

mysql
查询前几条记录 limit
select * from issu_info limit 7,6;
Limit 7,6
从第8条开始取,取6条
查看表头信息desc
启动windows-mysql:先在bin目录双击mysqld。service.msc中此时会存在mysql服务。如果想在命令行操作mysql,先进入对应的bin路径,再打开客户端mysql -hlocalhost -P3306 -uroot -p
navicat查看和修改字段信息
可添加和删除字段,但是要点击保存以后才会生效,而且navicat显示的表缓存很久,也不会自动刷新,怎么点刷新都没用的,表都是很久以前的表了。
distinct 查询不重复的记录(在导出之前你可能不知道关于这一条有没有重复记录)

select distinct 字段 from 表名;
eg: select distinct name from students;//查询名字不相同的学生;
select distinct name,age from students;//查询名字和年龄同时不同的学生
1.distinct必须放在最开头
2.distinct只能使用需要去重的字段进行操作。 ----也就是说我sidtinct了name,age两个字段,我后面想根据id进行排序,是不可以的,因为只能name,age两个字段进行操作.
3.distinct去重多个字段时,含义是:几个字段 同时重复 时才会被 过滤。
where条件查询(常用)
select 字段 from 表名 where 条件; eg:select * from student where sex='男' and age>20; //查询性别是男,并且年龄大于20岁的人。
where后面的条件可以用>、<、>=、<=、!=等多种比较运算符,多个条件之间可以用or、and等逻辑运算符
排序orderby desc、asc
排序
select * from 表名 [where 条件] [ order by field1 [desc/asc],field2 [desc/asc]... ];
eg:select *from student order by age desc;//查询学生表并按年龄降序排列。
1.desc 降序排列,asc 升序排列
2.order by 后面可以跟多个不同的排序字段,每个排序字段都可以有不同的排序顺序。
3.如果排序字段的值一样,则相同的字段按照第二个排序字段进行排序。
4.如果只有一个排序字段,则字段相同的记录将会无序排列。
限制limit select ... [limit 起始偏移量,行数];
eg:select * from student order by mark desc limit 5;//取出成绩前五名的学生(省略了起始偏移量,此时默认为0)
1.默认情况下,起始偏移量为0,只写记录行数就可以。
5.聚合max/min/count groupby
select 字段 fun_name from 表名 [where 条件] [group by field1,field2...] [with rollup] [having 条件];
eg:
1.fun_name 表示要做的聚合操作,也就是说聚合函数,常用的有 : sum(求和)、count(*)(记录数)、max(最大值)、min(最小值)。
2.group by关键字 表示要进行分类聚合的字段。比如要按照部门分类统计员工数量,部门就应该写在group by 后面。group by 是要和count一起用的
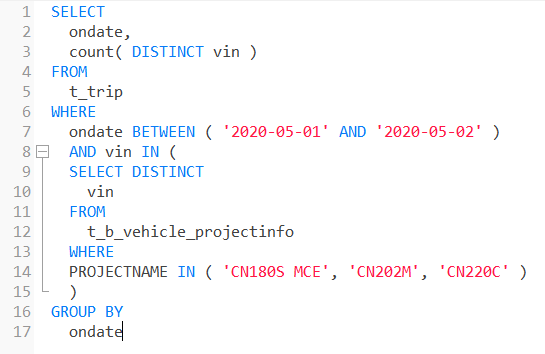
例:
SELECT ondate,count( DISTINCT vin ) FROM
3.with rollup 是可选语法,表明是否对分类聚合后的结果进行再汇总
4.having 关键字表示对分类后的结果再进行条件过滤。
公司员工表A如下 (编号,姓,名,薪水) :
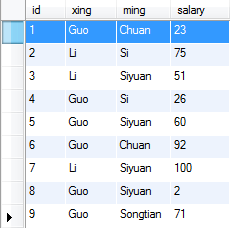
统计总人数 select count(1) from A;
1. count(1) and count(*)
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了!
