

用 node.js的 Apify 框架去爬取网页
index.ts
import Apify from 'apify'
Apify.main(async () => {
const requestQueue = await Apify.openRequestQueue();
await requestQueue.addRequest({
url: 'https://onlinelibrary.wiley.com/doi/10.1002/ccr3.5509',
});
await requestQueue.addRequest({
url: 'https://onlinelibrary.wiley.com/doi/10.1002/ccr3.5521',
});
const crawler = new Apify.PlaywrightCrawler({
requestQueue,
handlePageFunction: async ({request, page}) => {
const title = await page.title();
console.log(`Title of ${request.url}:\n ${title}`);
const abstract = await page.innerText('section.article-section__abstract > div.article-section__content > p');
console.log(`Abstract of ${request.url}:\n`);
console.log(abstract);
},
});
await crawler.run();
console.log('Crawler finished.');
});
package.json:
{
"name": "spider",
"main": "build/index.js",
"scripts": {
"start": "tsc -p tsconfig.json && node ./build/index.js",
"start:prune": "rm -rf apify_storage && tsc -p tsconfig.json && node ./build/index.js",
"build": "tsc -p tsconfig.json"
},
"dependencies": {
"apify": "^2.2.2",
"playwright": "^1.19.2",
"puppeteer": "^13.5.0"
},
"devDependencies": {
"@types/node": "^17.0.21",
"@types/puppeteer": "^5.4.5",
"typescript": "^4.6.2"
},
"packageManager": "yarn@3.2.0"
}
融入我的爬虫系统中:
由于我的node版本是14,所以安装了:"apify": "^1.3.1"
运行爬取一次后,再次运行,程序不再成功爬取网页内容,会出现警告,是因为apify为了避免重复爬取,在爬取一次后,会建立缓存存储爬取相关数据,不允许再次爬取:
也可以自己在环境变量中设置缓存存储位置,通过变量:APIFY_LOCAL_STORAGE_DIR
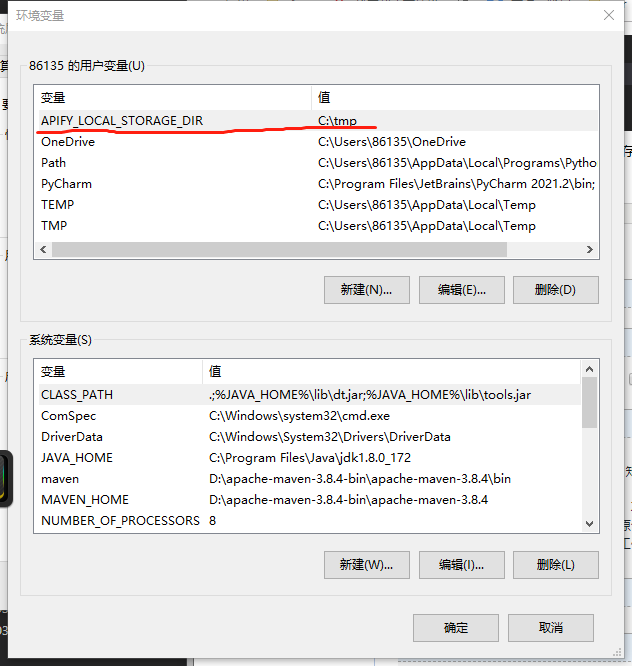
把apify_storage的文件夹删除后,爬虫就可以继续爬取了。
