Redis高可用方案详解
在生产环境下,单机部署的Redis服务一旦宕机,所有依赖Redis服务的主流服务都会受到影响, 这时就需要一种Redis高可用方案。
一般来说, 一个高可用的方案要满足以下三点要求:
- 数据备份(冗余) 数据冗余在不同的节点上,防止数据丢失
- 故障自动切换 正在服务的节点故障时,可以自动地切换到备用节点。
- 在线扩容(缩容) 即可以根据需要动态地增加、减少服务实例。
一、主从复制
类似于MYSQL的主从同步, 是将一台Redis服务器的数据(主节点)复制到其他的Redis服务器上(从节点),且数据的复制是单向的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
主从复制原理
1.slave节点初次启动时主动向master发起TCP连接,并发起同步请求(psync命令), master接收连接(可要求授权认证),并将slave的信息保存起来。
2.master节点收到同步请求,执行BGSAVE命令生成rdb文件,文件生成后发送给slave。
3.slave收到后首先清楚自己的旧数据, 然后载入收到的rdb文件, slave更新至master执行bgsave命令前的状态。
4.master将保存rdb文件期间收到的写命令发送给slave, slave更新至主节点的最新状态。
5.此后master每有写命令,就会主动发送给slave节点。
主从节点会分别维护一个复制便宜量(复制的字节数), 当出现网络中断等情况时,重连后会从偏移量处开始进行部分复制,避免了全量复制的重型操作。
主从复制配置
主从复制master节点不需要做任何配置, 只需要在slave的配置文件中加入: slaveof <masterip> <masterport>
从节点启动时就会自动向主节点发起连接,完成主从同步的一系列过程。
优点
主从复制提供了基本的数据多节点备份功能, 当主节点发生故障时,可以启用从节点继续提供服务。
缺点
无法实现故障的自动切换, 主节点故障时,需要手动将程序(客户端)的配置从主节点切换为从节点,然后重启客户端程序。
Tips: 主从复制的机制是其他高可用方式的基础, 下面介绍的哨兵方式和集群方式都依赖于主从复制机制。
二、哨兵
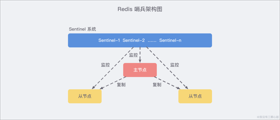
上图 展示了一个典型的哨兵架构图,它由两部分组成,哨兵节点和数据节点(主节点+从节点)
- 哨兵节点: 哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据。
- 数据节点: 主节点和从节点都是数据节点。
哨兵方式在主从复制的基础上, 实现了故障自动切换的功能:
- 监控(Monitoring): 哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover): 当 主节点 不能正常工作时,哨兵会开始 自动故障转移操作,它会将失效主节点的其中一个 从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider): 客户端在初始化时,通过连接哨兵来获得当前 Redis 服务的主节点地址。
- 通知(Notification): 哨兵可以将故障转移的结果发送给客户端。
快速开始
以下我们以一主二从三哨兵的架构来搭建一个哨兵系统
找到 redis.conf 文件复制三份分别命名为 redis-master.conf redis-slave1.conf
redis-slave2.conf 分别作为一个主节点和两个从节点的配置
配置如下:
#redis-master.conf master配置
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
#redis-slave1.conf slave1配置
port 6380
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
slaveof 127.0.0.1 6379
#redis-slave2.conf slave2配置
port 6381
daemonize yes
logfile "6381.log"
dbfilename "dump-6381.rdb"
slaveof 127.0.0.1 6379
然后启动三个redis实例:
redis-server redis-master.conf
redis-server redis-slave1.conf
redis-server redis-slave2.conf
节点启动后,我们执行 redis-cli 默认连接到我们端口为 6379 的主节点执行 info Replication 检查一下主从状态是否正常

