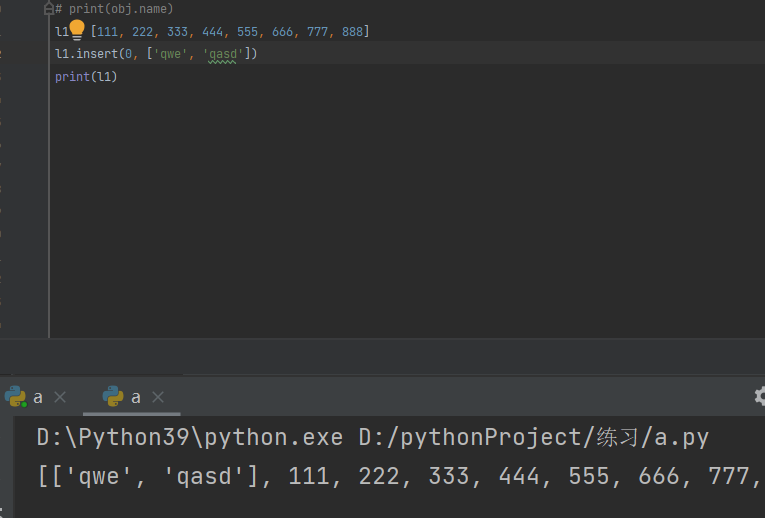
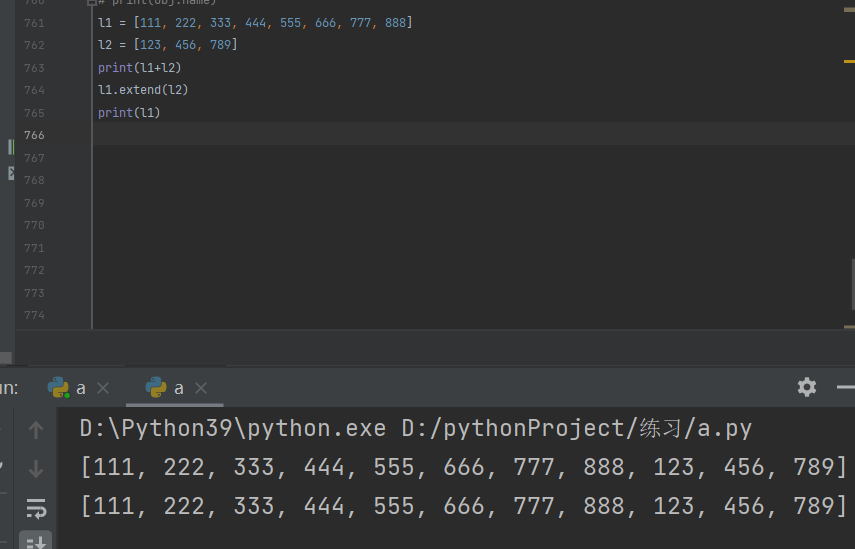
3.列表合并.extend(列表)
删除列表数据
关键字删除
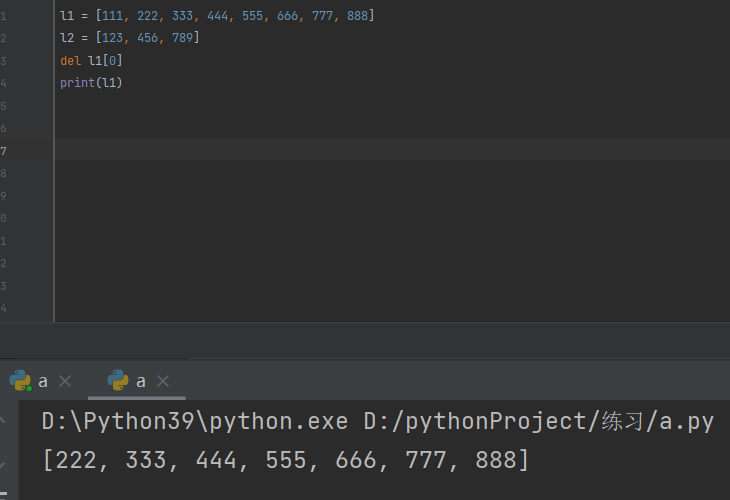
列表.remove(数据值)
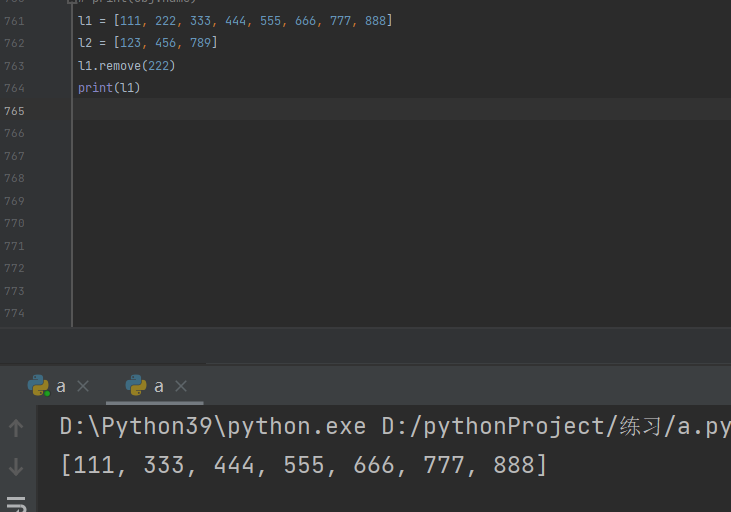
列表.pop(位置)
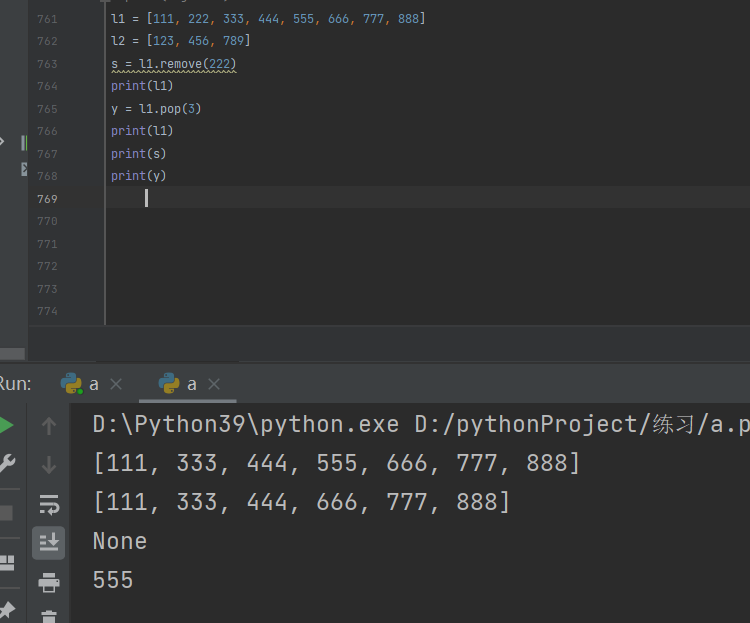
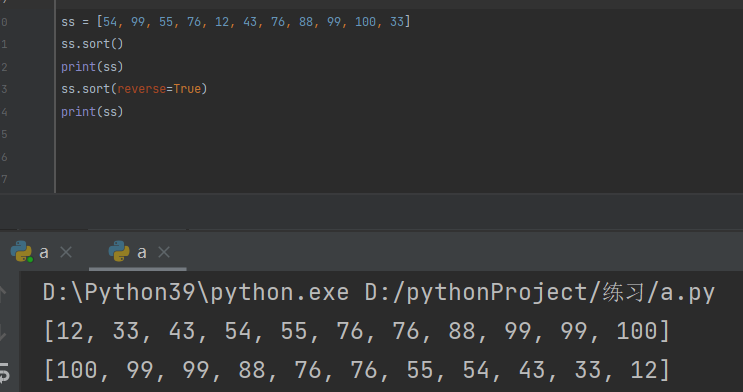
列表排序
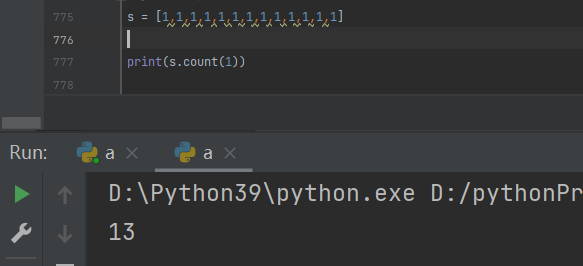
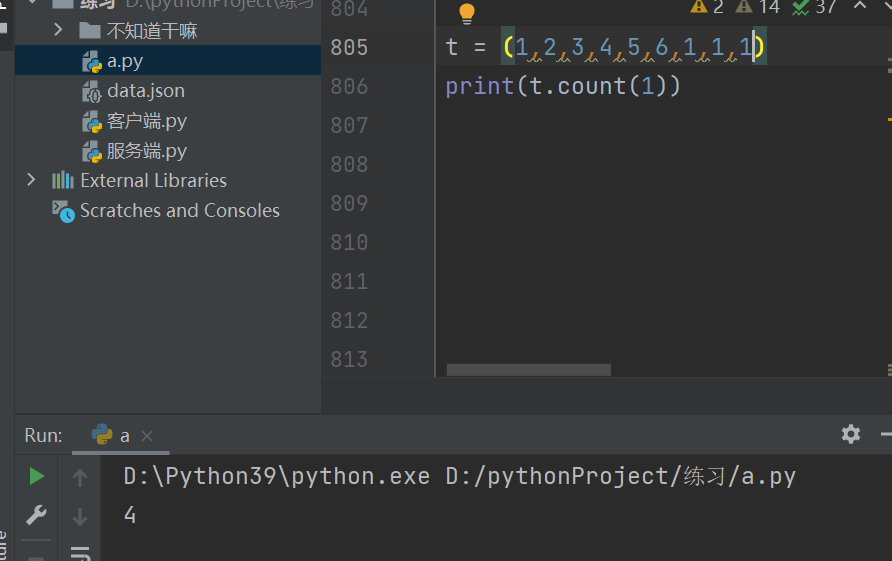
统计列表中某个数据出现的次数
列表.count(数据)