从执行计划来看,count(1)和count(*)的效果是一样的。 但是在表做过分析之后,count(1)会比count(*)的用时少些(1w以内数据量),不过差不了多少。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(1),用count(*),sql会帮你完成优化的 因此:count(1)和count(*)基本没有差别!
2. count(1) and count(字段)
两者的主要区别是
(1) count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
(2) count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
统计各个姓的人数 select xing,count(1) from A group by xing;
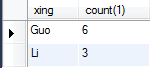
既要统计各个姓的人数,又统计总人数 select xing,count(1) from A group by xing with rollup;
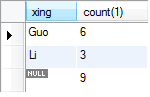
select没有写xing统计结果就没法看,但是也能统计
统计人数大4的姓 select xing,count(1) from A group by xing having count(1)>4;
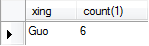
统计薪水总额,最低薪资,最高薪资 select count(1),min(salary),max(salary) from A;

min和max不写by
6.表连接
大表的表连接会很慢,要尽量的优化,技巧如链接https://blog.csdn.net/insis_mo/article/details/82897665 基本原理是尽量在子查询中缩小表,不要先合成一个巨大的表再查询。另外,可给表字段添加索引。
表连接分为内连接和外连接。
他们之间最主要的区别:内连接仅选出两张表中互相匹配的记录,外连接会选出其他不匹配的记录。
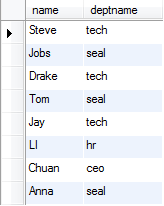
以下是员工表staff和职位表deptno:
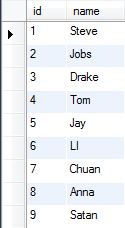
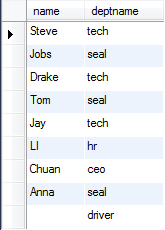
内连接 select staff.name,deptname from staff,deptno where staff.name=deptno.name;
inner join和逗号是等同的
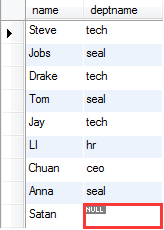
外连接 分为左连接和右连接,左连接是以left join左边的条件为准,如果没有其他列显示null,右连接则相反
左连接:包含所有左边表中的记录,甚至是右边表中没有和他匹配的记录。
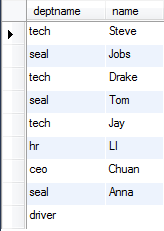
右连接:包含所有右边表中的记录,甚至是右边表中没有和他匹配的记录。
外连接(左连接): select staff.name,deptname from staff left join deptno on staff.name=deptno.name;
外连接(右连接): select deptname,deptno.name from staff right join deptno on deptno.name=staff.name;
select as
我们都知道,在sql语句中,使用as可以对字段、表等取别名,像对一些英文的字段取中文名称,使可读性更高。
查询包含字符LIKE
在SQL结构化查询语言中,LIKE语句有着至关重要的作用。