按照上面同样的方法,我们给哨兵节点也创建三个配置文件。(哨兵节点本质上是特殊的 Redis 节点,所以配置几乎没什么差别,只是在端口上做区分就好)
# redis-sentinel-1.conf
port 26379
daemonize yes
logfile "26379.log"
sentinel monitor mymaster 127.0.0.1 6379 2
# redis-sentinel-2.conf
port 26380
daemonize yes
logfile "26380.log"
sentinel monitor mymaster 127.0.0.1 6379 2
# redis-sentinel-3.conf
port 26381
daemonize yes
logfile "26381.log"
sentinel monitor mymaster 127.0.0.1 6379 2
其中,sentinel monitor mymaster 127.0.0.1 6379 2 配置的含义是:该哨兵节点监控 127.0.0.1:6379 这个主节点,该主节点的名称是 mymaster,最后的 2 的含义与主节点的故障判定有关:至少需要 2 个哨兵节点同意,才能判定主节点故障并进行故障转移。
执行下方命令将哨兵节点启动起来:
redis-server redis-sentinel-1.conf --sentinel
redis-server redis-sentinel-2.conf --sentinel
redis-server redis-sentinel-3.conf --sentinel
使用 redis-cil 工具连接哨兵节点,并执行 info Sentinel 命令来查看是否已经在监视主节点了
# 连接端口为 26379 的 Redis 节点
➜ ~ redis-cli -p 26379
127.0.0.1:26379> info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3
三、集群方式
哨兵方式虽然实现了故障自动切换, 但是实际为客户端提供读写服务的Redis仍然只有主节点一个,所以受限于单机的内存容量。
- 集群方式采用数据分片的方式将数据存储在多个节点上,突破了单机的存储限制。
- 集群中的每个节点都可以对客户端提供读写服务, 集群相对于单机拥有更高的并发能力。
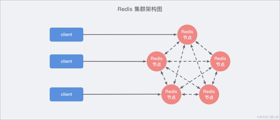
上图 展示了 Redis Cluster 典型的架构图,集群中的每一个 Redis 节点都 互相两两相连,客户端任意 直连 到集群中的 任意一台,就可以对其他 Redis 节点进行 读写 的操作。
数据分片
Redis 集群使用数据分片来实现, 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。集群中的每个节点负责处理一部分哈希槽。
搭建Redis集群
要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点。为了方便演示,这6个redis部署在同一台机器, 采用不同的端口号(7000 ~ 7005)。
准备配置文件
6个Redis节点的配置文件分别命名为node_7000.conf, node_7001.conf , ......, node_7005.conf,
除了端口号不同外,其余配置相同, 配置如下:
# 后台执行
daemonize yes
# 端口号
port 7000
# 为每一个集群节点指定一个 pid_file
pidfile ~/Desktop/redis-cluster/redis_7000.pid
# 启动集群模式
cluster-enabled yes
# 每一个集群节点都有一个配置文件,这个文件是不能手动编辑的。确保每一个集群节点的配置文件不通
cluster-config-file nodes-7000.conf
# 集群节点的超时时间,单位:ms,超时后集群会认为该节点失败
cluster-node-timeout 5000
# 最后将 appendonly 改成 yes(AOF 持久化)
appendonly yes
启动6个Redis实例
redis-server redis_7000.conf
redis-server redis_7001.conf
redis-server redis_7002.conf
redis-server redis_7003.conf
redis-server redis_7004.conf
redis-server redis_7005.conf
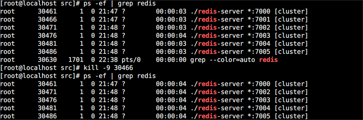
使用ps -ef | grep redis查看