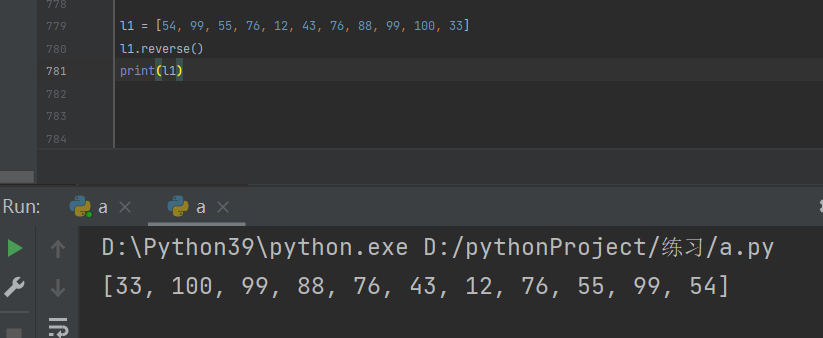
颠倒列表顺序
列表.reverse()
可变类型与不可变类型
可变类型
就是值改变了,内存地址不变
不可变类型
值改变了,内存地址也改变了
字典的内置方法与操作
类型转换
变量名 = dict(数据)
注意字典转换是按照k:v的形式
内置方法
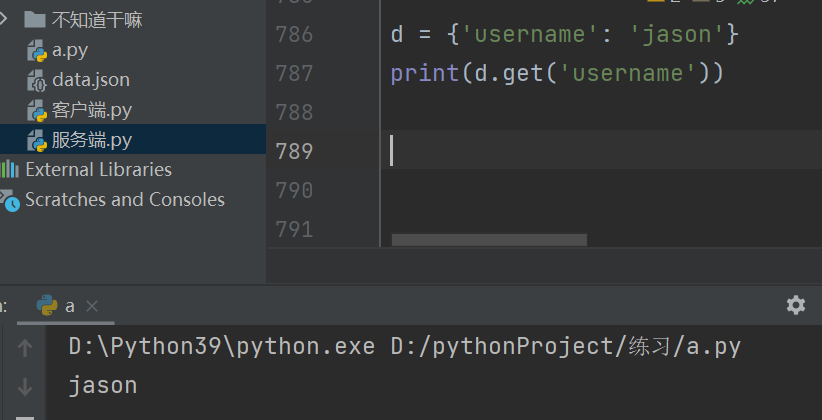
字典的取值:字典.get(k)
键不存在默认返回None按k取值没有会报错
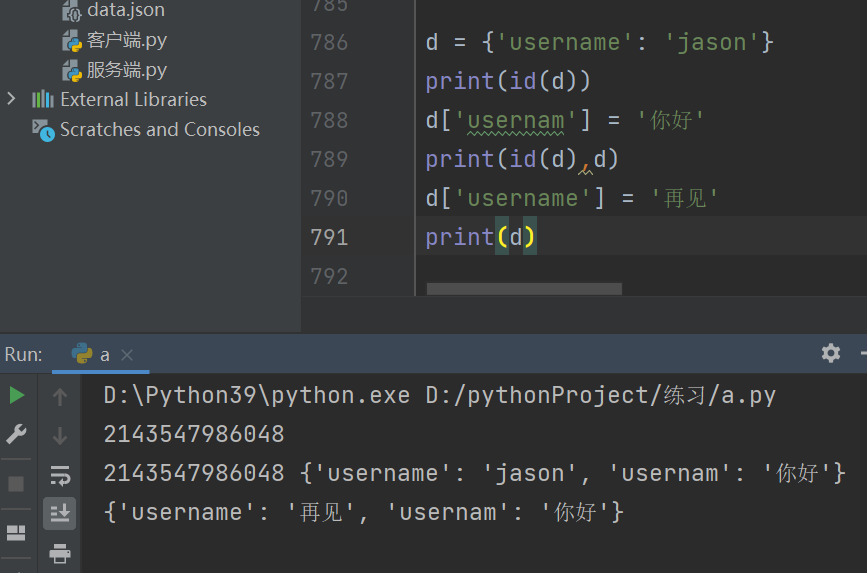
修改数据,新增键值对
键不在就添在就修改
删除数据
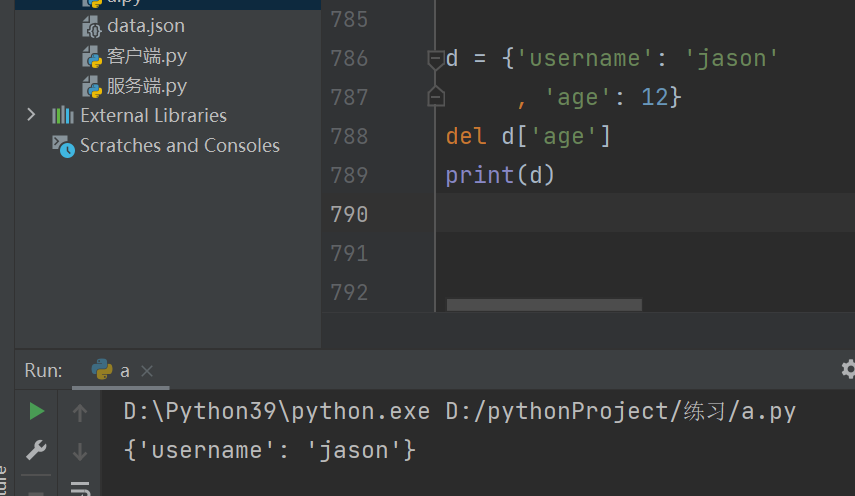
统计字典中键值对的个数
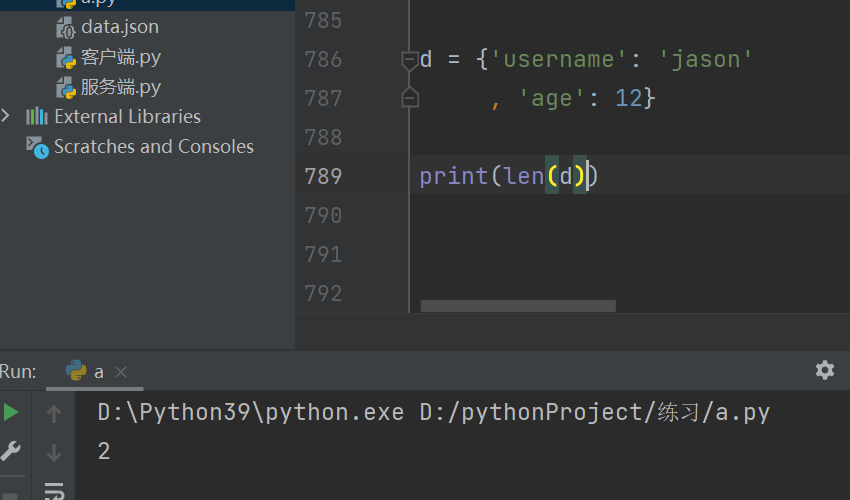
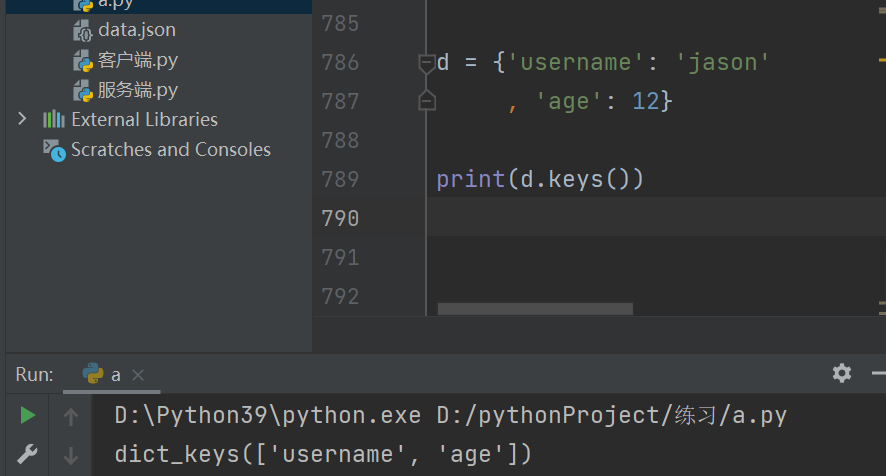
