12.12实验八:随机森林算法实现与测试
实验八:随机森林算法实现与测试
一、实验目的
深入理解随机森林的算法原理,进而理解集成学习的意义,能够使用 Python 语言实现随机森林算法的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注意同分布取样);
(2)使用训练集训练随机森林分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验八的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
开始
- 特征 X = iris.data
- 标签 y = iris.target
- 使用留出法,测试集占 1/3
- 确保分层抽样以保持标签分布
- 设置树的数量为 100
- 设置随机种子以确保结果可重复
- 调用训练方法
- 准确度
- 精度(加权)
- 召回率(加权)
- F1 值(加权)
- 对训练集进行交叉验证
- 计算每个评分指标的平均值
- 调用预测方法
- 显示准确度、精度、召回率和 F1 值
结束
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
'''
Created on 2024年12月12日
@author: 席酒
'''
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, classification_report
# 加载 iris 数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 标签
# 使用留出法将数据集分为训练集和测试集,测试集占 1/3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf_classifier.fit(X_train, y_train)
# 定义评分指标
scoring = {
'accuracy': make_scorer(accuracy_score),
'precision': make_scorer(precision_score, average='weighted'),
'recall': make_scorer(recall_score, average='weighted'),
'f1': make_scorer(f1_score, average='weighted')
}
# 进行五折交叉验证
scores = {metric: cross_val_score(rf_classifier, X_train, y_train, cv=5, scoring=scorer).mean() for metric, scorer in scoring.items()}
print("交叉验证结果:")
print(scores)
# 使用测试集进行预测
y_pred = rf_classifier.predict(X_test)
# 输出分类报告
report = classification_report(y_test, y_pred)
print("测试集分类报告:")
print(report)
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
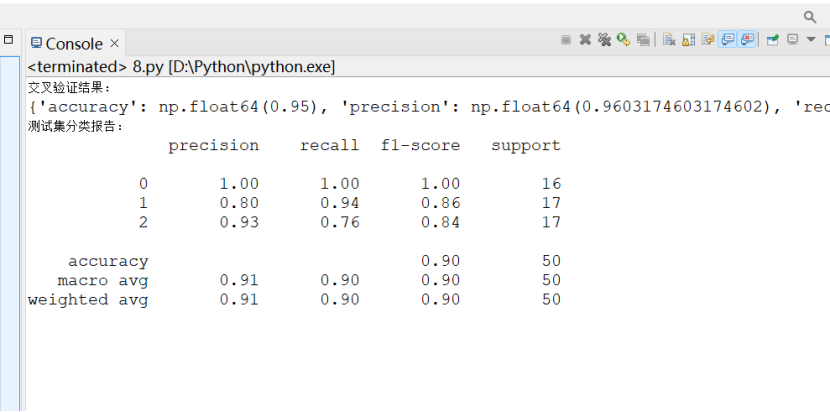
四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
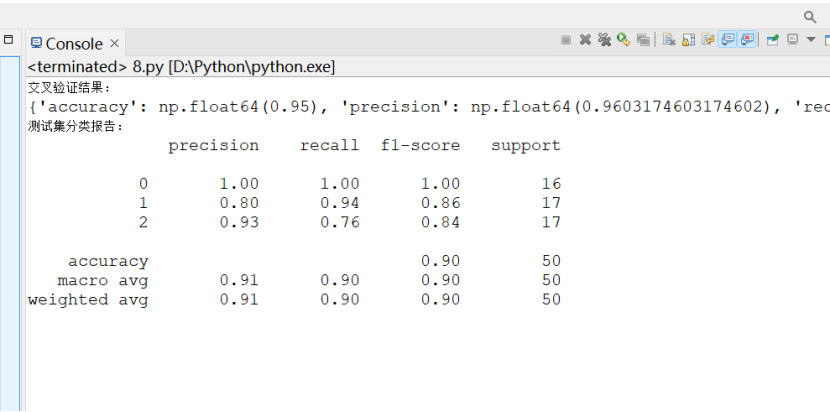
2. 对比分析
|
类别 |
精度 (Precision) |
召回率 (Recall) |
F1 值 (F1 Score) |
支持 (Support) |
|
0 |
1.00 |
1.00 |
1.00 |
16 |
|
1 |
0.80 |
0.94 |
0.86 |
17 |
|
2 |
0.93 |
0.76 |
0.84 |
17 |
|
总体 |
0.90 |
0.90 |
0.90 |
50 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号