简单的方法爬取b站dnf视频封面步骤解释
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
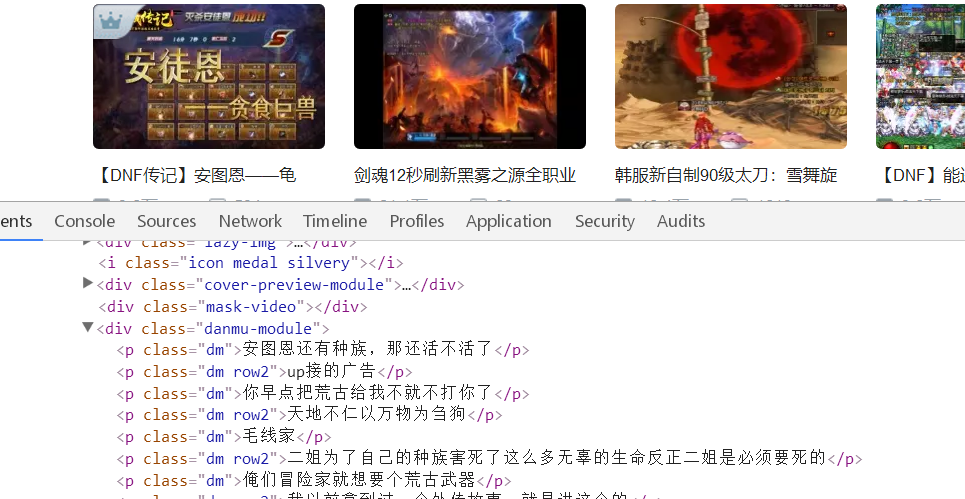
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
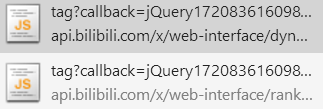

进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?

让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...

查找开头第一个(,然后截取至最后一个),里面不就是了吗?
def instr(keystr): st=keystr.find('(')+1 strhtml=keystr[st:len(keystr)-1] return strhtml

def picsave(strJson,number): global cnt strdic=strJson['data']['archives'] num=len(strdic) for i in range(0,num,1): cnt=cnt+1 strdic=strJson['data']['archives'][i] print(strdic['pic']) urllib.request.urlretrieve(strdic['pic'],'E:\图片\dnf\%s.jpg'%(cnt))
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。
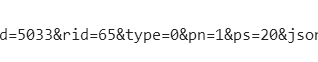
![]()
于是...
def urlget(num): for i in range(1,num,1): url='https://api.bilibili.com/x/tag/ranking/archives?callback=jQuery172014070206081723846_1514982701564&tag_id=5033&rid=65&type=0&pn='+str(i)+'&ps=20&jsonp=jsonp&_=1514982702144' response=urllib.request.urlopen(url) html=response.read().decode('utf-8') html=instr(html) strJson=eval(html) picsave(strJson,i)
然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码
分类:
Python



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~