防止消息丢失、重复消费,顺序消费和消息积压
我这三年被kafka坑惨了 - 苏三说技术 - 博客园 (cnblogs.com)
消息丢失
丢失场景及解决方法
1. 设置acks=1或=0。
原因:(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失。
解决:设置acks=all或=-1,设置适当足够的副本。
即需要相应的所有处于ISR的分区都确认收到该消息后,才算发送成功。
2. Producer端可能会丢失消息。目前Kafka Producer是异步发送消息的,也就是说如果你调用的是producer.send(msg)这个API,那么它通常会立即返回,但此时你不保证消息发送已成功完成。可能会出现:网络抖动,导致消息压根就没有发送到Broker端;或者消息本身不合规导致Broker拒绝接收(比如消息太大了,超过了Broker的限制)。
实际上,使用producer.send(msg, callback)接口就能避免这个问题,根据回调,一旦出现消息提交失败的情况,就可以有针对性地进行处理。如果是因为那些瞬时错误,Producer重试就可以了;如果是消息不合规造成的,那么调整消息格式后再次发送。总之,处理发送失败的责任在Producer端而非Broker端。当然,如果此时broker宕机,那就另当别论,需要及时处理broker异常问题。
3. kafka通过先消费消息,后更新offset,来保证消息不丢失。
当我们consumer端开启多线程异步去消费时,情况又会变得复杂一些。此时consumer自动地向前更新offset,假如其中某个线程运行失败了,它负责的消息没有被成功处理,但位移已经被更新了,因此这条消息对于consumer而言实际上是丢失了。这里的关键就在自动提交offset,如何真正地确认消息是否真的被消费,再进行更新offset。
这个问题的解决起来也简单:如果是多线程异步处理消费消息,consumer不要开启自动提交offset,consumer端程序自己来处理offset的提交更新。提醒你一下,单个consumer程序使用多线程来消费消息说起来容易,写成代码还是有点麻烦的,因为你很难正确地处理offset的更新,也就是说避免无消费消息丢失很简单,但极易出现消息被消费了多次的情况。
4. 老版本主从副本同步过程中也存在消息丢失问题。后面已经通过leader epoch机制解决。具体见Kafka副本主从同步机制 - 沉浮axl - 博客园 (cnblogs.com)。
5. Kafka 还有一种特别隐秘的消息丢失场景:增加主题分区。当增加主题分区后,在某段“不凑巧”的时间间隔后,Producer 先于 Consumer 感知到新增加的分区,而 Consumer 设置的是“从最新位移处”开始读取消息,因此在 Consumer 感知到新分区前,Producer 发送的这些消息就全部“丢失”了,或者说 Consumer 无法读取到这些消息。
解决方法: 设置auto.offset.reset=earliest,第⼀次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1)。
6. 设置了unclean.leader.election.enable = true,允许脏选举,由于ISR是动态调整的,所以会存在ISR列表为空的情况,通常来说,非同步副本落后 Leader 太多,因此,如果选择这些副本作为新 Leader,就可能出现数据的丢失。毕竟,这些副本中保存的消息远远落后于老 Leader 中的消息。
解决:设置unclean.leader.election.enable = false,开启 Unclean 领导者选举可能会造成数据丢失,但好处是,它使得分区 Leader 副本一直存在,不至于停止对外提供服务,因此提升了高可用性。反之,禁止 Unclean Leader 选举的好处在于维护了数据的一致性,避免了消息丢失,但牺牲了高可用性。
7. 如果设置了自动提交,auto.commit.interval.ms参数是自动提交位移时间,很多文档讲的不清楚,把这个自动提交位移翻译成每隔几秒自动提交一次,这个完全是错误的,因为此时是在调用poll的时候再进行位移提交,因此一批消息是否提交是要在下一次poll判断,所以自动提交在单线程处理消息的场景下并不会带来消息丢失的问题。而在多线程异步处理消息的场景下,是有可能出现消息丢失的。
无消息丢失配置
需要注意的是,Kafka 只对“已提交”的消息(committed message)做有限度的持久化保证。
- 不要使用 producer.send(msg),而要使用 producer.send(msg, callback)。记住,一定要使用带有回调通知的 send 方法。
- 设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。
- 设置 retries 为一个较大的值。这里的 retries 同样是 Producer 的参数,对应前面提到的 Producer 自动重试。当出现网络的瞬时抖动时,消息发送可能会失败,此时配置了 retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失。
- 设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
- 设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
- 设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
- 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
- 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并采用手动提交位移的方式。就像前面说的,这对于单 Consumer 多线程处理的场景而言是至关重要的。
总结里的的第二条ack=all和第六条的说明是不是有冲突?
