第一次个人编程作业
https://github.com/ying-hua/031902207
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 600 | 900 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 180 | 360 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 600 | 900 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处
3.1.1 关键算法
我用了DFA算法来实现关键词检测功能,当检测到敏感词开头时进入一个状态,通过检测每个字符来判断状态如何转移。参考博客
- 状态转移如图
- 在python中可以用字典来很方便地生成数据结构
state_event_dict = {
"匹": {
"配": {
"关": {
"键": {
"词": {
"is_end": True
},
"is_end": False
},
"is_end": False
},
"is_end": True
},
"is_end": False
}
}
- 但是为了实现拼音替换和偏旁部首拆分的检测需要修改
我给字典中的元素都加上了"pinyin"和"chaizi"的标签
{
"法":{...},
"pinyin":"pi",
"chaizi":"氵去",
"is_end":False
}
每个字的拼音通过调用pypinyin库来生成
- 插入字符
我在当前匹配的状态中加入了"other"标志来判断插入字符的个数
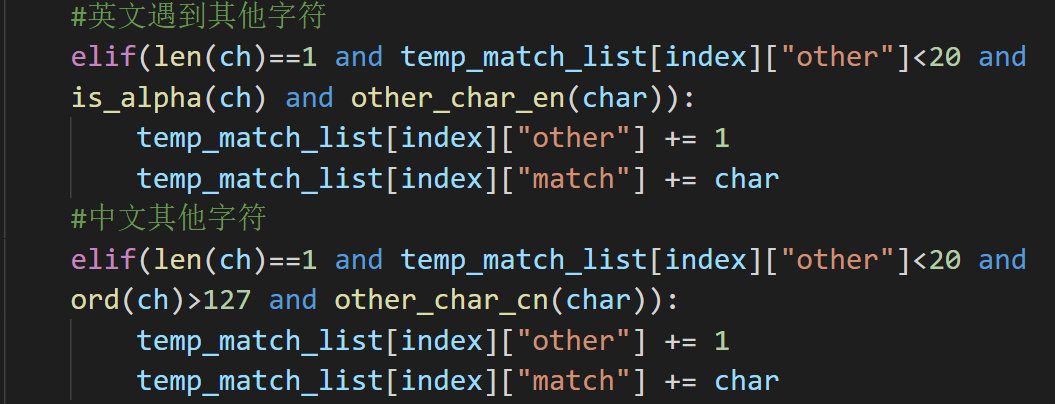
- 拼音替换和谐音替换
我通过字段中词语的"pinyin"和当前读取到的字符对比,如果正确就进入状态
谐音替换是通过比较原字和替换后的字的拼音实现的 - 拆字变形
拆字的变形和拼音类似,调用拆字库将读取到的字符和标签"chaizi"比较
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
我用了SnakViz工具和python自带的cProfile进行可视化分析
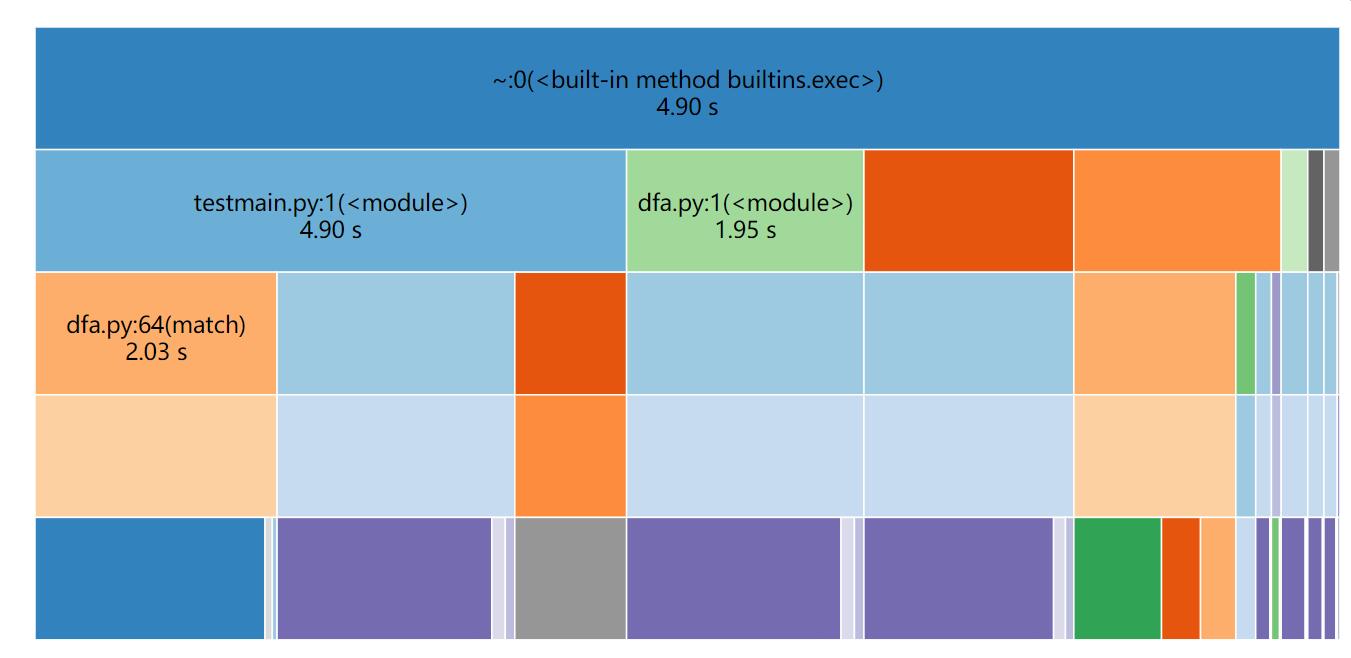

可以看到,lazy_pinyin函数所花的时间最长。这是因为谐音替换需要查看每个字的拼音,而我的代码中每个字不止调用了一次lazy_pinyin函数。我想可以减少lazy_pinyin的调用次数,让每个字只调用一次lazy_pinyin,一个可以大幅降低时间。
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
#测试中英文插入字符和大小写的匹配
def test_Insert(self):
dfa_match=dfa.DFA(["垃圾","litter"])
content="as2垃_()!* 圾分类阿斯&*a 利康aujLI2 &*!t(teRPas_"
ans=[{"keyword":"垃圾","match":"垃_()!* 圾"},{"keyword":"litter","match":"LI2 &*!t(teR"}]
