

学习操作系统P3 多处理器编程:从入门到放弃 (线程库;现代处理器和宽松内存模型)
啊

啊

啊

啊

操作系统会自动把线程放置在不同的处理器上
可以用top观察CPU使用率
啊



啊
啊

啊
a
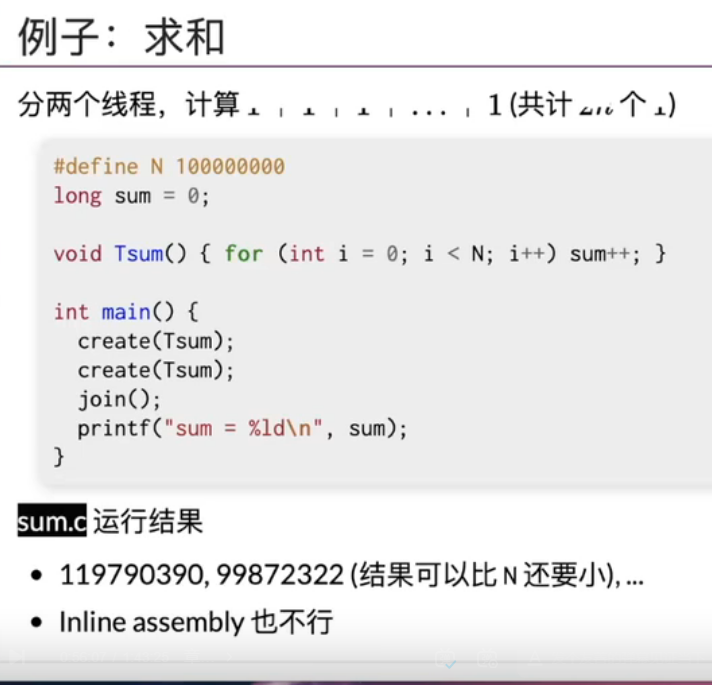
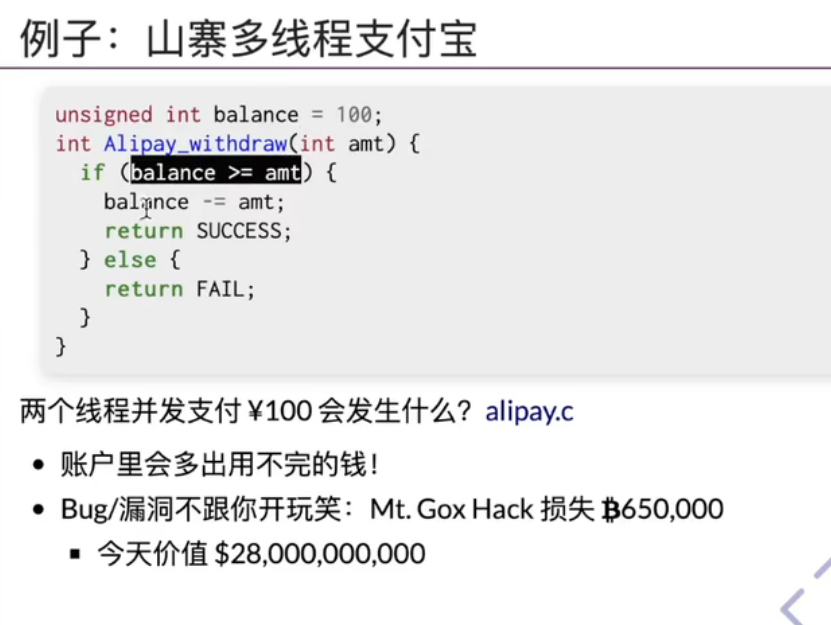
甚至连一个简单的求和程序都做不对
a