一次性获取字典所有的键 .keys()
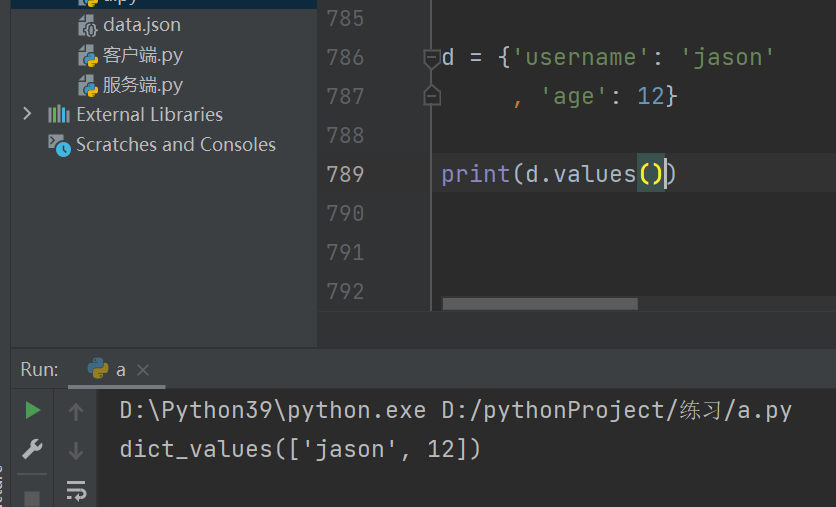
一次性获取字典所有的值 .values()
一次性获取字典的键值对数据 .items
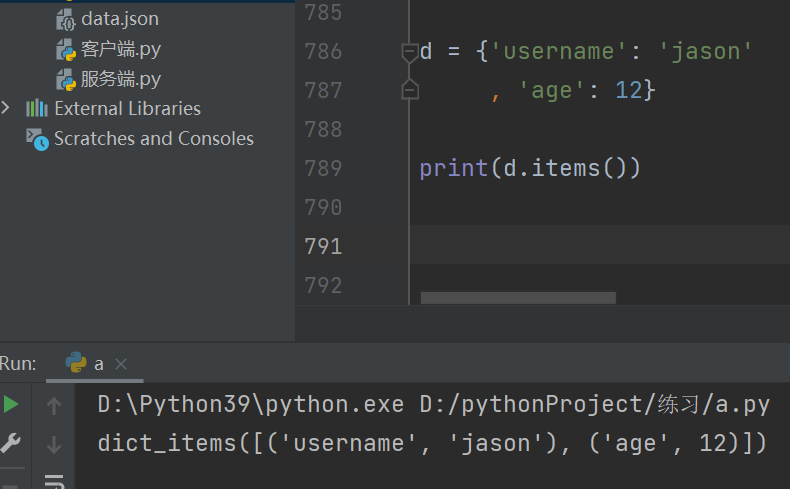
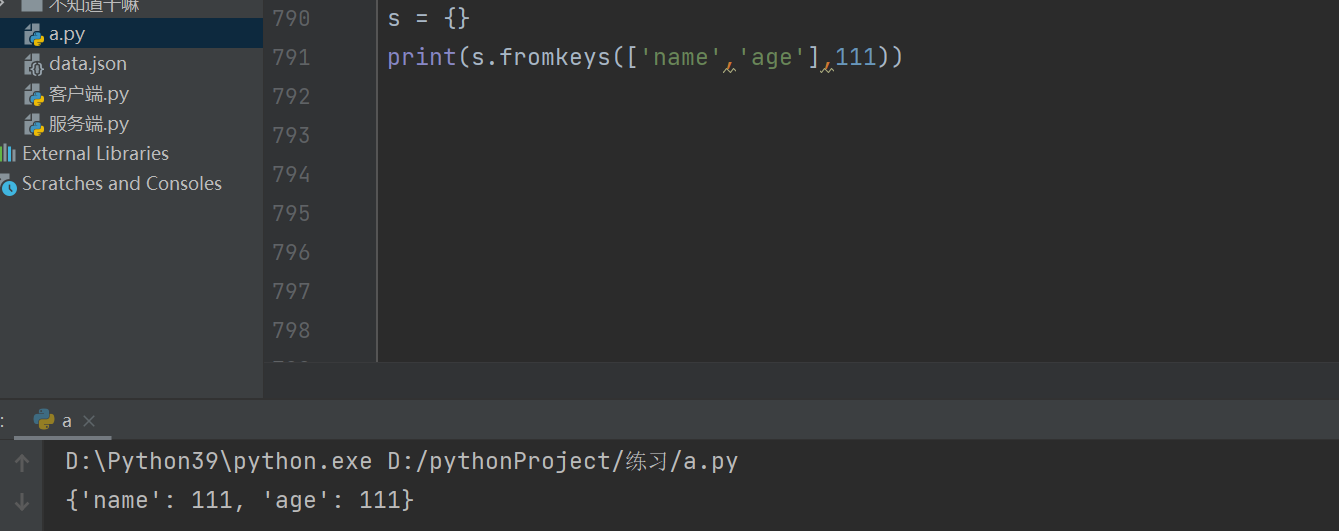
快速生成值相同的字典.fromkeys()
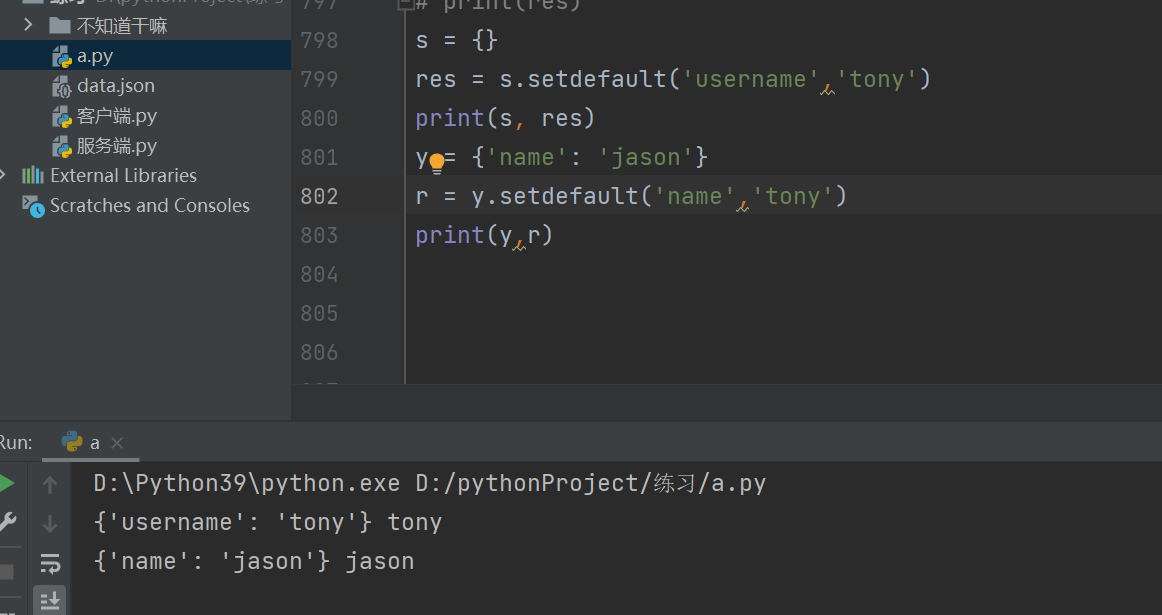
键存在则不修改结果是键对应的值.setdefault
元组的内置方法与操作
类型转换
变量名 = tuple()
支持for循环的数据类型都可以转成元组
元组的内置方法
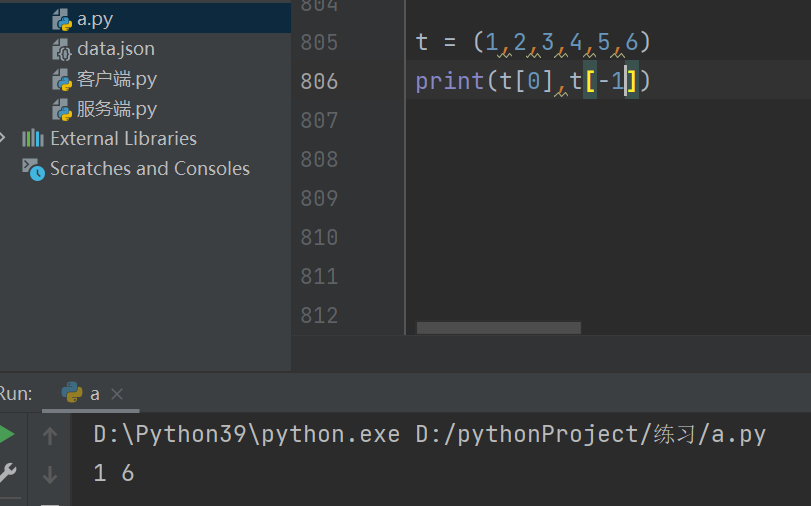
索引取值
切片操作
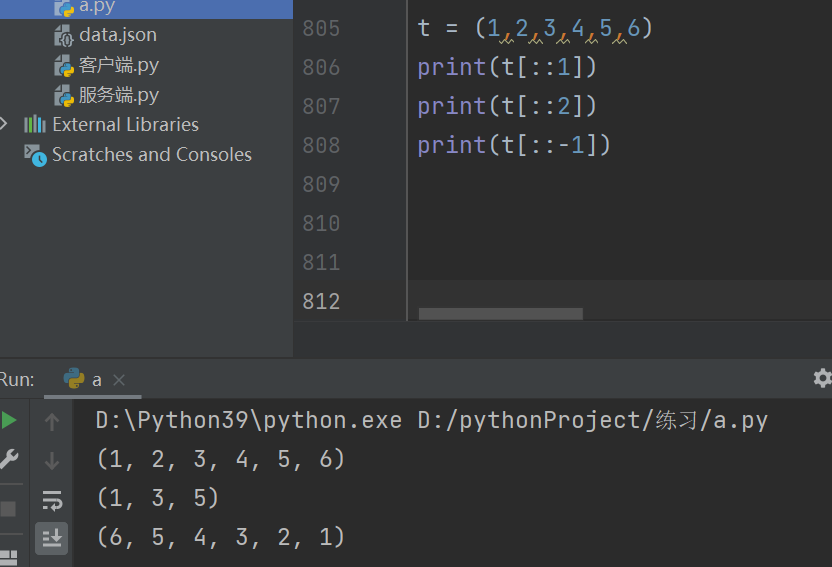