其实不冲突。如果ISR中只有1个副本了,acks=all也就相当于acks=1了,引入min.insync.replicas的目的就是为了做一个下限的限制:不能只满足于ISR全部写入,还要保证ISR中的写入个数不少于min.insync.replicas。
Kafka 还有一种特别隐秘的消息丢失场景:增加主题分区。当增加主题分区后,在某段“不凑巧”的时间间隔后,Producer 先于 Consumer 感知到新增加的分区,而 Consumer 设置的是“从最新位移处”开始读取消息,因此在 Consumer 感知到新分区前,Producer 发送的这些消息就全部“丢失”了,或者说 Consumer 无法读取到这些消息。严格来说这是 Kafka 设计上的一个小缺陷,你有什么解决的办法吗?
设置auto.offset.reset=earliest,第⼀次从头开始消费。之后开始消费新消息(最后消费的位置的偏移量+1)。
消息重复
1. 消息消费端在消费过程中挂掉没有及时提交offset到broke,另一个消费端启动拿之前记录的offset开始消费,由于offset的滞后性可能会导致新启动的客户端有少量重复消费。
解决方法:每次消费完或者程序退出时手动提交。这可能也没法保证一条重复。
下游做幂等
一般是让下游做幂等或者尽量每消费一条消息都记录offset,对于少数严格的场景可能需要把offset或唯一ID(例如订单ID)和下游状态更新放在同一个数据库里面做事务来保证精确的一次更新或者在下游数据表里面同时记录消费offset,然后更新下游数据的时候用消费位移做乐观锁拒绝旧位移的数据更新。
2. 如果⽣产者发送完消息后,因为⽹络抖动,没有收到ack,但实际 上broker已经收到了。 此时⽣产者会进⾏重试,于是broker就会收到多条相同的消息,⽽造成消费者的重复消费。
一般是让下游做幂等或者尽量每消费一条消息都记录offset,对于少数严格的场景可能需要把offset或唯一ID(例如订单ID)和下游状态更新放在同一个数据库里面做事务来保证精确的一次更新或者在下游数据表里面同时记录消费offset,然后更新下游数据的时候用消费位移做乐观锁拒绝旧位移的数据更新。
解决重复消费还有一个方法就是启用exactly once保障,通过开启幂等和事务进行实现。Kafka幂等生产者和事务生产者 - 沉浮axl - 博客园 (cnblogs.com)
顺序消费
Producer 端:
Kafka 的发送端发送消息,如果是默认参数什么都不设置,则消息如果在网络没有抖动的时候,可以一批批的按消息发送的顺序被发送到 Kafka 服务器端。但是,一旦网络波动了,则消息就可能出现失序。
所以,要严格保证 Kafka 发消息有序,首先要考虑同步发送消息。
同步发送消息有两种方式:
第一种方式:设置消息响应参数 acks > 0,最好是 -1。
然后,设置
max.in.flight.requests.per.connection = 1
这样设置完后,在 Kafka 的发送端,将会一条消息发出后,响应必须满足 acks 设置的参数后,才会发送下一条消息。所以,虽然在使用时,还是异步发送的方式,其实底层已经是一条接一条的发送了。
第二种方式:当调用 KafkaProducer 的 send 方法后,调用 send 方法返回的 Future 对象的 get 方式阻塞等待结果。等结果返回后,再继续调用 KafkaProducer 的 send 方法发送下一条消息。
同步发送消息之外,还要考虑消息重发问题。
Kafka 发送端可以在发送出现问题时,判断问题是否可以自动恢复,如果是可以自动恢复的问题,可以通过设置 retries > 0,让 Kafka 自动重试。
