

学习操作系统P5 并发控制:互斥 (自旋锁、互斥锁和 futex)
视频:https://www.bilibili.com/video/BV1ja411h7jt/?spm_id_from=333.999.0.0&vd_source=7a1a0bc74158c6993c7355c5490fc600
啊

啊

Peterson算法实现互斥的效率其实很低
如何正确地在多处理器上实现互斥呢?
啊

啊

啊

啊

啊

啊

啊

啊

啊

上下两段代码在描述同一个东西,但上面的代码更好理解(前面一张图的图形化解释更好理解,也是在描述同一种互斥协议)
下面的视角比较难理解
啊

调试并发程序的两个方法:
1. 尽可能详尽的测试
2. 尽可能的证明(model checker)
啊
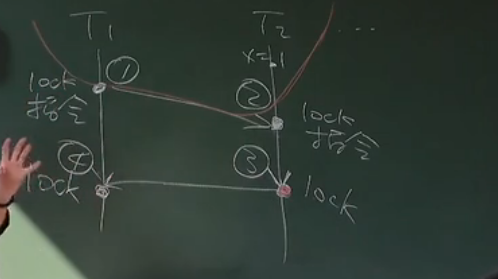
处理器实现的 “原子指令” 从根本上消灭了并行,它保证两个事情:
1. 每一个针对同一个关键对象的原子指令,在同一时间只有一个被执行,即,它们可以按时间顺序排成 1 2 3 4
2. 每一个原子指令在被执行时,在它之前被执行的原子指令所产生的结果,对于当下这个将要被执行的原子指令都是可见的
啊
由于在C语言中,给变量上把锁实际上是在给内存中的某一个数据上锁,会涉及到总线。
所以实际上是在总线上上锁
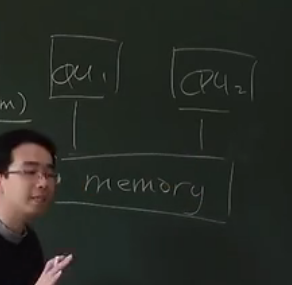
当两个CPU都想给内存上锁时,总线会决定谁先上锁、谁要等待。
不过,今天的CPU由于有缓存,内存锁的这个问题会更加复杂,如下图
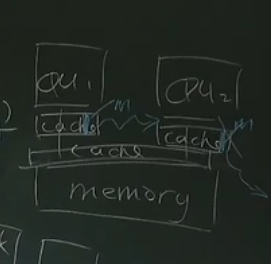
当两个CPU的内存里都有一个变量m时,如果CPU1要给变量m加锁,那么它必须把其它CPU的缓存里的变量m都给清除掉
所以,今天的 intel 多核CPU,所有core的L1 cache都是互联的(缓存一致性)。



RISCV的一种很神奇的原子性操作的想法:
对关键变量的访问,都可以分成 Load(读) Exec(计算) Store(写) 三个步骤
当我在读取一个内存数据时,我把它读出来,然后在它旁边加上一个标记,称为 Load-Reserved
接着开始做计算 Exec
做完计算后,尝试把新值写入变量,如果此时:
1. 我之前加上的标记被消除了(其它core写入那个变量会消除标记);那么放弃写入,重新开始读写该关键变量。
2. 如果标记没有被消除,说明这段时间没有其它core写入这个变量,可以直接把新值写入该变量