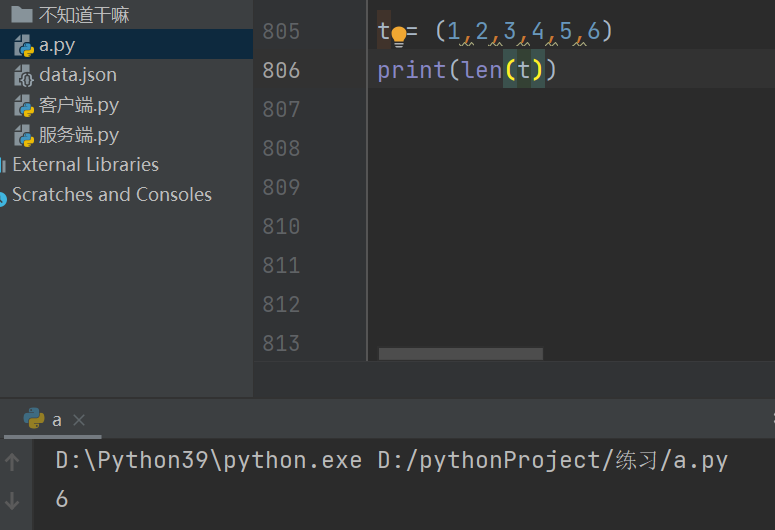
统计元组内数据值的个数
统计元组内某个数据值出现的次数
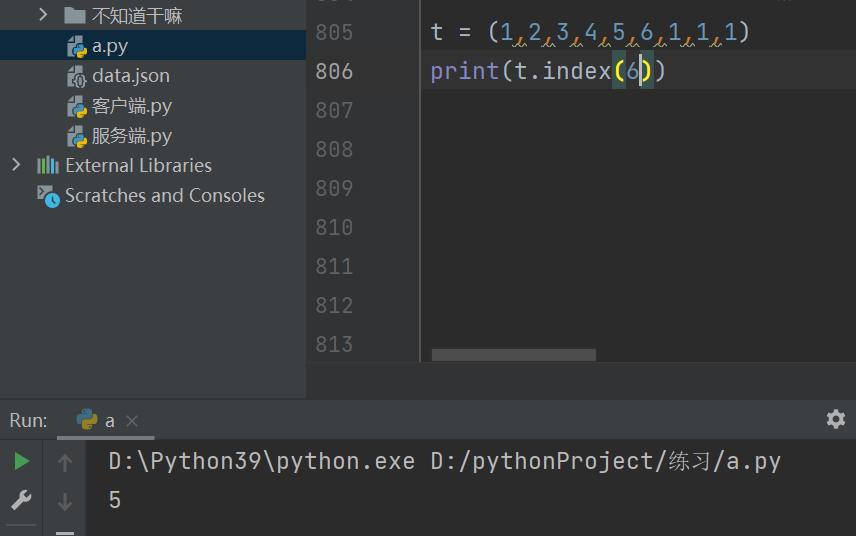
统计元组内指定数据值的索引值
元组内如果只有一个数据值那么逗号不能少
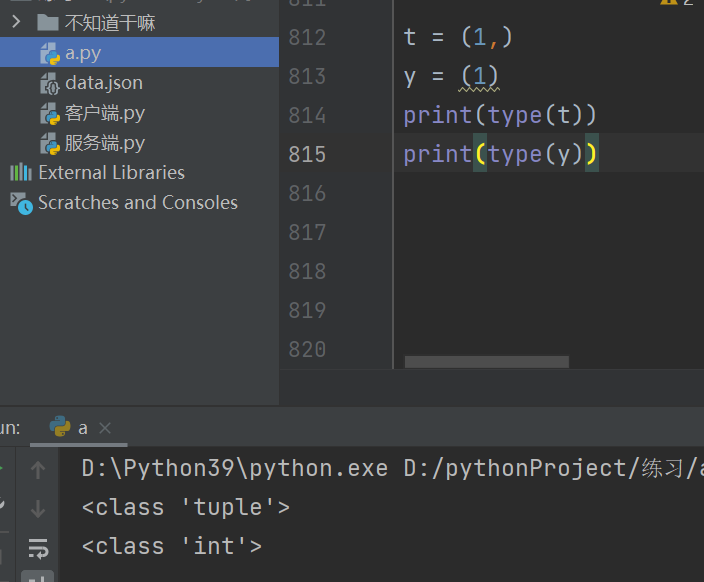
元组内索引绑定的内存地址不能被修改和元组不能新增或删除数据
集合的操作
类型转换
变量名 = set(数据)
集合内数据必须是不可变类型(整型,浮点型,字符串,
注意:集合内数据必须是不可变类型(整型,浮点型,字符串,元组)集合内数据也是无序的没有索引的概念元组)集合内数据也是无序的没有索引的概念
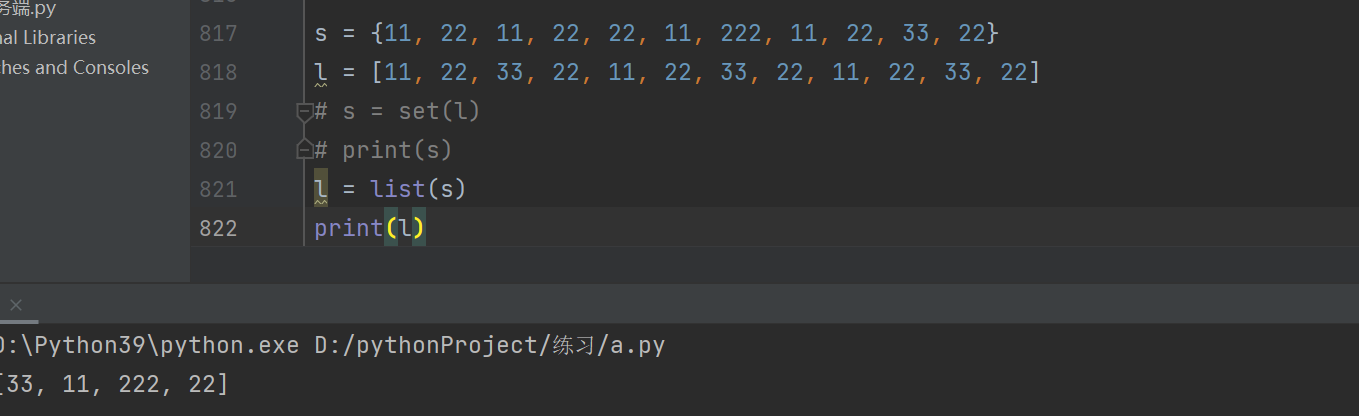
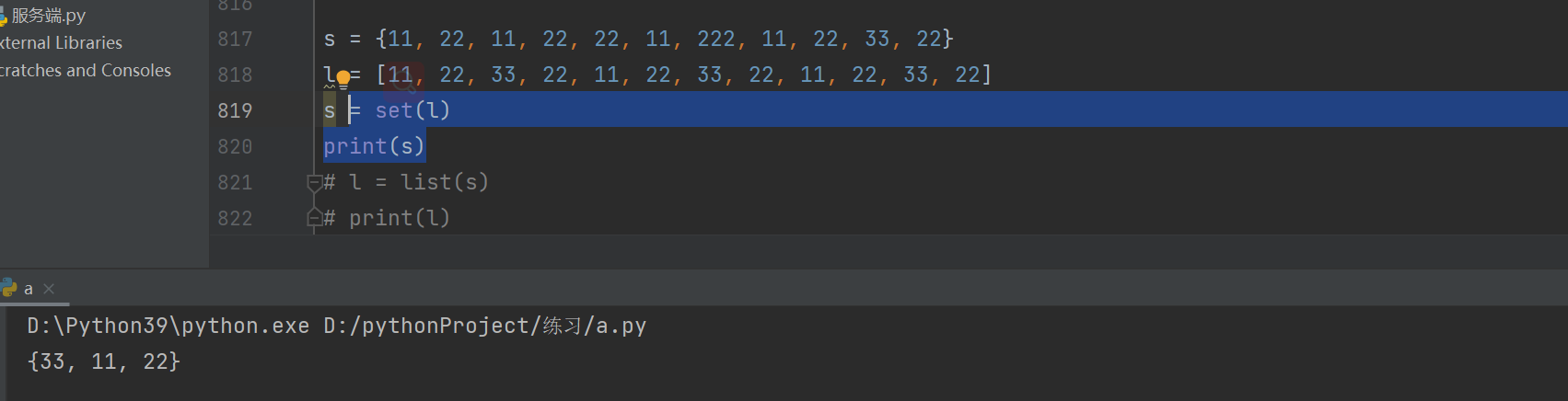
去重
关系运算
