B站视频下载批量拼接合成工具
简介说明
B站对于单个视频的下载很简单,可以在浏览器装插件,这里不再赘述。本文主要介绍对于多P视频的批量下载,资源整合处理。
提供两种方式:
- 执行py脚本
- 运行exe工具
准备工作
1. 在windows应用商店下载B站客户端
2. 安装ffmpeg软件,并添加path环境变量,下载地址:https://ffmpeg.zeranoe.com/builds/。添加环境变量方法这里不再具体介绍,不懂可以百度。
3.pip安装ffmpy3模块(用exe工具不需要)
视频下载
打开客户端,可以自己设置下载路径,支持多集批量下载,,下载格式支持MP4,flv格式

但是下载下来的缓存文件,每种格式都会有问题,这也就是这个工具产生的原因。
1.批量下载的文件MP4格式为音频视频分割;
2.flv格式长视频进行了分切多个短视频;
3.视频文件名为数字串码
下载后的文件

功能介绍
1. 对于下载的MP4格式文件语音、视频合成,重命名。处理耗时较长,吃cpu,内存,不建议下载此格式
2. 对于下载的flv格式文件进行拼接,重命名
获取方法
1.脚本源文件


1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 """ 4 该脚本用于批处理Windows商店B站客户端下载文件。 5 说明: 6 1.批量下载的文件MP4格式为音频视频分割; 7 2.flv格式长视频进行了分切多个短视频; 8 3.视频文件名为数字串码 9 环境准备: 10 1. 下载ffmpeg软件并加载环境变量,下载地址:https://ffmpeg.zeranoe.com/builds/ 11 2. pip安装ffmpy3模块 12 功能: 13 1. 对于下载的MP4格式文件语音、视频合成,重命名。处理耗时较长,不建议下载此格式 14 2. 对于下载的flv格式文件进行拼接,重命名 15 """ 16 import json, os, datetime 17 from ffmpy3 import FFmpeg 18 19 # 源视频下载路径 20 source_dir = str(input("请输入视频源文件夹:")) 21 # 处理后视频的输出路径,并新建视频标题文件夹 22 target_dir = str(input("请输入输出文件夹:")) 23 24 25 def file_handler(root, files): 26 output_dir = "" 27 audio_path = "" 28 video_path = "" 29 flv_list = [] 30 31 for file in files: 32 33 if file.endswith(".info"): 34 file_name, dir_name = get_video_info(root, file) 35 save_dir = os.path.join(target_dir, dir_name) 36 if not os.path.exists(save_dir): 37 os.mkdir(save_dir) 38 output_dir = os.path.join(save_dir, file_name) 39 40 if file.startswith("audio"): 41 audio_path = os.path.join(root, file) 42 if file.startswith("video"): 43 video_path = os.path.join(root, file) 44 if file.endswith(".flv"): 45 flv_list.append(os.path.join(root, file)) 46 return output_dir, audio_path, video_path, flv_list 47 48 49 def get_video_info(root, file): 50 json_dir = os.path.join(root, file) 51 with open(json_dir, "r", encoding="utf-8")as f: 52 info_dic = json.load(f) 53 file_name = info_dic['PartName'] 54 file_name = file_name.replace(" ", "") 55 dir_name = info_dic['Title'] 56 return file_name, dir_name 57 58 59 def mp4_handler(video_path, audio_path, output_dir): 60 ff = FFmpeg(inputs={str(video_path): None, str(audio_path): None}, 61 outputs={str(output_dir + '.mp4'): '-c:v h264 -c:a ac3 -v quiet -y'}) 62 # print(ff.cmd) 63 ff.run() 64 65 66 def creat_flv_list_file(root, flv_list): 67 flv_list_dir = os.path.join(root, "flv_list.txt") 68 with open(flv_list_dir, 'a', encoding='utf-8')as f: 69 for i in flv_list: 70 f.write("file '{}'\n".format(i)) 71 return flv_list_dir 72 73 74 def flv_concat(flv_list_dir, output_dir): 75 # 不加safe参数报错,-v quiet不显示处理过程,-y覆盖已存在 76 ff = FFmpeg(global_options="-f concat -safe 0 ", inputs={str(flv_list_dir): None}, 77 outputs={output_dir + '.flv': "-c copy -v quiet -y"}) 78 # print(ff.cmd) 79 ff.run() 80 81 82 def flv_handler(root, flv_list, output_dir): 83 flv_list_dir = creat_flv_list_file(root, flv_list) 84 flv_concat(flv_list_dir, output_dir) 85 if os.path.exists(flv_list_dir): 86 os.remove(flv_list_dir) 87 88 89 if __name__ == '__main__': 90 start = datetime.datetime.now() 91 total = 0 92 count = 0 93 94 for root, dirs, files in os.walk(source_dir): 95 runtime = datetime.datetime.now() - start 96 if not total: 97 total = len(dirs) 98 print("\r正在处理:第{}个 " 99 "共:{}个 " 100 "已用时:{}".format(count, total, runtime), end='') 101 count += 1 102 103 is_video = file_handler(root, files) 104 if is_video: 105 output_dir, audio_path, video_path, flv_list = is_video 106 if video_path and audio_path and output_dir: 107 mp4_handler(video_path, audio_path, output_dir) 108 if output_dir and flv_list: 109 # print(flv_list) 110 flv_handler(root, flv_list, output_dir) 111 print("\n已全部处理完成!")
GitHub项目地址:https://github.com/yin-man/bilibli_video
2.打包后的exe工具
https://files.cnblogs.com/files/yinhaiping/bilibili.zip
使用方法
输入下载的文件路径=>Enter=>输入要输出的文件路径=>Enter=>wait.......
对于一部1.1G的flv视频处理时间约为10s,速度还是相当快的
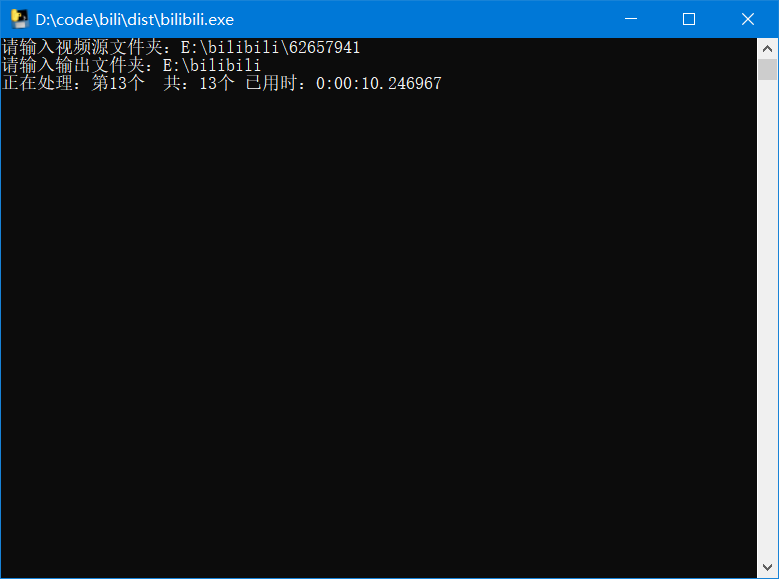
处理后的展示