上下这两段代码只是阐明 Compare-and-Swap 的思想
(在计算机科学中,比较交换(CAS)是用于多线程以实现同步的原子指令。 它将存储位置的内容与给定值进行比较,并且只有它们相同时,才将该存储位置的内容修改为新的给定值。 这是作为单个原子操作完成的。)
LR/SC+cas 除了实现原子操作,还可以检测原子操作的拥堵
LR/SC+cas 在失败时,就知道有人在跟自己竞争
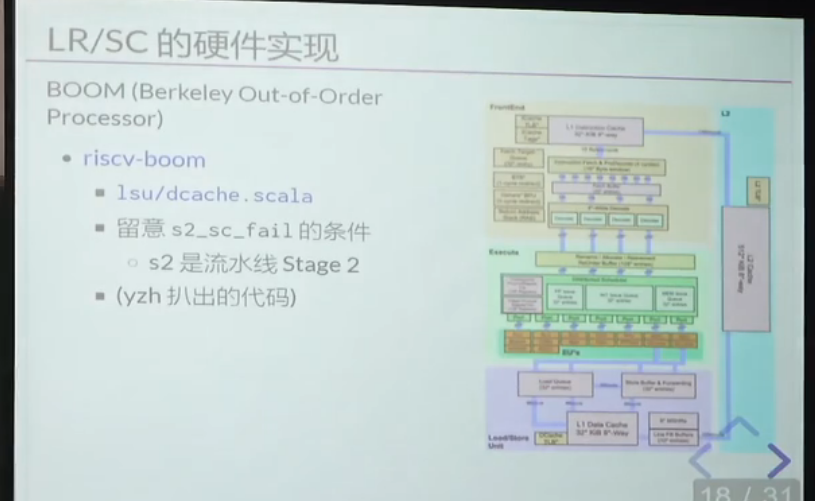


0. 正在尝试拿锁的人会不停的触发 lock 指令,引起处理器间的缓存同步
1. 空转
2. 获得自旋锁的线程也可能被操作系统切换出去,造成 100% 资源浪费
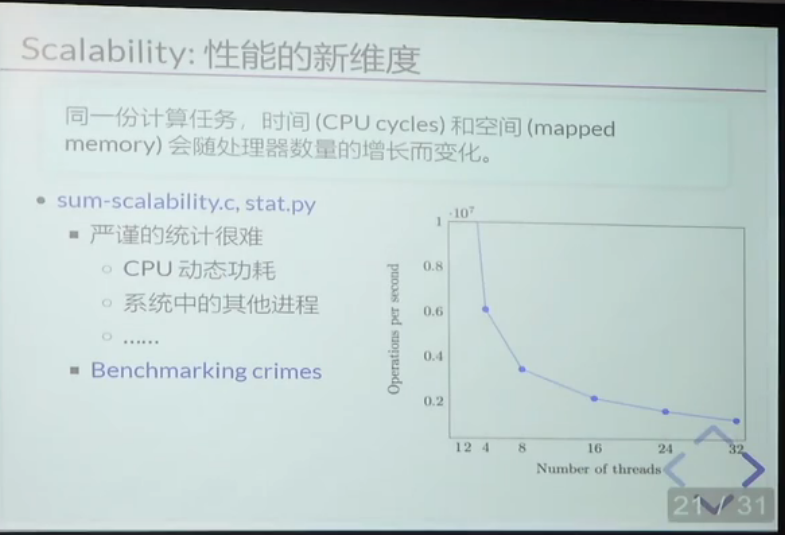
有些时候,进行同一个计算任务的线程越多,并不代表效率越高。
原因是刚刚提到的三个 “自旋锁的缺陷” 性能问题

记录了一些 做 System 科研时,做Benchmarks 可能出现的错误

自旋锁真正的使用场景是操作系统内核的并发数据结构
虚拟机关中断并不会真正把中断关掉(不然虚拟机死机会引起物理机死机),采用的是一些其它的机制

想要实现用户态线程的互斥其实很容易



性能优化的常见技巧:看 average(frequent) case 而不是 worst case
在 pthread 中,spinlock 更快的 fastpath。 mutexlock(实际实现方式就是 futex) 更快的 slow path
在撞锁程度较少时,pthread还是使用原子指令;在撞锁程度较高时,pthread会使用睡眠锁

即便 Futex 的设计者,第一次写Futex也是错误的。
所以,不要好高骛远,解决问题时先用简单的方法,不要考虑性能,然后再迭代
善用 model checker 等调试和可视化工具


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?