res=dfa_match.match(content)
self.assertEqual(ans,res)
#测试中文拼音及首字母
def test_pinyin(self):
dfa_match=dfa.DFA(["垃圾","歇脚"])
content="as2分类阿L *&a () !@jI awns a9X_i_ejI wwW"
ans=[{"keyword":"垃圾","match":"L *&a () !@jI"},{"keyword":"歇脚","match":"X_i_ej"}]
res=dfa_match.match(content)
self.assertEqual(ans,res)
#测试谐音和拆分
def test_xieyin_and_chaifen(self):
dfa_match=dfa.DFA(["垃圾","歇脚"])
content="as2分类土立_ *&土_!* 及 () !@jI 写_%^@&*@ 珓 wwW"
ans=[{"keyword":"垃圾","match":"土立_ *&土_!* 及"},{"keyword":"歇脚","match":"写_%^@&*@ 珓"}]
res=dfa_match.match(content)
self.assertEqual(ans,res)
单元覆盖测试率截图

(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
文件异常
def file_error(file):
try:
f = open(file, "r")
except IOError:
print("文件不存在")
exit(0)
else:
f.close()
输入参数异常
def argv_error():
if(len(sys.argv)!=4):
print("参数个数错误")
else:
return
三、心得
刚看到题目的时候很懵,不知道怎么下手,特别是还要检测拼音和偏旁。本以为要访问网上的拼音数据库或者自己手动写所有汉字的拼音,但是那样工作量太大了,不可能完成。后来搜索后发现有pypinyin库,拼音的问题解决了,接下来就是偏旁部首的问题。找了很久偏旁的库,可是只找到了汉字偏旁的库,不知道汉字除了偏旁外的字根怎么办。本想放弃偏旁的检测,但是后来发现汉字拆字库,正好符合我的需求。
这周我才开始代码的编写,时间有点赶。之前一直在思考用那种算法和实现的可能性,我写这句话的时候离ddl还有半小时QAQ。以后一定要尽早开始代码的设计与编写,不要高估了自己的效率。上一篇博客说好的不熬夜,结果还是熬了QAQ
我刚开始从简单的需求开始写,到后面需求越来越多,代码越来越臃肿,这是考虑不周到的地方。以后要事先设计好整体的逻辑再编写,不然后面调bug的时候会越来越麻烦,一大堆标记和特判自己都看不过来。
最后的检测准确率我还是比较满意的,但是效率实在是太低了,测了一下发现竟然有4s多,有时间肯定要优化一下。最后还是有一些bug,拼音和偏旁的一些bug实在不好解决,解决完后又会出现很多新bug。不过问题不大,希望测试样例不要太奇怪。
最后放上检测图片