LIKE语句的语法格式是:select * from 表名 where 字段名 like 对应值(子串),它主要是针对字符型字段的,它的作用是在一个字符型字段列中检索包含对应子串的。
A:% 包含零个或多个字符的任意字符串: 1、LIKE'Mc%' 将搜索以字母 Mc 开头的所有字符串(如 McBadden)。
2、LIKE'%inger' 将搜索以字母 inger 结尾的所有字符串(如 Ringer、Stringer)。
3、LIKE'%en%' 将搜索在任何位置包含字母 en 的所有字符串(如 Bennet、Green、McBadden)。
B:_(下划线) 任何单个字符:LIKE'_heryl' 将搜索以字母 heryl 结尾的所有六个字母的名称(如 Cheryl、Sheryl)。
C:[ ] 指定范围 ([a-f]) 或集合 ([abcdef]) 中的任何单个字符: 1,LIKE'[CK]ars[eo]n' 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)。
2、LIKE'[M-Z]inger' 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer)。
D:[^] 不属于指定范围 ([a-f]) 或集合 ([abcdef]) 的任何单个字符:LIKE'M[^c]%' 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)。
E:* 它同于DOS命令中的通配符,代表多个字符:c*c代表cc,cBc,cbc,cabdfec等多个字符。
F:?同于DOS命令中的?通配符,代表单个字符 :b?b代表brb,bFb等
G:# 大致同上,不同的是代只能代表单个数字。k#k代表k1k,k8k,k0k 。
F:[!] 排除 它只代表单个字符
下面我们来举例说明一下:
例1,查询name字段中包含有“明”字的。 注意‘’%明%“”已经包含了“”明%“”的情形
select * from table1 where name like '%明%'
例2,查询name字段中以“李”字开头。
select * from table1 where name like '李*'
例3,查询name字段中含有数字的。
select * from table1 where name like '%[0-9]%'
例4,查询name字段中含有小写字母的。
select * from table1 where name like '%[a-z]%'
例5,查询name字段中不含有数字的。
select * from table1 where name like '%[!0-9]%'
以上例子能列出什么值来显而易见。但在这里,我们着重要说明的是通配符“*”与“%”的区别。
很多朋友会问,为什么我在以上查询时有个别的表示所有字符的时候用"%"而不用“*”?先看看下面的例子能分别出现什么结果:
select * from table1 where name like '*明*'
select * from table1 where name like '%明%'
大家会看到,前一条语句列出来的是所有的记录,而后一条记录列出来的是name字段中含有“明”的记录,所以说,当我们作字符型字段包含一个子串的查询时最好采用“%”而不用“*”,用“*”的时候只在开头或者只在结尾时,而不能两端全由“*”代替任意字符的情况下。
寻找元素位置INTERVal
INTERVAL(N,N1,N2,N3,..........)
INTERVAL()函数进行比较列表(N,N1,N2,N3等等)中的N值。该函数如果N<N1返回0,如果N<N2返回1,如果N<N3返回2 等等。如果N为NULL,它将返回-1。列表值必须是N1<N2<N3的形式才能正常工作。
输出对应字符串ELT
ELT(n,str1,str2,str3,...) :如果n=1,则返回str1,如果n=2,则返回str2,依次类推。如果n小于1或大于参数个数,返回NULL。ELT()是FIELD()的功能补充函数。