可以看到6个Redis实例都以cluster的方式启动了
实例启动后还处于各自独立的状态,还没有形成集群,需要手动执行命令建立集群。
建立集群
执行命令:
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
--replicas 1 的意思是:我们希望为集群中的每个主节点创建一个从节点。
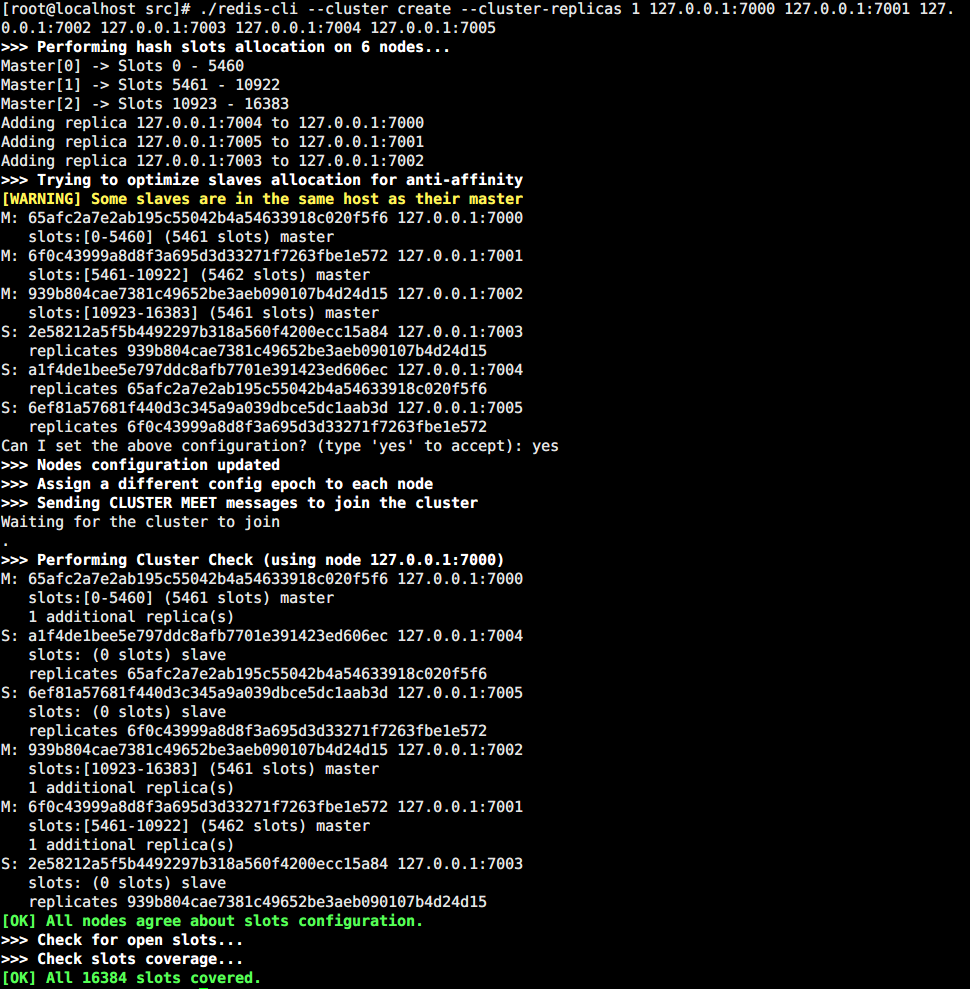
看到 [OK] 的信息之后,就表示集群已经搭建成功了,可以看到,这里我们正确地创建了三主三从的集群。
验证集群
使用 redic-cli 任意连接一个节点:
redis-cli -c -h 127.0.0.1 -p 7000
127.0.0.1:7000>
-c表示集群模式;-h指定 ip 地址;-p指定端口。
127.0.0.1:7000> SET name xiaoming
-> Redirected to slot [5798] located at 127.0.0.1:7001
OK
127.0.0.1:7001>
可以看到这里 Redis 自动帮我们进行了 Redirected 操作跳转到了 7001 这个实例上
我们可以在任意节点使用cluster nodes 查看节点列表

故障模拟
从图中我们可以看到7005实例是7001实例的从节点, 我们现在停掉7001的实例(kill -9)
然后我们连接现存的任一节点,读取name值

发现仍然可以从7005的实例上读取到值,集群仍然是正常运转的。
当我们把7005实例也停掉后,集群就会变得不可用


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步