
软件工程--个人项目
软件工程个人项目
1. 作业概述
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业的要求在哪里 | 个人项目 |
| 这个作业的目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率 |
| Github链接 | 链接 |
2. 需求分析
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
查阅资料后总结以下思路:
- 先将标点符号去除
- 将待处理数据进行分片,放置在列表中,计算并记录出现次数,将次数列出等价于得到一个向量
- 将两个数据得到的向量带到夹角余弦定理
- 计算夹角余弦定理的偏移量,即两个数据的相似度
3.接口设计
jieba.lcut
该接口用于将中文文本字符串精确的分词后,返回分词后的列表变量
re.match
由于对比对象为中文或英文单词,因此应该对读取到的非要求数据都将他过滤掉,这里选择用正则表达式来匹配符合的数据。
Counter
数学家已经证明,余弦的这种计算方法对n维向量也成立,假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:
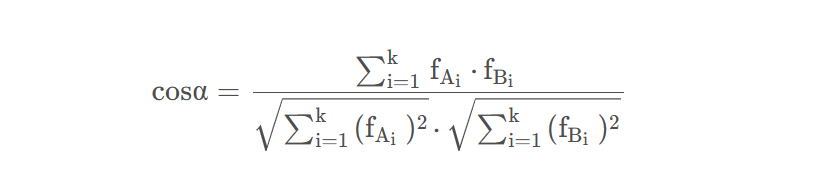
4.文件模块设计
1.读取文件内容
def Getfile_contents(path): # 获取文件内容
str = ''
with open(path, "r", encoding='UTF-8') as f:
line = f.readline()
while line: # 如果一次没有都玩文件,后续可以继续读
str = str + line
line = f.readline() # 内容过大时继续读取文件操作,存在就读取,不存在退出
print("读取数据内容任务完成")
f.close() # 关闭文件
return str # 提取读取文件数据
通过主函数中文件传入的地址,将文件中的内容读出来,返回文件读取到的数据
2.删除与数据不相关内容
def Delete_useless(content): # 删除与数据不相关内容
content = jieba.lcut(content)
result = []
for tags in content:
if (re.match(u"[a-zA-Z0-9\u4e00-\u9fa5]", tags)): # 至少一个汉字、数字、字母、下划线 与 tags作比较,存在则放入队列中
result.append(tags) # 将分好的数据放到列表中
else:
pass # 没有需要放的汉字后退出循环
return result
通过主函数中传入的地址,调用jieba库中的jieba.lcut函数将数据进行切片,将切片内容放置到列表中,返回列表
3.计算相似度
def cos_sim(final_content1, final_contet2): # final_content1,final_contet2是分词后的标签列表
finalcontent1 = (Counter(final_content1)) # 设置第一个向量