mysql> SELECT ELT(3,'hello','halo','test','world'); +--------------------------------------+ | ELT(3,'hello','halo','test','world') | +--------------------------------------+ | test | +--------------------------------------+ 1 row in set
SELECT ELT(INTERVAL(dt.offmileage,0,500,1000,2000,4000,10000),'0~500','500~1000','1000~2000','2000~4000','4000~10000','10000~') as kmArea,COUNT(*) as carnetNum
from
(SELECT DISTINCT t.vin,MIN(t.km_total) AS offmileage FROM car_networking_statistic t
WHERE t.day = '2020-06-13' GROUP BY t.vin) dt
,(SELECT DISTINCT cns.vin from t_b_vehicle_projectinfo cns WHERE cns.model IN('RM-5','RC-6','RS-3')) tbv
WHERE dt.vin = tbv.vin
GROUP BY kmArea;
ELT INTERVAL 结合使用实现了if 在某区间 print 的功能
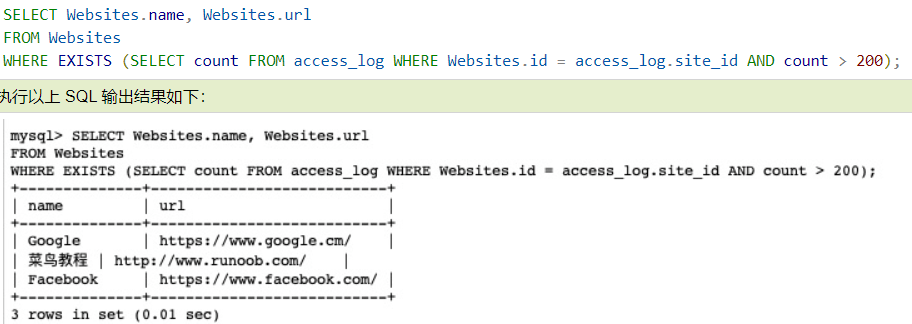
连表筛选EXIST(注意!!大表用exist效率会变慢)

含时间、日期时只取日期: WHERE DATE(t.happen_time) = '2020-06-01'
数值为空判断ifnull
IFNULL(expression1, expression2)
如果expression1为null, 在函数返回expression2,否则将返回expression1。
表串接 UNION
多个select语句之间使用union,并且他们的列明都相同的话可以把表全部串在一起
主键自增
一般创建表时都会设置一列自增的ID,自增是创表是sql写入,同时在navicat直接在自增小方框打勾也可以
包含 in
WHERE
date >= 2020-07-30
AND model IN ( 'CN180S MCE', 'CN202M', 'CN220C' )
查询时只取其中几个元素 substr
SUBSTR(gps_time,1,10)
foreach 传入参数为多个时使用
语句中需设置起始、末尾和分隔标志,字段名需要前后一致否则报错
DATEIFF查询日期间隔
SELECT DATEDIFF(day,'2008-12-29','2008-12-30') AS DiffDate
mybatis添加查询日志:在resource文件中添加
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
转义字符(oracle中经常会用到)
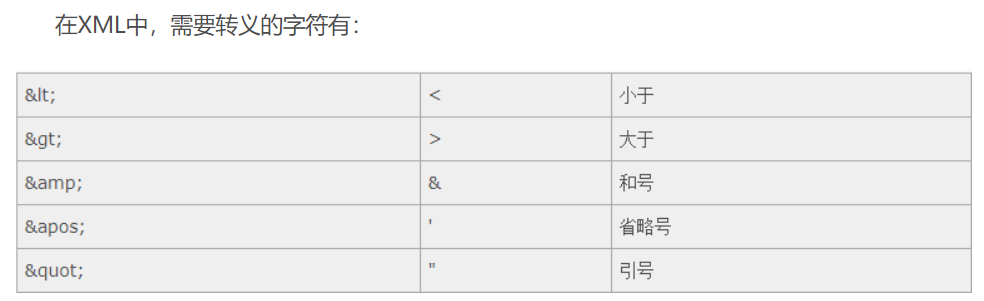
set关键字
set可以设置变量,在查询语句中可多次使用
要先执行set 再执行剩下的
set @DATE='2020-09-03'
select @DATE as day, net.behavior_id, net.tag, count(distinct net.vin)
from car_networking_statistic net
substring_index
语法:substring_index(str, delim, count)
参数:
- str:需要拆分的字符串;
- delim:分隔符,根据此字符来拆分字符串;
- count:当 count 为正数,取第 n 个分隔符之前的所有字符; 当 count 为负数,取倒数第 n 个分隔符之后的所有字符