最后
使用过程中,如遇到问题,欢迎评论留言。
2020-05-28更新
最近B站增加了视频合并功能,脚本更新如下:
#!/usr/bin/env python # -*- coding:utf-8 -*- import os, json from shutil import copyfile # 源视频下载路径 source_dir = input("请输入视频源文件夹:") # 处理后视频的输出路径,并新建视频标题文件夹 target_dir = input("请输入输出文件夹:") def get_video_info(json_dir): with open(json_dir, "r", encoding="utf-8")as f: info_dic = json.load(f) file_name = info_dic['PartName'] dir_name = info_dic['Title'] return file_name, dir_name for root, dirs, files in os.walk(source_dir): path_l = [] output_dir = '' for file in files: path_l.append(os.path.join(root, file)) for path in path_l: if path.endswith('.info'): file_name, dir_name = get_video_info(path) save_dir = os.path.join(target_dir, dir_name) if not os.path.exists(save_dir): os.mkdir(save_dir) output_dir = os.path.join(save_dir, file_name) for path in path_l: if not output_dir: break if path.endswith('.mp4'): copyfile(path, output_dir + '.mp4') if path.endswith('.flv'): copyfile(path, output_dir + '.flv')
#!/usr/bin/env python # -*- coding:utf-8 -*- import os, json from shutil import copyfile # 源视频下载路径 source_dir = input("请输入视频源文件夹:") # 处理后视频的输出路径,并新建视频标题文件夹 target_dir = input("请输入输出文件夹:") def get_video_info(json_dir): with open(json_dir, "r", encoding="utf-8")as f: info_dic = json.load(f) file_name = info_dic['PartName'] dir_name = info_dic['Title'] return file_name, dir_name index = 1 for root, dirs, files in os.walk(source_dir): path_l = [] output_dir = '' for file in files: path_l.append(os.path.join(root, file)) for path in path_l: if path.endswith('.info'): file_name, dir_name = get_video_info(path) file_name=str(index)+'、'+file_name save_dir = os.path.join(target_dir, dir_name) if not os.path.exists(save_dir): os.mkdir(save_dir) output_dir = os.path.join(save_dir, file_name) for path in path_l: if not output_dir: break if path.endswith('.mp4'): copyfile(path, output_dir + '.mp4') index += 1 if path.endswith('.flv'): copyfile(path, output_dir + '.flv') index += 1

