
想要做读写分离,送你一些小经验
读写分离是应用中提升数据访问性能最常见的一种技术,当用户量越来越多,访问量越来越大,单节点数据库难免会遇到性能瓶颈。很多场景基本上都是读多写少,所以增加多个从节点来分担主节点的压力自然是水到渠成的事情。
在应用接入读写分离后,难免会有一些我们意料之外的问题,这篇文章主要给大家介绍下一些经常会遇到的问题,有其他的问题欢迎留言补充。
分库分表之前的文章可以查看:http://mp.weixin.qq.com/mp/homepage?__biz=MzIwMDY0Nzk2Mw==&hid=4&sn=1b96093ec951a5f997bdd3225e5f2fdf&scene=18#wechat_redirect
实现方式
对于读写分离的使用,主要分为两种方式,客户端方式和代理方式。
客户端方式可以自己用 Spring 自带的 AbstractRoutingDataSource 来实现,也可以用开源的框架来实现,比如 Sharding-JDBC。

代理方式需要编写代理服务来对所有节点进行管理,应用不需要关注多个数据库节点信息。可以自己实现,也可以用开源的框架,也可以用商业的云服务。

数据延迟
谈到数据延迟,你先得理解主从架构的原理。对数据的增删改操作在主库上执行,查询在从库上执行,当数据刚插入到主库,然后马上去查询的时候,很有可能数据还没同步到从库上,就会出现查询不到的情况。
像我之前在某些网站发表文章,发表之后跳转到列表页面,发现没有新发表的文章,重新刷新下页面又有了,这一看这就是读写分离后的数据延迟导致的现象。
强制路由
数据延迟要不要解决,一般取决于业务场景。对于实时性要求没有那么高的业务场景,允许一定的延迟,对于实时性要求高的场景,唯一的方式就是直接从主库进行查询,这样才能及时读到刚插入或者修改后最新的数据。
强制路由就是一种解决方案,也就是将读请求强制分发到主库进行查询。大部分中间件都支持 Hint 语法/FORCE_MASTER/和/FORCE_SLAVE/。
以 Sharding-JDBC 举例,框架提供了 HintManager 来强制路由,使用方式如下:
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
为了方便使用,建议封装一个注解,在需要实时查询的业务方法上加上注解,通过切面进行强制路由的设置。
注解使用:
@MasterRoute
@Override
public UserBO getUser(Long id) {
log.info("查询用户 [{}]", id);
if (id == null) {
throw new BizException(ResponseCode.PARAM_ERROR_CODE, "id不能为空");
}
UserDO userDO = userDao.getById(id);
if (userDO == null) {
throw new BizException(ResponseCode.NOT_FOUND_CODE);
}
return userBoConvert.convert(userDO);
}
切面设置:
@Aspect
public class MasterRouteAspect {
@Around("@annotation(masterRoute)")
public Object aroundGetConnection(final ProceedingJoinPoint pjp, MasterRoute masterRoute) throws Throwable {
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
try {
return pjp.proceed();
} finally {
hintManager.close();
}
}
}
事务操作
在事务中的读请求,走主库还是从库呢?对于这个问题,最简单的方式就是所有事务中的操作都走主库,在事务中经常会存在插入,然后再重新查询的场景,此时事务没提交,就算同步很快,从库也是没有数据的,所以只能走主库。
但还有一些请求,只需要查询从库就行了,如果针对所有事务中的操作都强制路由,也不是很好。在 Sharding-JDBC 中的做法挺好的,对于同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。如果我们在数据写入之前有查询请求,还是走的从库,减轻主库压力。