doneselect SUBSTRING_INDEX('mooc_100018252','_',-1); // 结果: 100018252
https://www.cnblogs.com/linyufeng/p/13041500.html
合并查询结果
不合并重复数据 select * from T1 union all select * from T2
合并重复数据 select * from T1 union select * from T2
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
-
创建数据库
CREATE DATABASE 数据库名; -
删除数据库
drop database <数据库名>; -
插入数据
INSERT INTO table_name ( field1, field2,...fieldN ) 这个value可以不包含全部的字段,但是不管是一个还是多个字段都需要用括号括起来 VALUES ( value1, value2,...valueN ); -
UPDATE 更新
-
UPDATE table_name SET field1=new-value1, field2=new-value2
对数据的操作一般都不需要使用“table”二字,用的都是对表定义方面的操作
-
ALTER命令 修改字段信息
-
mysql> ALTER TABLE testalter_tbl MODIFY c CHAR(10); - alter table f alter b set DEFAULT 0 可以设置字段默认值的,这样可以避免null的问题
-
修改字段类型及名称
-
NULL 值处理(避免空指针异常)
- IS NULL:
- IS NOT NULL:
- <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
-
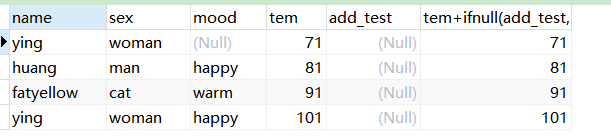
select * , tem+ifnull(add_test,0) from a;
#columnName1,columnName2 为 int 型,当 columnName2 中,有值为 null 时,columnName1+columnName2=null, ifnull(columnName2,0) 把 columnName2 中 null 值转为 0。
explain优化查询
在select前面加关键字explain并运行,可查看子查询情况和是否加了索引等。子查询不能超过1千条否则很慢
MySQL 索引
CREATE INDEX indexName ON table_name (column_name)
ALTER table tableName ADD INDEX indexName(columnName)括号前面是索引全名
以上两个句子是等价的
ALTER TABLE studentsADD UNIQUE INDEX uni_name (name);
添加唯一索引,适合并未作为主键,但是又确实是唯一值的。如果本来就有重复值的添加这一条会报错。null不算是重复。
删除索引 alter table f drop index a 注意后面不再需要跟着列名
ALTER table f add INDEX x(b)
show index from f
MySQL 元数据
你可能想知道MySQL以下三种信息:
- 查询结果信息: SELECT, UPDATE 或 DELETE语句影响的记录数。
- 数据库和数据表的信息: 包含了数据库及数据表的结构信息。
- MySQL服务器信息: 包含了数据库服务器的当前状态,版本号等。
floor 向下取整
求 小于 5,5.66,-4,-4.66 的最大整数
ysql> SELECT FLOOR(5),FLOOR(5.66),FLOOR(-4),FLOOR(-4.66);
limit a,b
跳过前面a行,取总行数b行
<=>严格比较两个NULL值是否相等