汇编语言中的 lock: CPU的特性,通过总线加锁,解决多处理器的并发问题
啊

啊

a

a

a
a

a
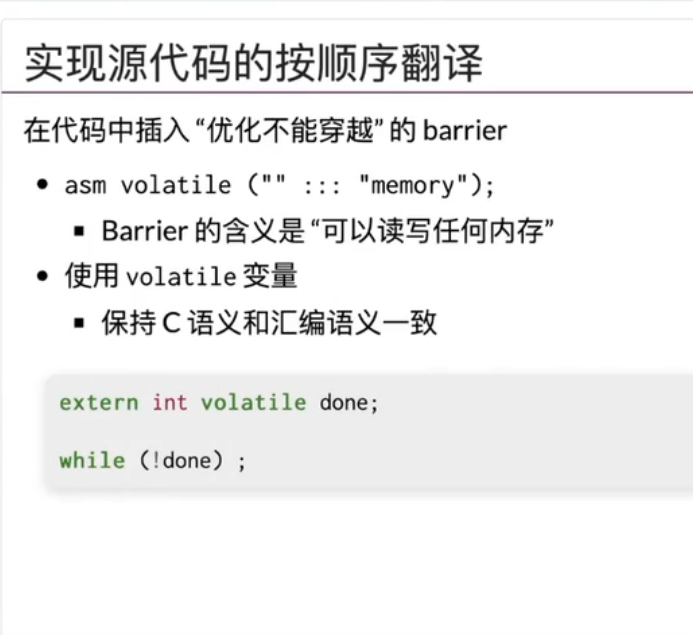
a
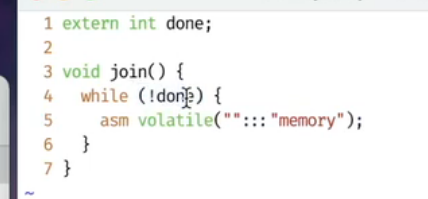
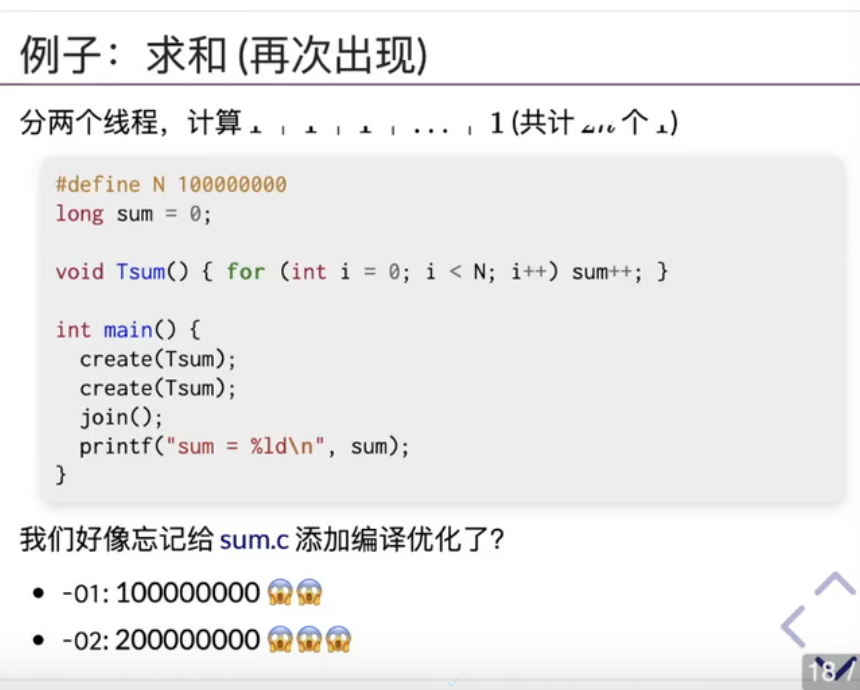
asm volatile("":::"memory"); 用来告诉编译器这里不要优化
a

a
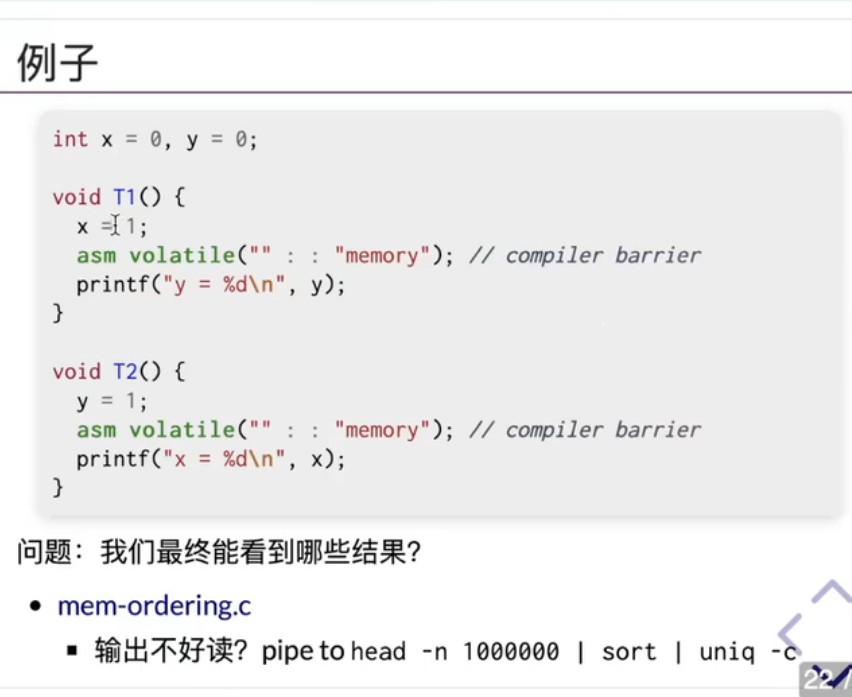
这里的 asm volatile("" : : "memory"); 的作用是:防止编译器把 printf 放到 y = 1 前面
根据jyy画出的状态机所示,这个代码有可能的结果只有
x = 0, y = 1;
x= 1, y= 0;
x = 1, y = 1;
无论如何不可能得到 x=0 y =0
a
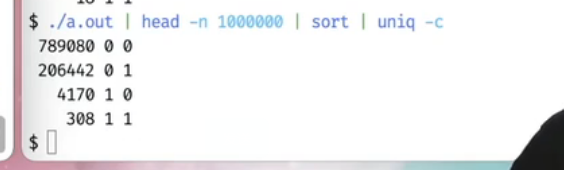
然而,实际上,我们得到了 0 0,原因是什么呢?
啊

