


显著性论文学习阶段总结(一)
1.Mingming Cheng,Global Contrast based Salient Region Detection,CVPR2011
1) HC:基于直方图对比度的方法,每一个像素的显著性值是由它与图像中所有其他像素的颜色差异来确定,得到全分辨率显著性图像;
2) RC:基于局部对比度的方法,先将图像分割成小区域,采用的分割方法是基于图的分割,基本分割思想是将每个像素点作为无向图的顶点,两个像素点之间的不相似度作为边的权重,要求连接相同区域内的两个顶点的边的最大权重要小于连接不同区域的顶点的边的最小权重,在迭代过程中进行顶点归纳与区域合并,具体参见论文Efficient graph-based image segmentation;每个区域的显著性值由它与其他所有区域的空间距离和区域像素数加权的颜色差异来确定;空间距离为两个区域重心的欧氏距离,较远区域分配较小权值;
3) 细节加速:
① 基于直方图的加速:将每个颜色通道由256个颜色值量化到12个颜色值后,对输入图像计算颜色直方图,保留高频颜色,覆盖95%图像像素,剩下颜色舍弃,用直方图中距离最近的颜色代替;
② 颜色空间平滑:减小量化误差,每个颜色的显著性值被替换为相似颜色显著性的加权平均;在RGB空间进行量化,用Lab空间度量距离;
4) 评价:基于HC的理论方法很简单,根据全局对比度计算显著度,计算速度快,对于背景较简单的图像效果也不错;RC改变了处理单元,由单个像素到图像块,速度较慢,效果并没有比HC提高很多,个人认为基于图的分割结果不够好,导致saliency map不均匀。
2.Yulin Xie,Visual Saliency Detection Based on Bayesian Model,ICIP2011
1) 基本流程:
① 检测显著目标的角点:颜色增强Harris角点检测。对输入的彩色图像计算颜色增强矩阵Mboost,用Mboost对输入图像进行颜色转换,计算颜色增强后的图像的Harris角点能量函数得到能量图,选取能量图中能量值最大的几个点,并剔除图像边界附近的点,得到较准确的显著点;
② 用一个凸包将所有显著点包围起来,得到显著区域的大致位置;
③ 将显著度计算等价为贝叶斯后验概率的计算:
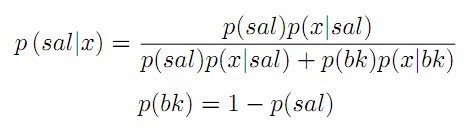
a. 先验概率p(sal):计算每个像素显著度。将输入图像进行超像素分割,计算每个超像素的平均颜色和空间位置;对凸包内外的超像素分别进行K-means聚类,计算凸包内每个cluster与凸包外所有clusters的平均颜色距离,最大距离对应的那个cluster为显著cluster;其他所有超像素的显著度由它与显著cluster内的超像素的空间和颜色距离来确定;将计算的所有显著值归一化到[0,1],作为贝叶斯框架的先验概率。
b. 观测概率p(x|sal),p(x|bk):分别计算凸包内区域和凸包外区域的Lab颜色直方图,对于任意像素点x特征值为Lab,分别找凸包内外直方图相同Lab值对应的各通道bin,计算各通道bin包含像素个数占总像素个数的百分比,三个百分比相乘。即框内外元素在框内和框外直方图占的比例。
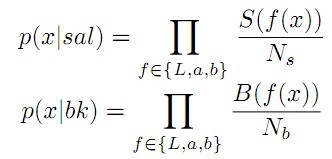
④ 由贝叶斯公式计算最终的saliency map
2) 评价:对于简单背景,效果也很好。Saliency map的准确度也很大部分取决于凸包的准确性,稍复杂背景会有很多的角点被检测到,经常会有显著范围过大的情况,即false positive。
3.Yun Zhai,Mubarak Shah,Visual Attention Detection in Video Sequences Using Spatiotemporal Cues,ACM2006
1) 系统框架:
