


mysql整体架构和语句的执行流程
mysql服务端整体架构
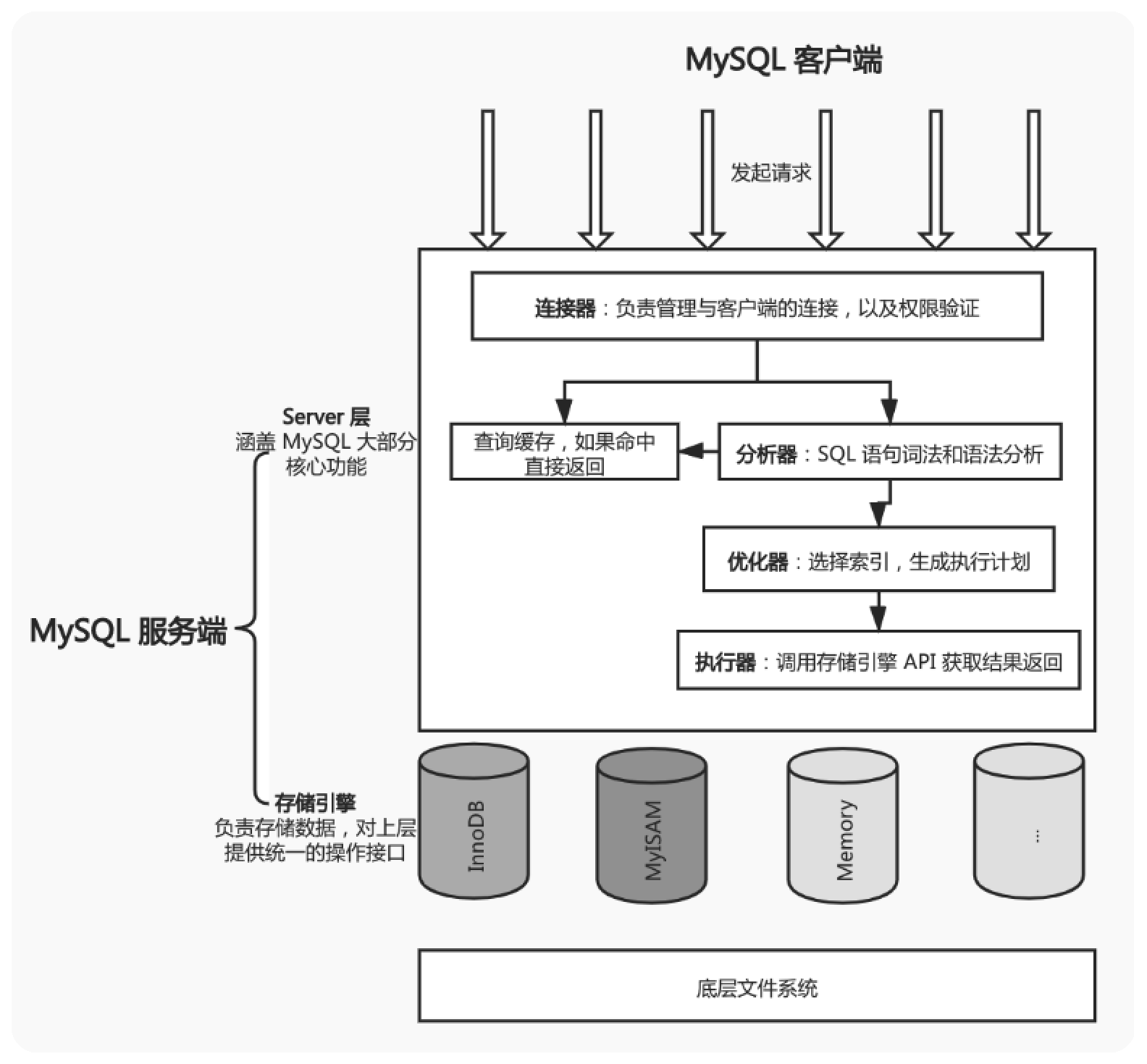
主要分为两部分,server层和存储引擎
- server层包括
连接器、查询缓存、分析器、优化器、执行器等,涵盖mysql的大多数核心服务过功能,以及所有的内置函数,所有跨存储引擎的功能都在这一层实现,比如存储过程,触发器,视图等 - 存储引擎层负责数据等存储和读取,其架构模式是插件式的,支持
InnoDB、MyISAM等多个引擎。从mysql5.5.5版本开始InnoDB成为了默认引擎。
MySql查询流程
由mysql客户端发起请求,连接器负责与客户端连接验证权限,连接成功之后开始查询缓存(当缓存开启时),如果命中则直接返回数据,如果没有命中则交由分析器进行sql词法和语法分析,然后交给优化器进行选择索引生成执行计划,最后交给执行器去调用存储引擎的API获取结果并返回
查询缓存
当 MySQL 服务端拿到一条 SQL 查询语句后,首先会查询缓存,看之前是不是执行过这条语句。如果执行过,会缓存在内存中,这个时候直接返回之前缓存的查询结果给客户端即可;如果在缓存中没有找到对应的记录,就会继续后面的操作,并且在最终执行完成后,将查询结果保存到查询缓存。
注:MySQL 8.0 版本开始将不再支持查询缓存功能。
可以通过show variables like '%query_cache%';语句查看系统查询缓存的设置
query_cache_type 为 OFF 表示默认关闭。你可以在配置文件中配置该值来决定是否启用查询缓存。
分析器
如果查询缓存没有启用或者没有命中,就开始真正执行 SQL 查询语句了。
MySQL 会通过分析器对 SQL 语句做词法分析,以确定到底要做什么,比如 select 表示查询语句,update 表示更新语句等,表名是什么,查询的字段有哪些,查询的条件是什么。
优化器
如果 SQL 语句词法和语法分析都没有问题,接下来,会经由优化器生成执行计划,这里面主要的工作是数据表包含索引的时候,判定是否使用索引,以及使用哪些索引效率最高(扫描行数最少),我们可以在执行一个 SQL 查询语句之前通过 explain 语句查看它的执行计划:
执行器
根据执行计划执行sql查询语句时,会先验证权限,有相应权限才会继续执行,否则会报权限错误
具体的查询操作是通过存储引擎提供的API接口完成的。执行器调用这些接口可以完成诸如读取下一行记录、插入记录、更新记录之类的日常数据库操作,执行 SQL 查询返回所有满足条件的结果集也是如此。
SQL更新语句执行流程与日志写入
和sql查询语句一样,MySql客户端提交SQL更新语句前,先要通过连接器建立连接,连接器验证权限等相关操作,然后交给分析器进行词法和语法分析后由执行器负责具体的执行。(修改、删除语句也是一样)
