12.10实验六:朴素贝叶斯算法实现与测试
一、实验目的
深入理解朴素贝叶斯的算法原理,能够使用 Python 语言实现朴素贝叶斯的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注意同分布取样);
(2)使用训练集训练朴素贝叶斯分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验六的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
开始
- 导入数据集处理库
- 导入模型选择和评估库
- X = 特征数据
- y = 标签数据
- 使用留出法,测试集占 1/3
- 确保分层抽样以保持类别分布
- model = 创建高斯朴素贝叶斯分类器
- model.训练(X_train, y_train)
- cv_scores = 计算交叉验证得分
- y_pred = 交叉验证预测(X_train, y_train)
- accuracy = 计算准确度(y_train, y_pred)
- precision = 计算精度(y_train, y_pred)
- recall = 计算召回率(y_train, y_pred)
- f1 = 计算 F1 值(y_train, y_pred)
- 打印交叉验证准确度
- 打印训练集准确度
- 打印精度
- 打印召回率
- 打印 F1 值
- y_test_pred = model.预测(X_test)
- test_accuracy = 计算准确度(y_test, y_test_pred)
- test_precision = 计算精度(y_test, y_test_pred)
- test_recall = 计算召回率(y_test, y_test_pred)
- test_f1 = 计算 F1 值(y_test, y_test_pred)
- 打印测试集准确度
- 打印测试集精度
- 打印测试集召回率
- 打印测试集 F1 值
结束
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
'''
Created on 2024年12月12日
@author: 席酒
'''
from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score
# 加载 iris 数据集
iris = datasets.load_iris()
X = iris.data # 特征
y = iris.target # 标签
# 留出法,分割数据集,测试集占 1/3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
# 创建朴素贝叶斯分类器
model = GaussianNB()
# 使用训练集训练模型
model.fit(X_train, y_train)
# 进行五折交叉验证
cv_scores = cross_val_score(model, X_train, y_train, cv=5)
# 使用交叉验证预测
y_pred = cross_val_predict(model, X_train, y_train, cv=5)
# 计算评估指标
accuracy = accuracy_score(y_train, y_pred)
precision = precision_score(y_train, y_pred, average='weighted')
recall = recall_score(y_train, y_pred, average='weighted')
f1 = f1_score(y_train, y_pred, average='weighted')
# 输出评估结果
print(f'交叉验证准确度: {cv_scores.mean()}')
print(f'训练集准确度: {accuracy}')
print(f'精度: {precision}')
print(f'召回率: {recall}')
print(f'F1 值: {f1}')
# 使用测试集进行预测
y_test_pred = model.predict(X_test)
# 计算测试集的评估指标
test_accuracy = accuracy_score(y_test, y_test_pred)
test_precision = precision_score(y_test, y_test_pred, average='weighted')
test_recall = recall_score(y_test, y_test_pred, average='weighted')
test_f1 = f1_score(y_test, y_test_pred, average='weighted')
# 输出测试结果
print(f'测试集准确度: {test_accuracy}')
print(f'测试集精度: {test_precision}')
print(f'测试集召回率: {test_recall}')
print(f'测试集 F1 值: {test_f1}')
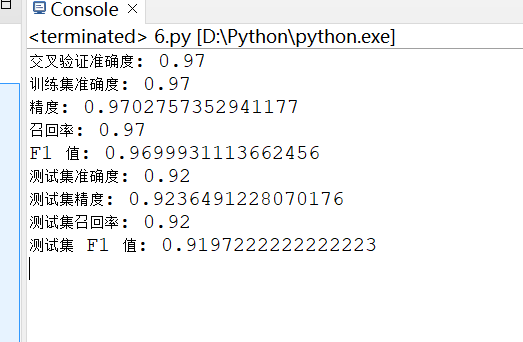
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
四、实验结果分析
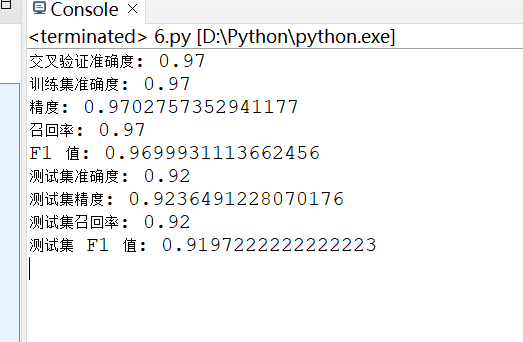
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
2. 对比分析
高准确度、精度、召回率和 F1 值表明模型能够有效地分类 iris 数据集中的不同类别。过拟合风险:虽然训练集和交叉验证的准确度都很高,但测试集的准确度略低,可能存在轻微的过拟合现象。尽管如此,92% 的测试集准确度仍然是一个很好的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号