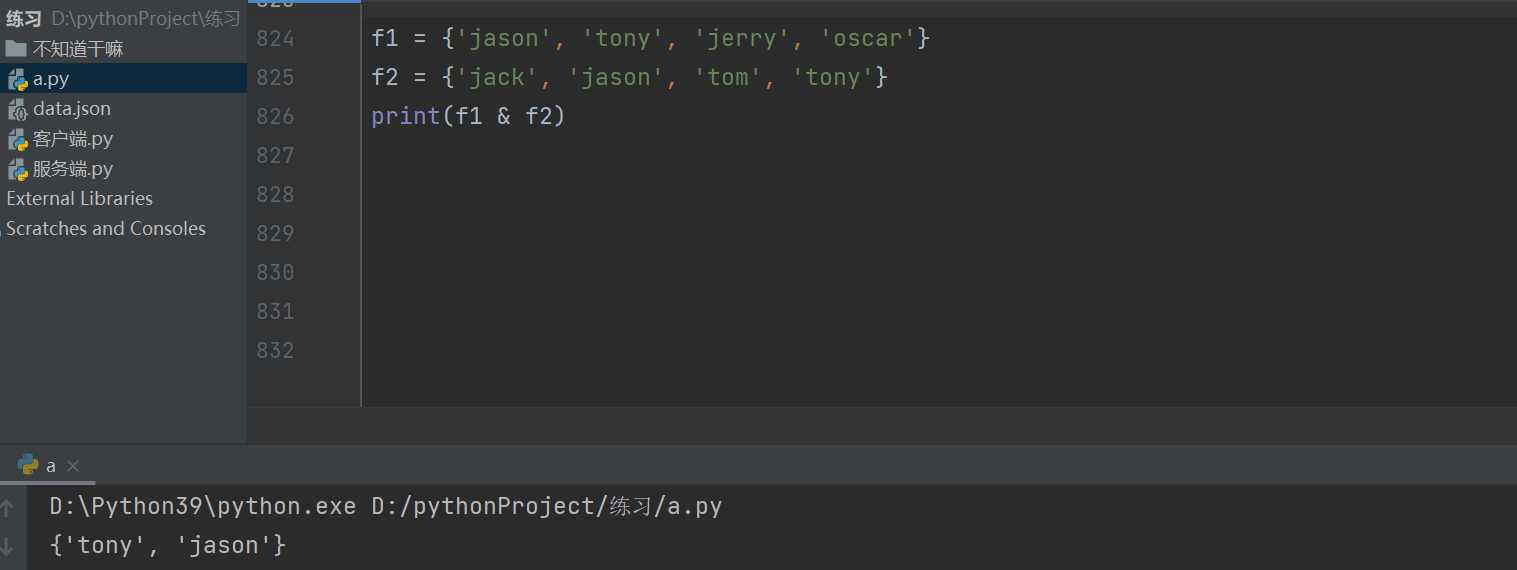
两个共同的数据 元组&元组
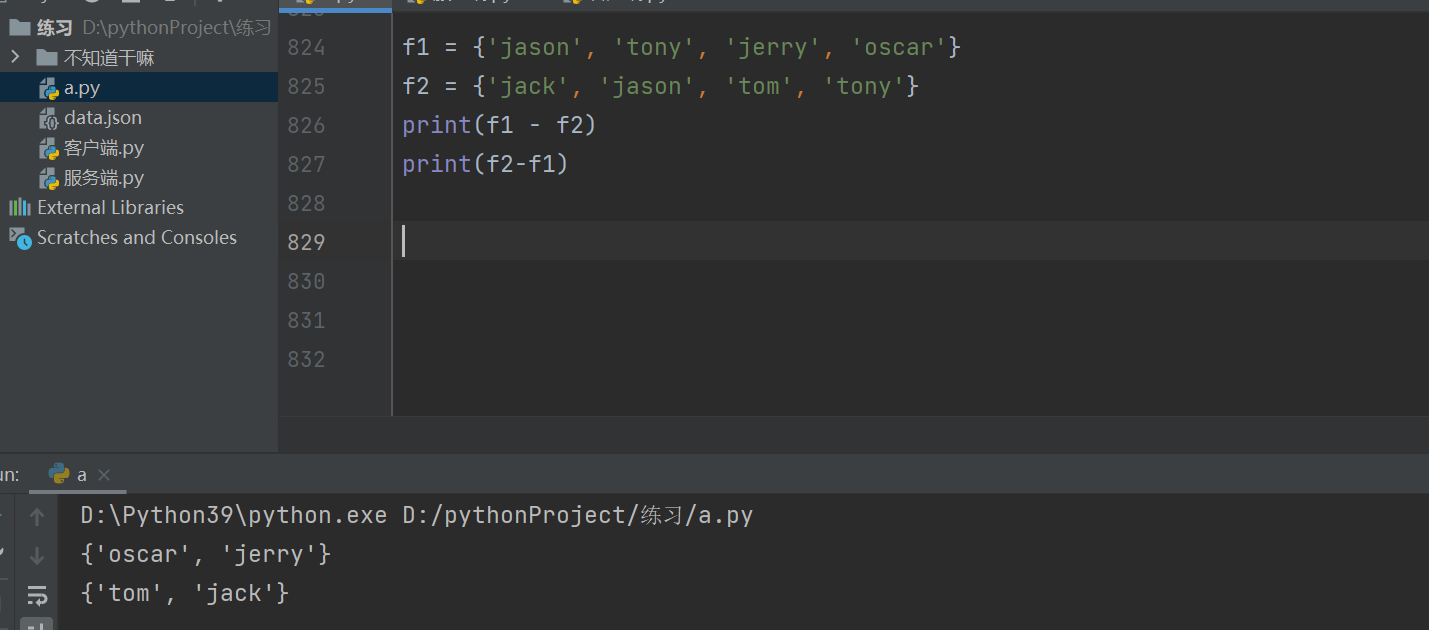
一个元组的独有数据 元组-元组
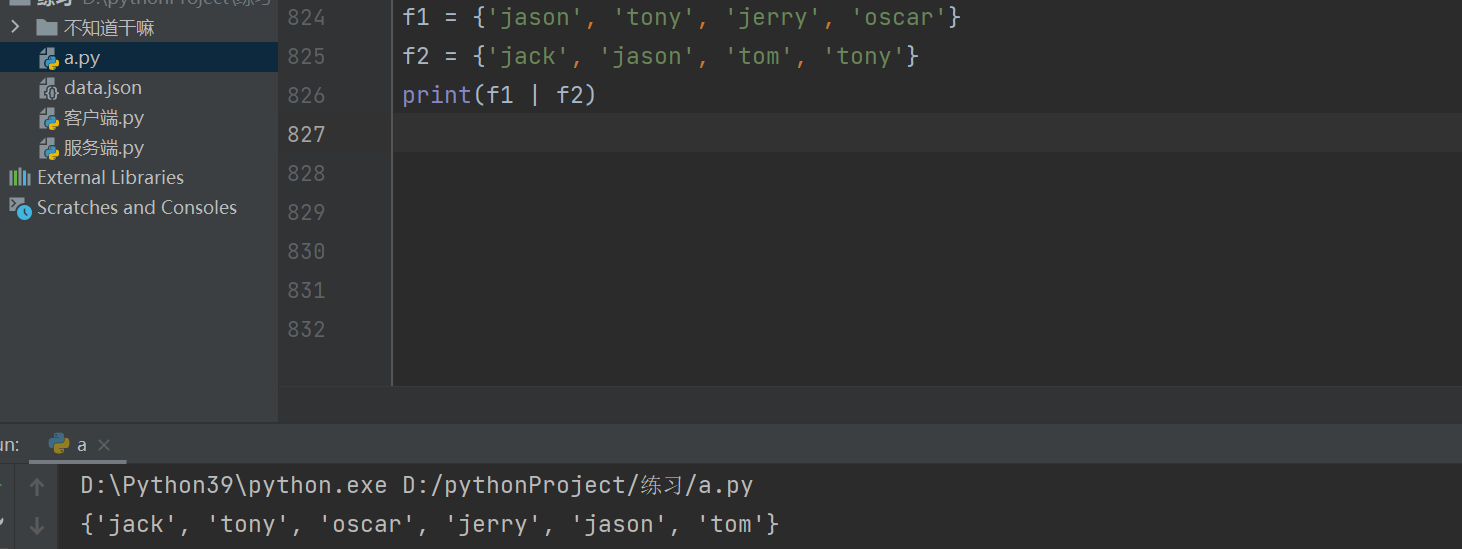
两个元组所有的数据 元组|元组
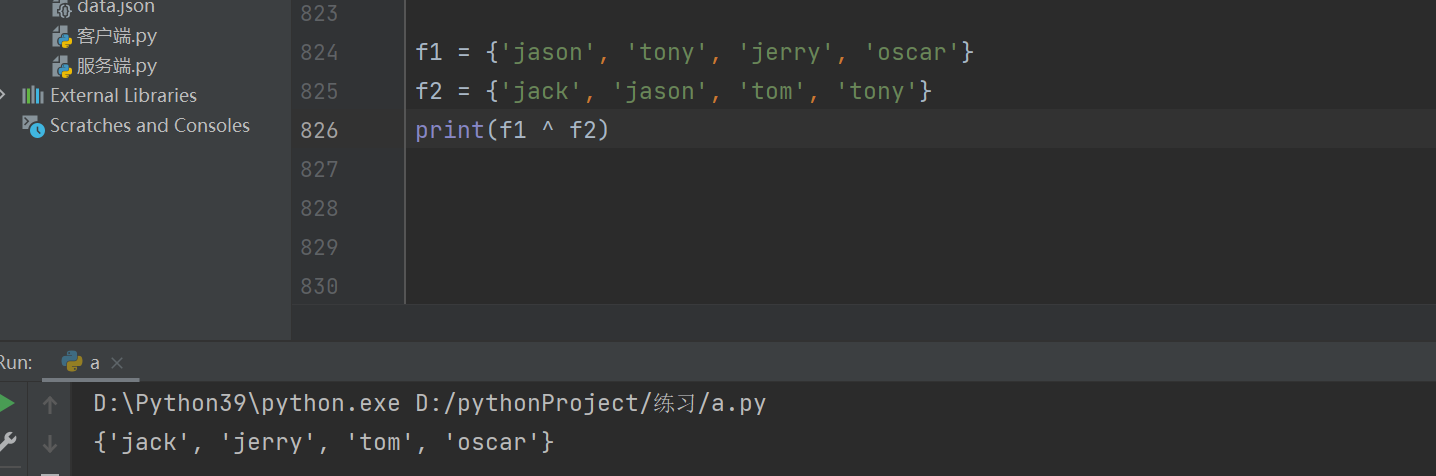
两个元组不同的数据 元组^元组
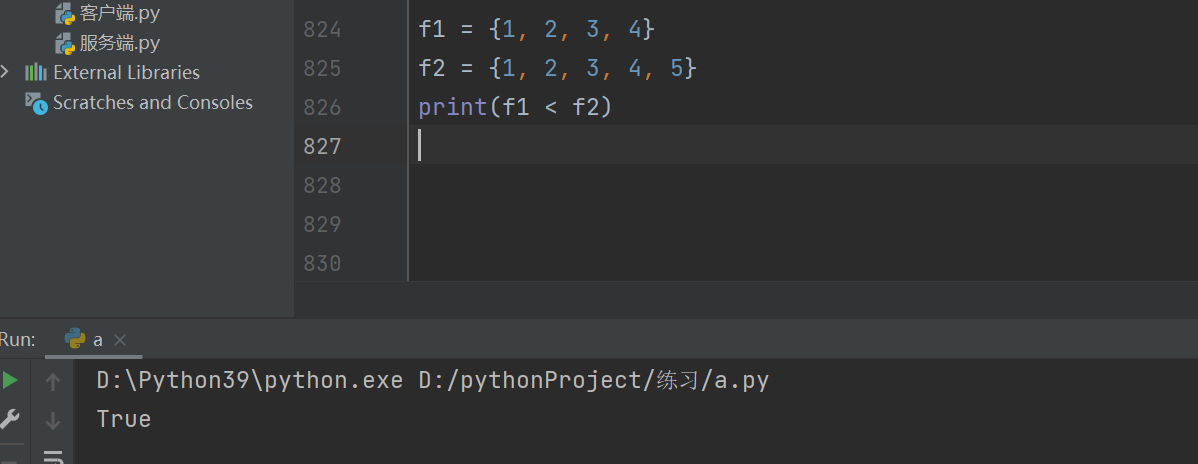
元组的父集和子集 元组1《元组2 元组2是元组1的父集
字符编码
字符编码只针对文本数据
不同国家的文本数据无法直接交互 会出现"乱码"
英文还是采用一个字节中文三个字节
编码:将人类的字符按照指定的编码编码成计算机能够读懂的数据:字符串.encode()