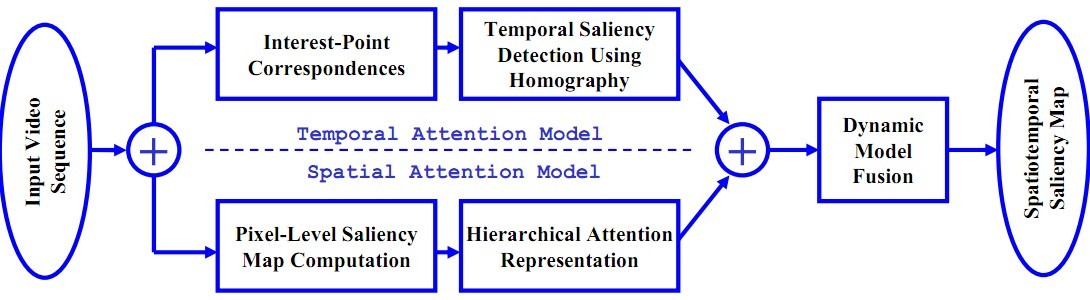
① 时域显著度模型
检测连续视频帧中的兴趣点,用SIFT建立兴趣点之间的对应,根据对应点计算单应性矩阵检测运动平面,RANSAC算法估计多个单应性矩阵来描述不同的运动模块;根据单应性矩阵得到投影点与实际点之间的投影误差计算该像素点的运动对比度,并加入单应性矩阵的跨越区域作为权重调节,避免纹理变化导致显著点分布不均匀的问题。
② 空域显著度模型
计算像素级的saliency map:该像素点颜色与图像中所有其他像素点的color distance map与其他像素点颜色直方图频率的乘积;
计算区域级的saliency map:采用区域增长算法,根据前面计算的显著点对显著区域进行初始化,以其为中心生成种子区域,通过计算区域边缘的能量进行迭代扩张,最终得到一个矩形显著区域。扩展的区域重叠时,采用区域合并技术;
③ 时域空域模型结合
动态结合,运动对比度较大时给时域显著度模型赋予较大权重,否则给空域显著度模型赋予较大权重。
2) 评价:基于视频的显著度检测,考虑帧间运动显著性信息,和图像自身显著性,值得进一步探索。速度较快,效果也比较稳定。
4.Xiaohui Shen,Ying Wu,A Unified Approach to Salient Object Detection via Low Rank Matrix Recovery,CVPR2012
1) 基本流程:文章提出了一种新的图像表示方法,将其表示为一个低秩矩阵(非显著区域)加上稀疏噪音(显著区域),再利用Robust PCA技术进行低秩矩阵恢复,得到的噪音就是显著区域,再根据高层次的先验知识来帮助修正显著区域。
2) 图像矩阵:
① 提取特征:R,G,B,hue,saturation,3尺度下4个方向共12个steerable pyramids响应,3尺度8方向共12个Gabor fileters响应,加起来一共53维。
② 矩阵构造:先利用Mean-shift算法将图像分割成很多较小的segments再用每个segment中所有特征向量的均值来表示这个segment,从而构造成为矩阵。
③ 特征空间变换:保证特征向量为低秩。
3) 高层先验融合:位置先验(基于图像中心高斯分布),语义先验(人脸检测),颜色先验(暖色更明显)
4) 评价:对图像的表示比较新颖,但实验效果一般,saliency map不均匀,提取特征多,计算量大,低秩矩阵恢复速度也比较慢
6.Ali Borji,Boosting Bottom-up and Top-down Visual Features for Saliency Estimation,CVPR2012
1) 主要贡献:
① 本文的主要出发点是一个贝叶斯公式的推导,在具有特征f的某位置x是salient的概率p是等式的左边,有如下:
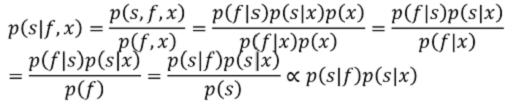
此处假设f与x相互独立,且先验概率p(s)相同,所以可以得到正相关最右。又有:
![]()
即与图片中心点的欧式距离相关,所以本文主要研究的是特征点和salient的对应关系。
② 将bottom-up和top-down联合,底层特征有方向,颜色,强度,颜色通道直方图及概率,金字塔模型,现有的底层显著图例如GBVS,Torralba模型,AWS模型;高层特征包括水平线检测,人车检测,人脸检测等。底层和高层加起来,每个pixel就对应一个34维的feature。
③ 测试了多种分类器对于显著图计算的贡献,采用online learning,先将feature matrix归一化,使其平均数是0,标准差是1,然后建立一个等大小的label map,每个点取值+1/-1,人眼观测的预测结果,top 20%标注+1,bottom 40% 标注-1。他将数据集分为N组,然后使用leave-one-out的方式进行训练和测试。测试分类器有回归分类器(regression),线性核的SVM和AdaBoost非线性分类器。实验表明Adaboost效果最好。