根据 Kafka 版本的不同,Kafka 1.0 之后的版本,发送端引入了幂等特性。引入幂等特性,我们可以这么设置
enable.idempotence = true
幂等特性这个特性可以给消息添加序列号,每次发送,会把序列号递增 1。
开启了 Kafka 发送端的幂等特性后,我们就可以设置
max.in.flight.requests.per.connection = 5
这样,当 Kafka 发消息的时候,由于消息有了序列号,当发送消息出现错误的时候,在 Kafka 底层会通过获取服务器端的最近几条日志的序列号和发送端需要重新发送的消息序列号做对比,如果是连续的,那么就可以继续发送消息,保证消息顺序。
只能保证单分区顺序性。
Broker 端:
Kafka 的 Topic 只是一个逻辑概念。而组成 Topic 的分区才是真正存消息的地方。
Kafka 只保证同个分区内的消息是有序的。所以,如果要保证业务全局严格有序,就要设置 Topic 为单分区的形式。
不过,往往我们的业务是不需要考虑全局有序的,我们只需要保证业务中不同类别的消息有序即可。对这些业务中不同类别的消息,可以设置成不同的 Key,然后根据 Key 取模。这样,由于同类别消息有同样的 Key,就会被分配到同样的分区中,保证有序。
但是,这里有个问题,就是当我们对分区的数量进行改变的时候,会把以前可能分到同样的分区的消息,分到别的分区上。这就不能保证消息顺序了。
面对这种情况,就需要在动态变更分区的时候,考虑对业务的影响。有可能需要根据业务和当前分区需求,重新划分消息类别。
另外,如果一个 Topic 存在多分区的情况,并且 min.insync.replicas 指定的副本个数挂掉了,那么,就会出现这种情况:发送消息写入不了对应分区,但是消费依然可以消费消息。
此时,往往我们会保证可用性,会考虑切换消息的分区,一旦这样做,消息顺序就可能出现不一致的情况。
所以,一定要保证 min.insync.replicas 参数配置的合适,去最大可能保证消息写入的顺序性。
Consumer 端:
在消费者端,根据 Kafka 的模型,一个 Topic 下的每个分区只能从属于监听这个 Topic 的消费者组中的某一个消费者。
假设 Topic 的分区数量为 P,而消费者组中的消费者数为 C。那么,如果 P \< C , 就会出现消费者空闲的情况;如果 P > C,则会出现一个消费者被分配多个分区的情况,如下图。
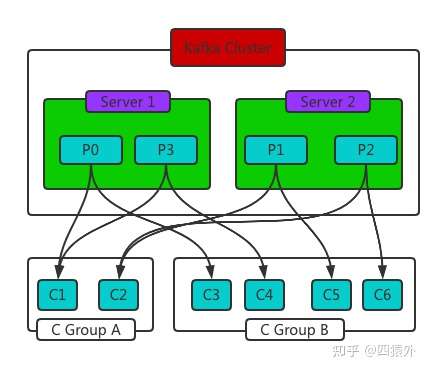
所以,当我们消费者端使用 poll 方法的时候,一定要注意:poll 方法获取到的记录,很可能是多个分区甚至多个 Topic 的。
还需要通过 ConsumerRecords 的 records(TopicPartition partition) 进行进一步的排序和筛选,才能真正的保证发送和消费的顺序一致性使用。
另外一个要注意的地方就是消费者的 Rebalance。Rebalance 就是让一个消费者组下所有的消费者实例,就如何消费订阅主题的所有分区达成共识的过程。
这个 Rebalance 机制是 Kafka 最臭名照顾的地方:
- 它每次 Rebalance,都会让全部消费者组的消费暂停。
- 再就是 Rebalance 的 bug 非常多,比如就是 Rebalance 后,要么某个消费者突然崩了,要么是消费者组中某些消费者停了。
- 由于 Rebalance 相当于让消费者组重新分配分区,这就可能造成消费者在 Rebalance 前、后所对应的分区不一致。分区不一致,那自然消费顺序就不可能一致了。