解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂:bytes类型数据.decode()
文件操作方法
代码打开文件的方法
变量名 = open(文件路径,打开模式,encoding=‘utf8’)
变量名.close
whit open(‘文件路径’,‘打开模式’,encoding=‘utf8’)as 变量名:
变量名.read()
with支持一次打开多个文件
with open()as 变量名,open()as 变量名,open()as变量名:
变量名.read(),变量名.read(),变量名.read()
文件读写模式方法
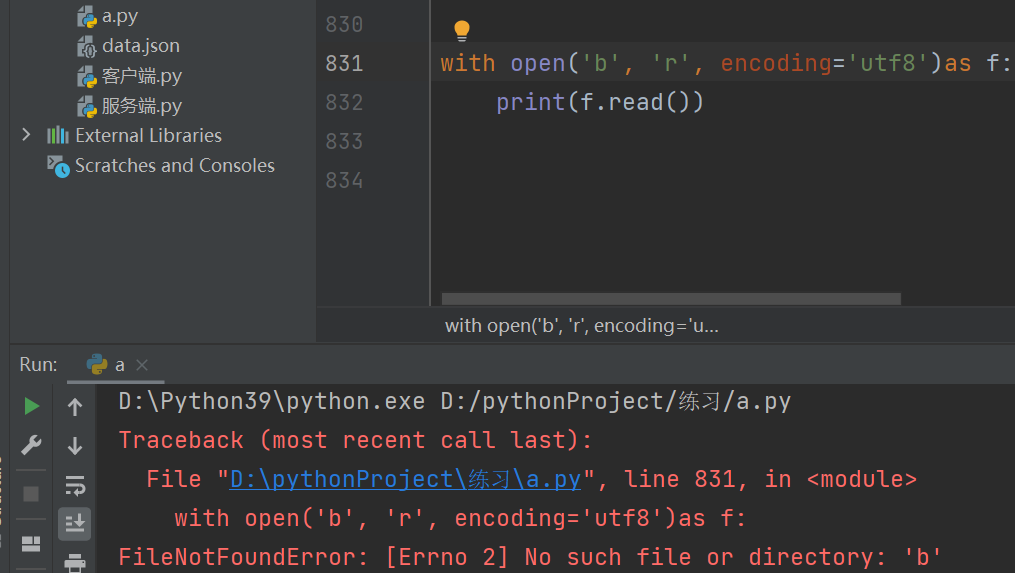
‘r’ 只能读不能写
文件路径不存在直接报错
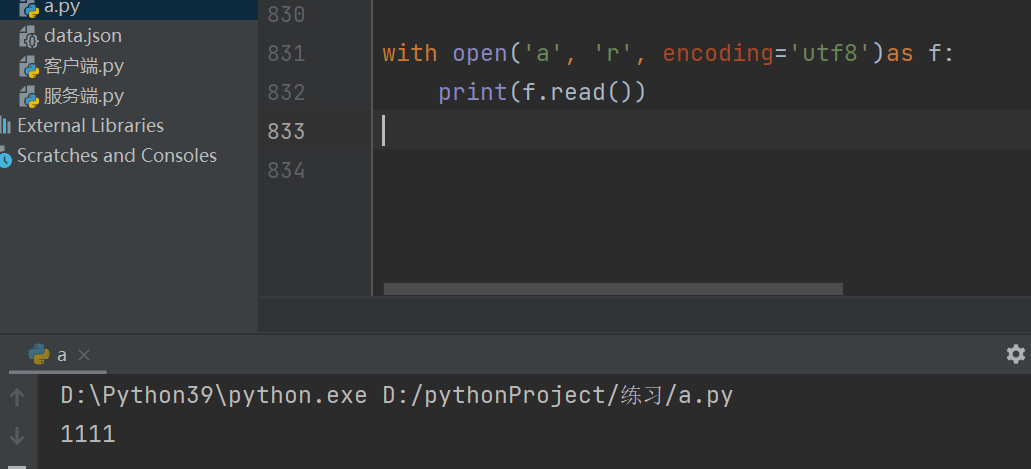
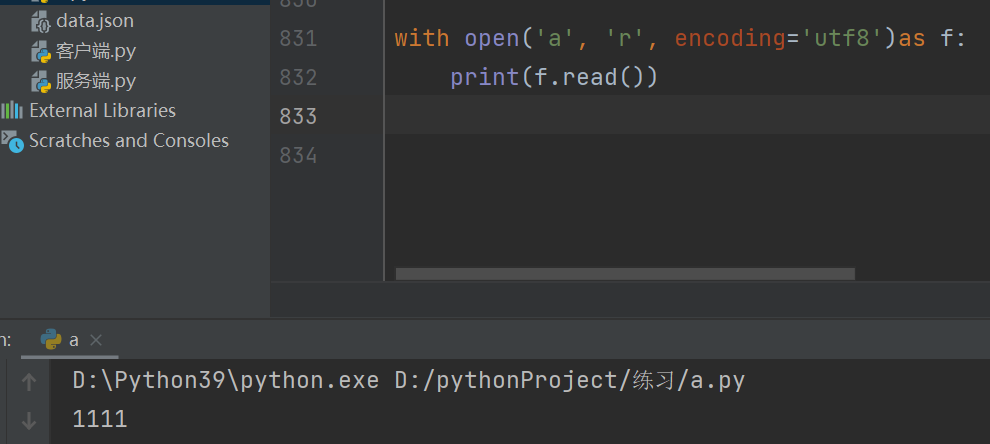