④ 评估指标:AUC值为ROC曲线与x轴之间距离的积分;NSS归一化扫描路径的显着性,描述saliency可以描述fixation的程度;线性相关系数CC表示saliency map和人眼关注map之间的线性关系,计算协方差。
2) 评价:论文内容上新意不大,底层特征与高层知识的结合,倒是提供了不少特征提取参考,以及各种分类器和评估准则的测试;没有进行代码测试,觉得计算量应该很大。
7.Federico Perazzi,Philipp Krahenbuhl,Saliency Filters: Contrast Based Filtering for Salient Region Detection
1) 基本思想:显著性一直以来都被认为应该是一个滤波器,该文作者想到了将其使用滤波器的方法进行加速。这篇文章主要是对局部和全局两种显著特征的公式进行了分析,提出了一种可以再线性时间内计算的方法。
2) 方法流程:
① 图像分割:采用略微修改的超像素分割,根据CIElab空间的测地线图像距离进行K-means聚类,产生大体上均匀尺寸,并且可以保持颜色边界的超像素分割。
② 颜色独立性:
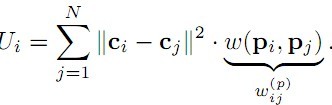
其中的权重与超像素空间位置的距离有关,如果这个值给予长距离很低的权重,这个颜色独立性就类似于中央周边的对比度,即距离远的像素对其显著性贡献较低;如果这个权重为常数,这个颜色权重就类似于Mingming Cheng论文里面的区域对比度。
这个公式也可以写成:
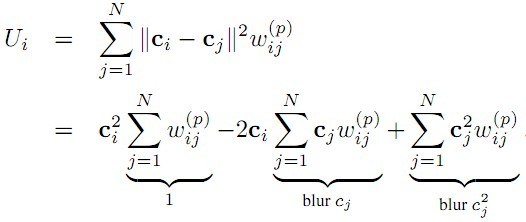
第一项的Σ结果是1,第二和第三项都可以看做是以ω为核的滤波器,分别对cj 和cj2滤波。本文将这个核写成了高斯的形式,并且借助Adams提出的permutohedral lattice embedding 滤波器来实现线性时间的计算。
③ 空间颜色分布:
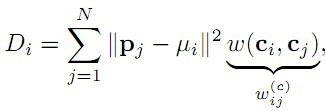
权重是颜色的差距,前面是空间距离。根据ω(ci,cj)定义,颜色越接近近权重越大,即距离远但颜色相近的像素分布值大,和前一个特征刚好是相反,这个特征可以表示某种颜色在空间分布的广度。例如某种颜色分散在图像中,但是面积都很小,那么第一个特征计算出来这个颜色的独立性就比较高,但是第二个特征会告诉你这个颜色的分布很广,并不显著。
通过类似的推导,这个公式也可以写成高斯滤波的形式,借助Adams提出的permutohedral lattice embedding 滤波器来实现线性时间的计算,具体参考论文Fast High-Dimensional Filtering Using thePermutohedral Lattice。
④ 显著性融合:

由于空间颜色分布的区分度更大,因此作者将其放在了指数的位置,并加了一个权重调节。Di越大即颜色分布越广,对应显著性值越小;Ui越大对应颜色独立性越高,对应显著性值越大。
最后,特征被从超像素级映射到像素级。每个像素的显著性是通过其所在超像素以及周围的超像素进行高斯线性加权,权重取决于和颜色,位置的距离。最终的归一化也很重要,要求显著图至少包含10%的显著像素,这种归一化方式也会提升算法最终的评价指标。
3) 论文评价:考虑到颜色自身独立性与颜色分布对显著度的贡献结合,算法均在时域进行,并采用高斯滤波加速,得到很不错的效果。实际测试结果saliency map较均匀,但公布的代码缺少一些实验细节,没有论文的公布结果好。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架