

实验三:C4.5(带有预剪枝和后剪枝)算法实现与测试
一、实验目的
深入理解决策树、预剪枝和后剪枝的算法原理,能够使用 Python 语言实现带有预剪枝和后剪枝的决策树算法 C4.5 算法的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注
意同分布取样);
(2)使用训练集训练分类带有预剪枝和后剪枝的 C4.5 算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选
择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验三的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
开始
# 导入必要的库
导入 pandas
导入 sklearn.datasets 中的 load_iris
导入 sklearn.model_selection 中的 train_test_split, cross_val_predict 和 KFold
导入 sklearn.tree 中的 DecisionTreeClassifier
导入 sklearn.metrics 中的 accuracy_score, precision_score, recall_score 和 f1_score
# 1. 加载 Iris 数据集
加载 iris 数据集
将特征赋值给 X
将标签赋值给 y
# 2. 划分数据集,将 1/3 的样本作为测试集
将数据集划分为训练集和测试集,测试集占 1/3,保持标签的比例,随机种子为 42
输出训练集和测试集的大小
# 3. 使用决策树分类器进行建模,实现预剪枝
创建一个决策树分类器,使用 'entropy' 作为标准,最大深度为 4
使用训练集训练决策树分类器
# 4. 五折交叉验证评估模型性能
创建一个 KFold 对象,设置为 5 折交叉验证,随机种子为 42,打乱数据
# 获取交叉验证的预测结果
使用交叉验证预测训练集的标签
# 计算绩效指标
计算训练集的准确度
计算训练集的加权精度
计算训练集的加权召回率
计算训练集的加权 F1 值
# 输出交叉验证结果
输出准确度、精度、召回率和 F1 值
# 5. 使用测试集,测试模型性能
使用训练好的模型对测试集进行预测
# 计算测试集的性能指标
计算测试集的准确度
计算测试集的加权精度
计算测试集的加权召回率
计算测试集的加权 F1 值
# 输出测试集的性能指标
输出测试集的准确度、精度、召回率和 F1 值
结束
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
'''
Created on 2024年11月26日
@author: 席酒
'''
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_predict, KFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 1. 加载 Iris 数据集
iris = load_iris()
X, y = iris.data, iris.target
# 2. 划分数据集,将 1/3 的样本作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, stratify=y, random_state=42)
print(f"训练集大小: {X_train.shape[0]}, 测试集大小: {X_test.shape[0]}")
# 3. 使用决策树分类器进行建模,实现预剪枝
clf = DecisionTreeClassifier(criterion='entropy', max_depth=4, random_state=42) # 这里使用 'entropy' 作为 C4.5 的标准
clf.fit(X_train, y_train)
# 4. 五折交叉验证评估模型性能
kf = KFold(n_splits=5, random_state=42, shuffle=True)
# 获取交叉验证的预测结果
y_pred = cross_val_predict(clf, X_train, y_train, cv=kf)
# 计算绩效指标
accuracy = accuracy_score(y_train, y_pred)
precision = precision_score(y_train, y_pred, average='weighted')
recall = recall_score(y_train, y_pred, average='weighted')
f1 = f1_score(y_train, y_pred, average='weighted')
print("交叉验证结果:")
print(f"准确度: {accuracy:.2f}")
print(f"精度: {precision:.2f}")
print(f"召回率: {recall:.2f}")
print(f"F1 值: {f1:.2f}")
# 5. 使用测试集,测试模型性能
y_test_pred = clf.predict(X_test)
# 计算测试集的性能指标
test_accuracy = accuracy_score(y_test, y_test_pred)
test_precision = precision_score(y_test, y_test_pred, average='weighted')
test_recall = recall_score(y_test, y_test_pred, average='weighted')
test_f1 = f1_score(y_test, y_test_pred, average='weighted')
print("在测试集上的性能指标:")
print(f"准确度: {test_accuracy:.2f}")
print(f"精度: {test_precision:.2f}")
print(f"召回率: {test_recall:.2f}")
print(f"F1 值: {test_f1:.2f}")
- 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
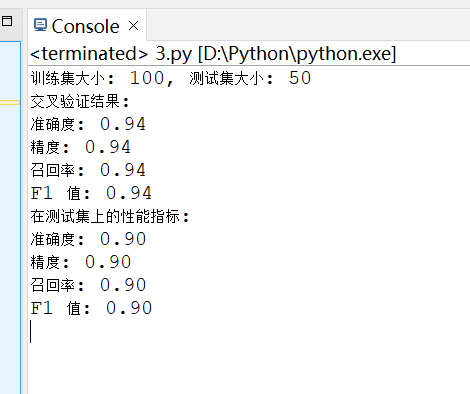
四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
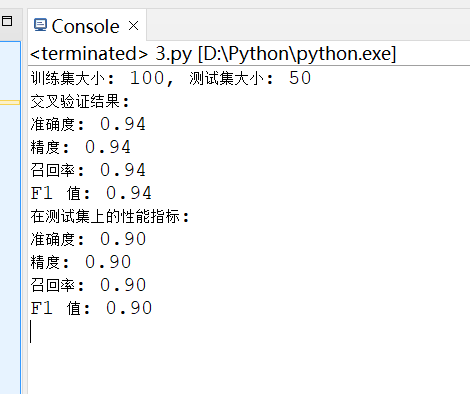
2. 对比分析
模型在训练集和测试集上的表现都相对较好,尤其是在训练集上达到了 94% 的高准确度和其他指标。测试集的结果虽然略低,但仍然保持在 90% 以上,表明模型具有良好的泛化能力。尽管训练集的性能指标较高,但测试集的结果略低,可能表明模型存在轻微的过拟合现象。过拟合是指模型在训练数据上表现很好,但在新数据上表现不佳。为了进一步验证模型的泛化能力,可以考虑使用更多的数据或进行更严格的交叉验证。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下