
爬虫基础(3)
数据提取的概念和数据的分类
1. 什么是数据提取
简单的来说,数据提取就是从响应中获取我们想要的数据的过程
2. 爬虫中数据的分类
- 结构化数据:json,xml等
- 处理方式:直接转化为python类型
- 非结构化数据:HTML
- 处理方式:正则表达式、xpath
数据提取之json
1.为什么要复习json
由于把json数据转化为python内建数据类型很简单,所以爬虫中,如果我们能够找到返回json数据的URL,就会尽量使用这种URL,而很多地方也都会返回json
2. 什么是json
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
3.哪里能找到返回json的url
3.1 我们如何确定数据在哪里
在url地址对应的响应中搜索关键字即可
但是注意:url地址对应的响应中,中文往往是被编码之后的内容,所以更推荐大家去搜索英文和数字;另外一个方法就是在perview中搜索,其中的内容都是转码之后的
3.2 切换手机版寻找返回json的地址
在chrome中点击切换手机版的选项,需要重新刷新页面才能够切换成功,部分网站还需要重新进入主页面之后再继续点击才能够切换成功,比如:豆瓣热映
现在我们找到了返回电影数据的地址:https://m.douban.com/rexxar/api/v2/subject_collection/movie_showing/items?os=android&for_mobile=1&callback=jsonp1&start=0&count=18&loc_id=108288&_=1524495777522
通过请求我们发现,并不能成功,那是为什么呢?
对比抓包的地址和现在的地址,会发现部分headers字段没有,通过尝试,会发现是Referer字段缺少的原因
在上面这个地址中,我们会发现响应中包含部分数据并不是我们想要的,如下:
;jsonp1({"count": 18, "start": 0, "subject_collection_items": "...."})
其中jsonp1似乎是很眼熟,在请求的地址中包含一个参数callback=jsonp1,正是由于这个参数的存在,才导致结果中也会有这部分数据,对应的解决方法是:直接删除url地址中的callback字段即可,在url地址中很多字段都是没用的,比如这里的&loc_id,_等等,可以大胆尝试
3.3 json数据格式化方法
- 在preview中观察,注意json分为键值对
-
在线解析工具进行解析
- 比如:https://www.bejson.com/
-
pycharm进行reformat code,
- 在pycharm中新建一个json文件,把数据存入后,点击code下面的reformat code,但是中文往往显示的是unicode格式
3.4 json数据的其他来源
抓包app,app的抓包方式会在后面学习,但是很多时候app中的数据是被加密的,但是仍然值得尝试
4.json模块中方法的学习
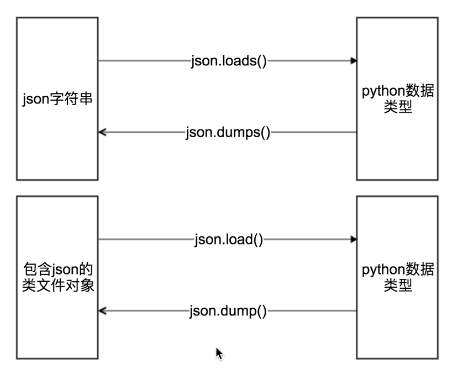
具有read()或者write()方法的对象就是类文件对象,比如f = open(“a.txt”,”r”) f就是类文件对象
#json.dumps 实现python类型转化为json字符串 #indent实现换行和空格 #ensure_ascii=False实现让中文写入的时候保持为中文 json_str = json.dumps(mydict,indent=2,ensure_ascii=False) #json.loads 实现json字符串转化为python类型 my_dict = json.loads(json_str) #json.dump 实现把python类型写入类文件对象 with open("temp.txt","w") as f: json.dump(mydict,f,ensure_ascii=False,indent=2) # json.load 实现类文件对象中的json字符串转化为python类型 with open("temp.txt","r") as f: my_dict = json.load(f)
5. json模块的作用

Json在数据交换中起到了一个载体的作用,承载相互传递的数据