with open(‘a’,‘r’,encoding=‘utf8’)as f:
print(f.read)

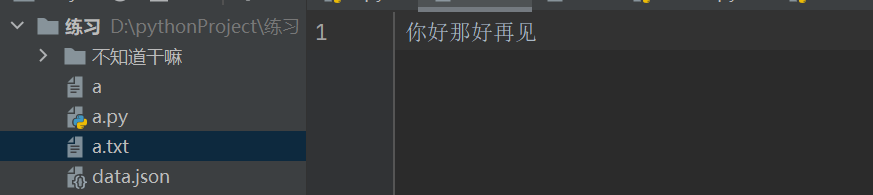
‘w’ 只能写进去(文件不存自动创建)文件路径存在:先清空文件内容 之后再写入
with open(‘a.txt’,‘w’,encoding='utf8')as f:
f.write('写入内容')

'a'文件路径不存在:自动创建,文件路径存在:自动在末尾等待追加内容
with open(r'a.txt', 'a', encoding='utf8') as f:
f.write(‘写人内容’)

文件操作方法
t 文本模式
默认的模式r w a其实全称是 rt wt at
只能操作文本文件
读写都是以字符为单位
需要指定encoding参数如果不知道则会采用计算机默认的编码
b 二进制模式(bytes模式)
不是默认的模式需要自己指定 rb wb ab
可以操作任意类型的文件
读写都是以bytes为单位
不需要指定encoding参数因为它已经是二进制模式了不需要编码
注意二进制模式与文本模式针对文件路径是否存在的情况下规律是一样的
文件操作方法
.read()
一次性读取文件内容并且光标停留在文件末尾继续读取则没有内容
并且当文件内容比较多的时候该方法还可能会造成计算机内存溢出
括号内还可以填写数字 在文本模式下 表示读取几个字符
.readline()
一次只读一行内容
.readlines()
一次性读取文件内容会按照行数组织成列表的一个个数据值
.readable()
判断文件是否具备读数据的能力
.write()
写入数据
.writeable()
判断文件是否具备写数据的能力
.writelines()
接收一个列表一次性将列表中所有的数据值写入
.flush()
将内存中文件数据立刻刷到硬等价于ctrl + s


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~