当一张数据表有更新的时候,对应的查询缓存数据就会被清空。
与查询流程不一样的是,更新还涉及到日志的写入,redo log(重做日志)和binlog(归档日志)
日志写入
MySql的设计者引入了WAL技术(Write-Ahead Logging),即先写日志,在写磁盘。
比如InnoDB引擎,当有记录需要更新的时候,InnoDB就会先把记录写到redolog里边,并更新内存,这时候更新操作就算是完成,等InnoDB空闲的时候,在将这个操作更新到磁盘里边。这样做就是因为如果每次更新操作都要写到磁盘的话,整个IO成本会非常高。
redo log
redo Log 是InnoDB引擎提供的日志系统,bindlog可以一直追加写入,负责数据库全量数据的备份和恢复,数据库集群的主从同步也是基于binlog实现的。
binlog
binlog是属于MySql Server层面的,所有存储引擎都可以共用它
在 InnoDB 引擎出现之前,MySQL 默认的存储引擎是 MyISAM,那个时候为了实现数据备份和恢复,使用的是 binlog,不过 binlog 是一个归档日志,不具备数据库崩溃重启后的数据恢复功能
两个日志的写入流程
- 执行器通过 API 接口将更新数据传递给存储引擎执行更新操作;
- 存储引擎在拿到更新数据后,先将其更新到内存,同时将这个更新操作记录到 redo log,此时 redo log 处于
prepare状态,然后告知执行器执行完成了,随时可以提交事务; - 执行器生成这个操作的 binlog,并把 binlog 写入磁盘(写入时机可以配置,对于事务操作而言,都是在事务提交时才会持久化写入的,相关细节我们后面讲数据库数据一致性的时候会详细介绍);
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成
commit状态,更新完成。

在上述步骤中,将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是「两阶段提交」。
如果不使用两阶段提交,会导致两份日志恢复的数据不一致:比如先写 redo log,binlog 还没有写入,数据库崩溃重启;或者先写 binlog,redo 还没有写入数据库崩溃重启,都将造成恢复数据的不一致。
而使用两阶段提交后,就可以保证两份日志恢复的数据一致:只有 binlog 写入成功的情况下,才会提交 redo log,否则 redo log 处于 prepare 状态,事务会回滚,这样一来,就保证了数据的一致性。
本文来自博客园,作者:颖小主,转载请注明原文链接:https://www.cnblogs.com/yingxiaozhu/p/16411644.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通