训练集、验证集和测试集的意义(转)
转自: https://blog.csdn.net/ch1209498273/article/details/78266558
在有监督的机器学习中,经常会说到训练集(train)、验证集(validation)和测试集(test),这三个集合的区分可能会让人糊涂,特别是,有些读者搞不清楚验证集和测试集有什么区别。
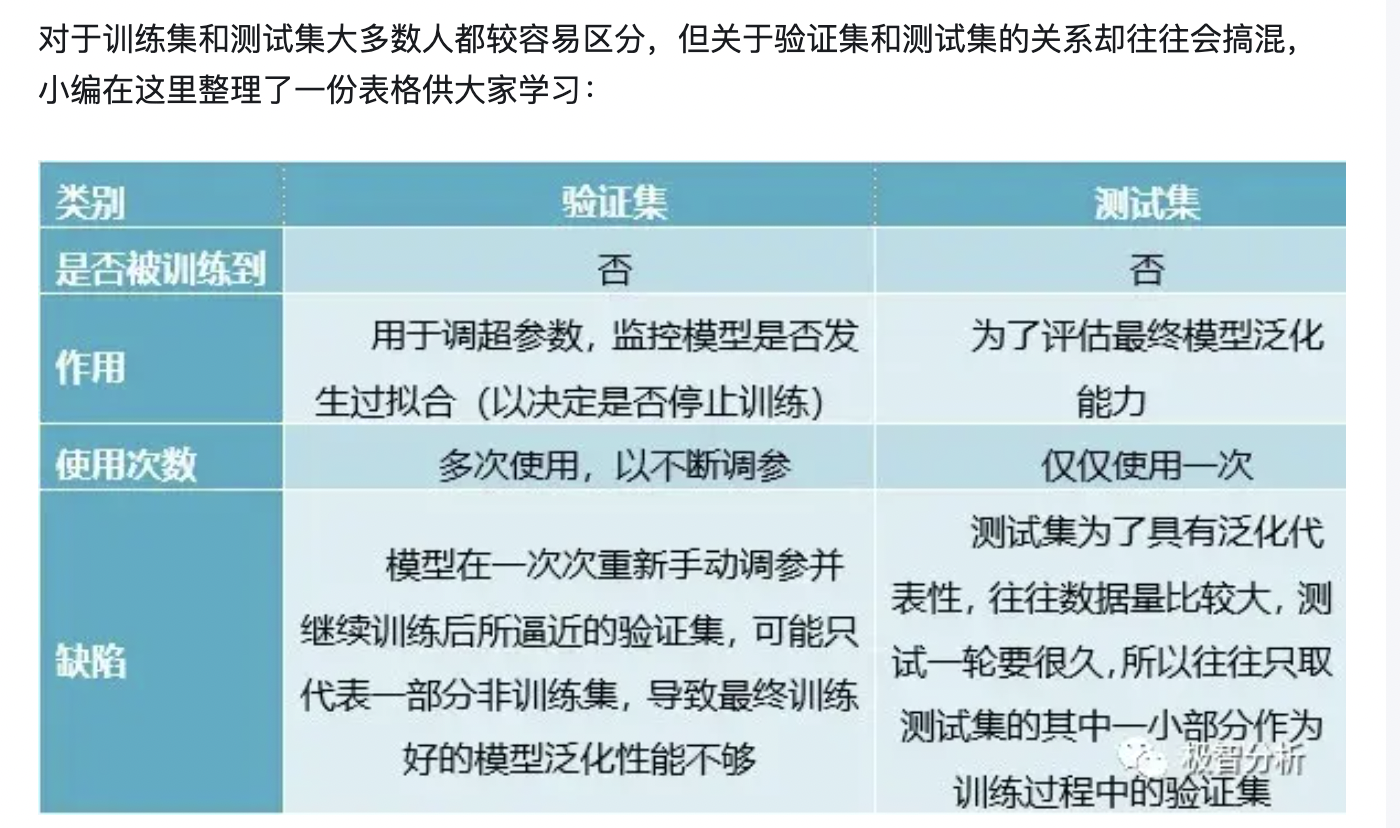
这个validation data是什么?它其实就是用来避免过拟合的,在训练过程中,我们通常用它来确定一些超参数(比如根据validation data上的accuracy来确定early stopping的epoch大小、根据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?因为如果在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有任何参考意义。因此,training data的作用是计算梯度更新权重,validation data如上所述,testing data则给出一个accuracy以判断网络的好坏。
总结:
I. 划分
如果我们自己已经有了一个大的标注数据集,想要完成一个有监督模型的测试,那么通常使用均匀随机抽样的方式,将数据集划分为训练集、验证集、测试集,这三个集合不能有交集,常见的比例是8:1:1,当然比例是人为的。从这个角度来看,三个集合都是同分布的。
如果是做比赛,官方只提供了一个标注的数据集(作为训练集)以及一个没有标注的测试集,那么我们做模型的时候,通常会人工从训练集中划分一个验证集出来。这时候我们通常不再划分一个测试集,可能的原因有两个:1、比赛方基本都很抠,训练集的样本本来就少;2、我们也没法保证要提交的测试集是否跟训练集完全同分布,因此再划分一个跟训练集同分布的测试集就没多大意义了。
II. 参数
有了模型后,训练集就是用来训练参数的,说准确点,一般是用来梯度下降的。而验证集基本是在每个epoch完成后,用来测试一下当前模型的准确率。因为验证集跟训练集没有交集,因此这个准确率是可靠的。那么为啥还需要一个测试集呢?
这就需要区分一下模型的各种参数了。事实上,对于一个模型来说,其参数可以分为普通参数和超参数。在不引入强化学习的前提下,那么普通参数就是可以被梯度下降所更新的,也就是训练集所更新的参数。另外,还有超参数的概念,比如网络层数、网络节点数、迭代次数、学习率等等,这些参数不在梯度下降的更新范围内。尽管现在已经有一些算法可以用来搜索模型的超参数,但多数情况下我们还是自己人工根据验证集来调。
III. 所以
那也就是说,从狭义来讲,验证集没有参与梯度下降的过程,也就是说是没有经过训练的;但从广义上来看,验证集却参与了一个“人工调参”的过程,我们根据验证集的结果调节了迭代数、调节了学习率等等,使得结果在验证集上最优。因此,我们也可以认为,验证集也参与了训练。
那么就很明显了,我们还需要一个完全没有经过训练的集合,那就是测试集,我们既不用测试集梯度下降,也不用它来控制超参数,只是在模型最终训练完成后,用来测试一下最后准确率。
IV. 然而
聪明的读者就会类比到,其实这是一个无休止的过程。如果测试集准确率很差,那么我们还是会去调整模型的各种参数,这时候又可以认为测试集也参与训练了。好吧,我们可能还需要一个“测试测试集”,也许还需要“测试测试测试集”...
算了吧,还是在测试集就停止吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号