在CPU里,汇编指令会被翻译成更小的 u OPs,并且重排
今天的处理器基本就是在 乱序执行 的框架下,不停做各种优化
啊

在执行到 movl $1, (x) 时,已经 cache miss
乱序处理器在等待 cache 的时候会继续执行下一条指令,从而导致 多处理器间即时可见性的丧失
TODO: 这一段实话说看不懂,也许我应该做完CPU cache 的部分再来看
啊
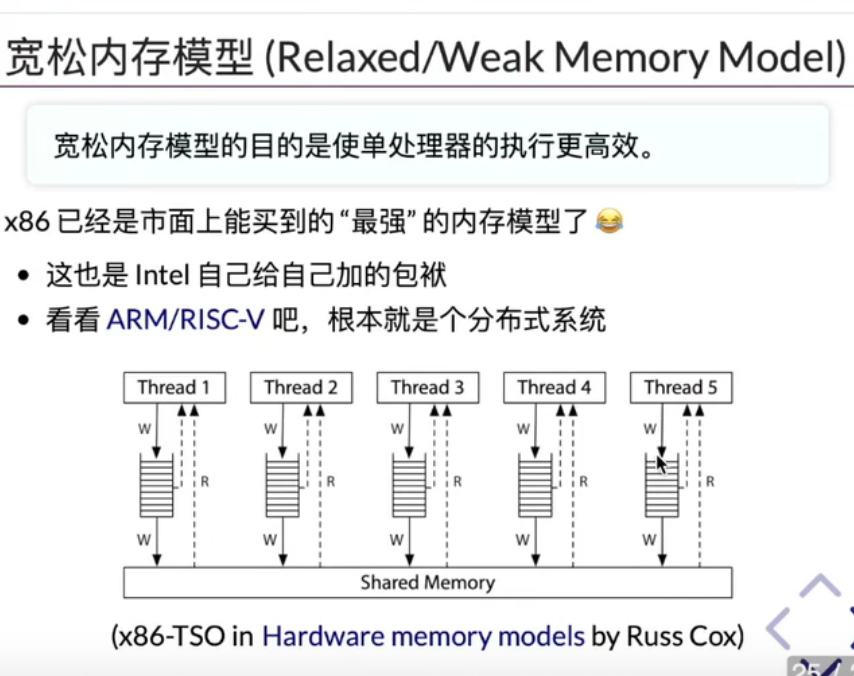
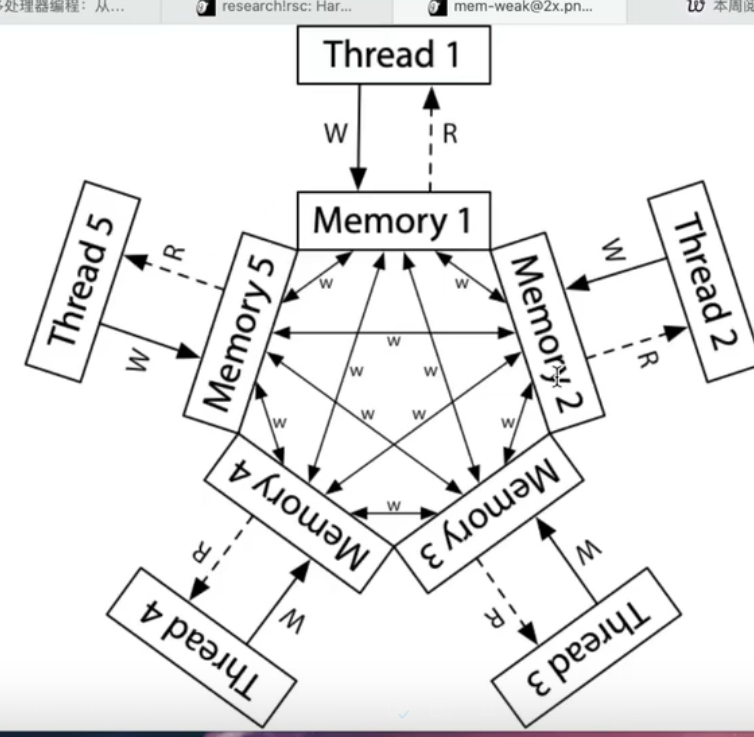
ARM 和 RISC-V 的内存模型更差,很难保证内存的一致性
啊

解决方案:加上 mfence
mfence 保证内存写入共享内存以后,才可以执行下一条指令
啊

啊


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?