% 或 MOD 取余
CHAR_LENGTH(s)返回字符串 s 的字符数
CONCAT(s1,s2...sn) 字符串 s1,s2 等多个字符串合并为一个字符串
CONCAT_WS(x, s1,s2...sn)同 CONCAT(s1,s2,...) 函数,但是每个字符串之间要加上 x,x 可以是分隔符
FORMAT(x,n)函数可以将数字 x 进行格式化 "#,###.##", 将 x 保留到小数点后 n 位,最后一位四舍五入。
INSERT(s1,x,len,s2)字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串
RIGHT(s,n)返回字符串 s 的后 n 个字符
UCASE(s)将字符串转换为大写UPPER(s)将字符串转换为大写
n DIV m整除,n 为被除数,m 为除数
FLOOR(x)返回小于或等于 x 的最大整数
RAND()返回 0 到 1 的随机数
ROUND(x)返回离 x 最近的整数
DATEDIFF(d1,d2)计算日期 d1->d2 之间相隔的天数
IF(expr,v1,v2)如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。
IFNULL(v1,v2)如果 v1 的值不为 NULL,则返回 v1,否则返回 v2
ISNULL(expression)判断表达式是否为 NULL
having代替where
having和where的区别在于它用在group by 后面对求和后的结果进行排序
https://www.w3school.com.cn/sql/sql_having.asp
分页查询offset
现在,我们把结果集分页,每页3条记录。要获取第1页的记录,可以使用LIMIT 3 OFFSET 0:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 0;
https://www.liaoxuefeng.com/wiki/1177760294764384/1217864791925600
事务: 注意,在事务中select都能直接看到变更,只是commit前都可以回滚,在旧版本sql中select是看不到commit以前的变更的
start transaction ;
一大堆执行;
是否rollback;
commi 最终确认
savepoint 名称 设置“断点”(称为回滚点)
rollback to 名称 回滚到断点处
set global transaction isolation level REPEATABLE read 设置级别
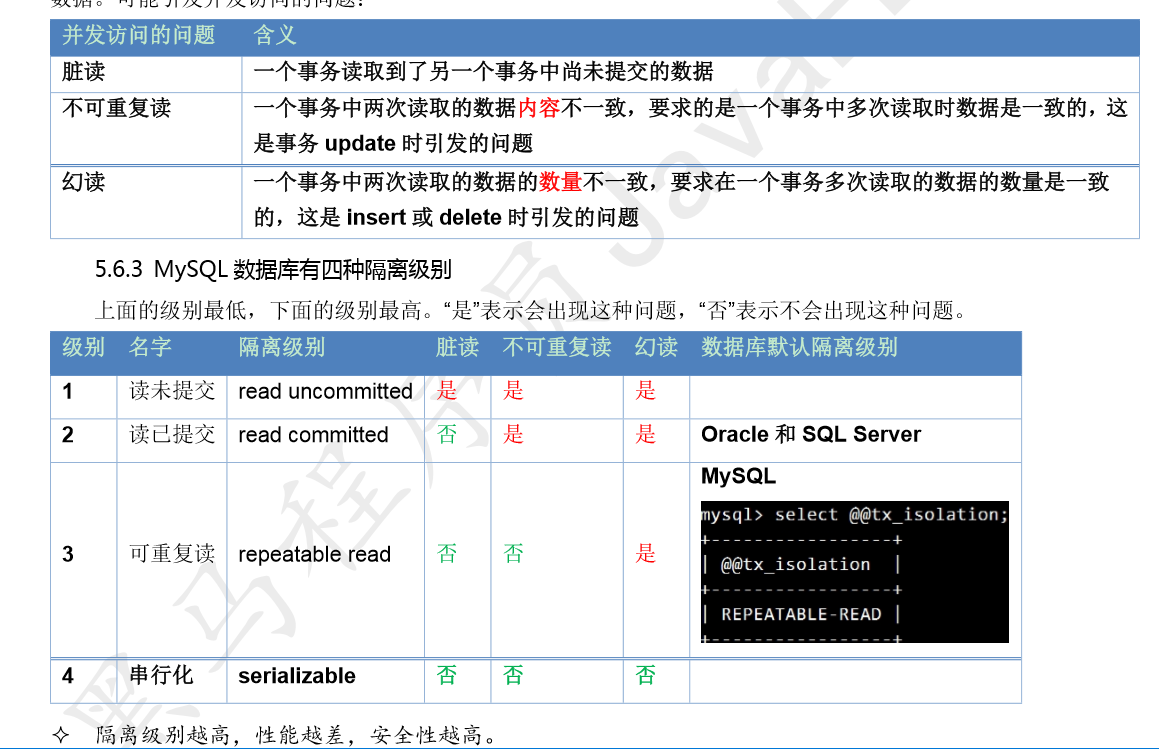
避免“脏读”:没有commit的数据其他用户查询时看不到
避免“重复读”:就算是一斤commit的数据,其他用户在同一次查询中,不会查询到两组不一样的值
“幻读”和“重复读”概念类似,只是一个是update的问题一个是insert的问题
注意:这是针对不同用户的,本用户本窗口能不能读到只与版本设定有关,与事务级别无关
DATE_FORMAT(ontime,'%H')针对date类型的操作
取小时数,H为24小时制,h为12小时制
sql优化:以下两句查询效率相差20倍,需要研究一下
explain
SELECT count(1) FROM
(SELECT vin,sum(drivermileage)as daymile FROM t_trip WHERE ondate='2020-09-21' GROUP BY vin)as a
WHERE a.daymile > 50
explain
SELECT count(1) FROM
(SELECT vin,sum(drivermileage)as daymile FROM t_trip WHERE ondate BETWEEN '2020-09-21' and '2020-09-22' GROUP BY vin)as a
WHERE a.daymile > 50