所以,我们都会尽量不让 Rebalance 发生。有三种情况会触发 Kafka 消费者的 Rebalance 发生:
- 消费者组成员发生变化:这个往往是指,我们认为增减了组内的消费者个数,又或者是某些消费者崩溃了,导致被踢出组。
- 订阅主题数发生变化:Kafka 的消费者组是能用正则去模糊匹配 Topic 的。这就造成一个问题,当我们在 Kafka 中添加主题后,可能会造成消费者组监听的 Topic 数发生变化。
- 订阅主题的分区数发生变化:有些时候,可能我们想动态的线上变更主题的分区数。
所以,当这三种情况触发 Rebalance 后,就会出现问题,消费顺序不一致只是其中很轻微的一种负面影响。
消息积压
通常情况下,企业中会采取轮询或者随机的方式,通过Kafka的producer向Kafka集群生产数据,来尽可能保证Kafk分区之间的数据是均匀分布的。
在分区数据均匀分布的前提下,如果我们针对要处理的topic数据量等因素,设计出合理的Kafka分区数量。对于一些实时任务,比如Spark Streaming/Structured-Streaming、Flink和Kafka集成的应用,消费端不存在长时间"挂掉"的情况即数据一直在持续被消费,那么一般不会产生Kafka数据积压的情况。
但是这些都是有前提的,当一些意外或者不合理的分区数设置情况的发生,积压问题就不可避免。
Kafka消息积压的典型场景:
1.实时/消费任务挂掉
比如,我们写的实时应用因为某种原因挂掉了,并且这个任务没有被监控程序监控发现通知相关负责人,负责人又没有写自动拉起任务的脚本进行重启。
那么在我们重新启动这个实时应用进行消费之前,这段时间的消息就会被滞后处理,如果数据量很大,可就不是简单重启应用直接消费就能解决的。
2.Kafka分区数设置的不合理(太少)和消费者"消费能力"不足
Kafka单分区生产消息的速度qps通常很高,如果消费者因为某些原因(比如受业务逻辑复杂度影响,消费时间会有所不同),就会出现消费滞后的情况。
此外,Kafka分区数是Kafka并行度调优的最小单元,如果Kafka分区数设置的太少,会影响Kafka consumer消费的吞吐量。
3.Kafka消息的key不均匀,导致分区间数据不均衡
在使用Kafka producer消息时,可以为消息指定key,但是要求key要均匀,否则会出现Kafka分区间数据不均衡。
那么,针对上述的情况,有什么好的办法处理数据积压呢?
一般情况下,针对性的解决办法有以下几种:
1.实时/消费任务挂掉导致的消费滞后
a.任务重新启动后直接消费最新的消息,对于"滞后"的历史数据采用离线程序进行"补漏"。
此外,建议将任务纳入监控体系,当任务出现问题时,及时通知相关负责人处理。当然任务重启脚本也是要有的,还要求实时框架异常处理能力要强,避免数据不规范导致的不能重新拉起任务。
b.任务启动从上次提交offset处开始消费处理
如果积压的数据量很大,需要增加任务的处理能力,比如增加资源,让任务能尽可能的快速消费处理,并赶上消费最新的消息
2.Kafka分区少了
如果数据量很大,合理的增加Kafka分区数是关键。如果利用的是Spark流和Kafka direct approach方式,也可以对KafkaRDD进行repartition重分区,增加并行度处理。
3.由于Kafka消息key设置的不合理,导致分区数据不均衡
可以在Kafka producer处,给key加随机后缀,使其均衡。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理