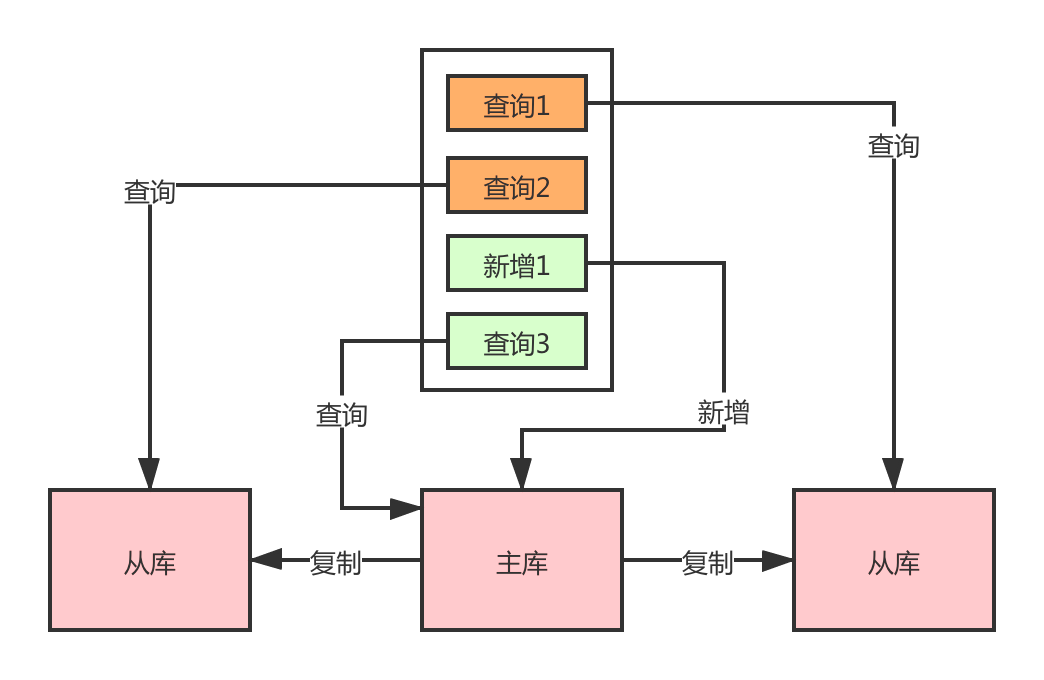
动态强制路由
在功能开发的时候就决定了哪些接口要强制走主库,这个时候我们会在代码上进行路由的控制,也就是前面讲的自定义注解。如果有些是没有加的,但是在线上运行的时候发现还是要走主库才可以,这个时候就需要改代码重新发布了。
动态强制路由可以结合配置中心来实现,通过配置的方式来决定哪些接口要强制路由,然后在 Filter 中通过 HintManager 来设置,避免改代码重启。
也可以通过切面精确到业务方法级别的动态路由配置。
流量分发
场景一:
假设你有一个主节点,两个从节点,读请求较多,两个从节点压力有点大。这个时候只能增加第三个从节点来分担压力。现象是主库的压力并不大,写入较少,从成本来考虑,是否可以不增加第三个从节点呢?
场景二:
假设你有一个 8 核 64G 的主库,8 核 64G 的从库,4 核 32G 的从库,从配置上来看,4 核 32G 的从库处理能力肯定是要低于其他两个的,这个时候如果我们没有定制流量分发的比例,就会出现低配数据库压力过高而导致的问题。当然这个也能避免使用不同规则的从库。
上面的场景需要能够对请求进行管理,在 Sharding-JDBC 中提供了读写分离的路由算法,我们可以自定义算法来进行流量的分发管理。
实现算法类:
public class KittyMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private RoundRobinMasterSlaveLoadBalanceAlgorithm roundRobin = new RoundRobinMasterSlaveLoadBalanceAlgorithm();
@Override
public String getDataSource(String name, String masterDataSourceName, List<String> slaveDataSourceNames) {
String dataSource = roundRobin.getDataSource(name, masterDataSourceName, slaveDataSourceNames);
// 控制逻辑,比如不同的从节点(配置不同)可以有不同的比例
return dataSource;
}
@Override
public String getType() {
return "KITTY_ROUND_ROBIN";
}
@Override
public Properties getProperties() {
return roundRobin.getProperties();
}
@Override
public void setProperties(Properties properties) {
roundRobin.setProperties(properties);
}
}
基于 SPI 机制的配置:
org.apache.shardingsphere.core.strategy.masterslave.RoundRobinMasterSlaveLoadBalanceAlgorithm
org.apache.shardingsphere.core.strategy.masterslave.RandomMasterSlaveLoadBalanceAlgorithm
com.cxytiandi.kitty.db.shardingjdbc.algorithm.KittyMasterSlaveLoadBalanceAlgorithm
读写分离的配置:
spring.shardingsphere.masterslave.load-balance-algorithm-class-name=com.cxytiandi.kitty.db.shardingjdbc.algorithm.KittyMasterSlaveLoadBalanceAlgorithm
spring.shardingsphere.masterslave.load-balance-algorithm-type=KITTY_ROUND_ROBIN
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud 微服务-全栈技术与案例解析》, 《Spring Cloud 微服务 入门 实战与进阶》作者, 公众号猿天地发起人。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架