finalcontent2 = (Counter(final_content2)) # 设置第二个向量
content_final1 = []
content_final2 = []
for temp in set(final_content1 + final_content2): # 将两个向量对应的数据放置到列表中
content_final1.append(finalcontent1[temp])
content_final2.append(finalcontent2[temp])
content_final1 = np.array(content_final1)
content_final2 = np.array(content_final2)
return content_final1.dot(content_final2) / \
(np.sqrt(content_final1.dot(content_final1)) * np.sqrt(content_final2.dot(content_final2)))
# 最后利用公式返回求出的相似度的大小
将切片完成好的队列传到函数中,将数据记录出现次数,设置为向量后带入到公式中,求出公式的结果返回的值为相似度
5.性能分析
1.性能参数分析
采用pycharm中自带的profile分析性能插件进行分析
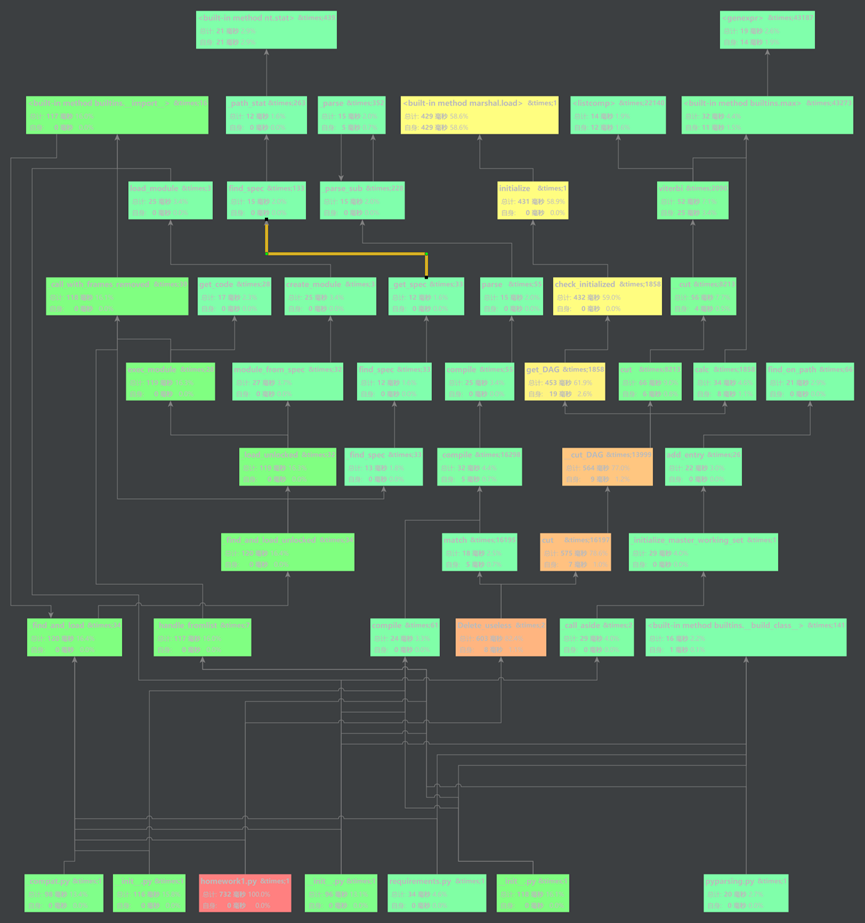
数据性能的参数:
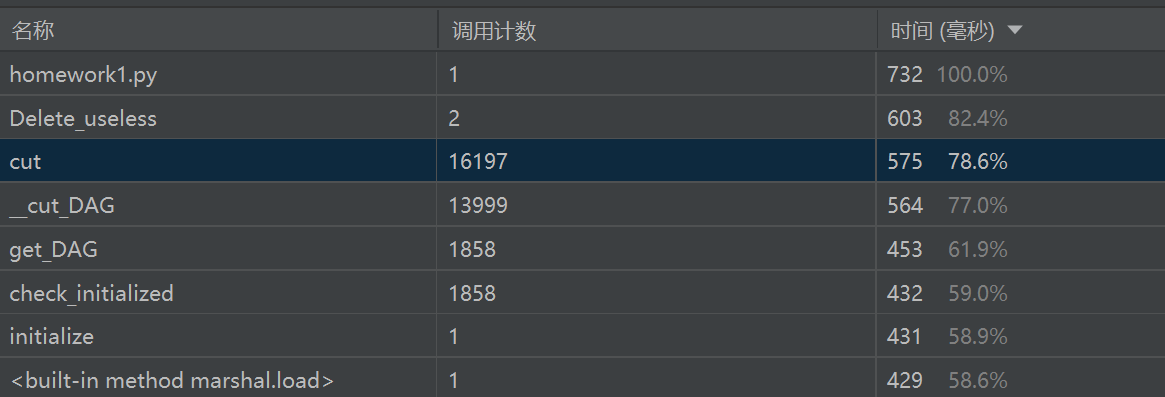
分析:总耗费时间为732ms,在优化方面想到可以提升Delete_useless函数,是否可以采用分批处理文件,减少列表占用内存的空间,修改代码为:
def Delete_useless(content):
content = jieba.cut(content)
batch_size = 1000 # 每批处理的数据量
result = []
batch = []
for tag in content:
if tag.isalnum():
batch.append(tag)
if len(batch) >= batch_size:
result.extend(batch)
batch = []
# 处理可能剩余的数据
if batch:
result.extend(batch)
return result
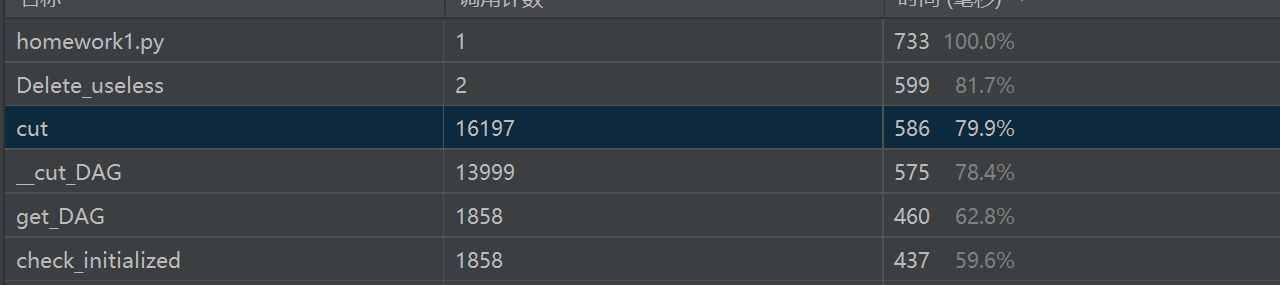
可见采用方法后,Delete_useless函数的性能得到了一定的提升
2.覆盖率情况
覆盖率达到100%

6.单元测试
1. def test_Getfile_contents(self):
创建一个临时文本文件供测试使用,确定文件建立成功
def test_Getfile_contents(self):
with open('temp.txt', 'w', encoding='utf-8') as temp_file: # 创建一个临时文本文件供测试使用
temp_file.write('This is a test text.')
content = Getfile_contents('temp.txt') # 测试文件存在的情况
self.assertEqual(content, 'This is a test text.')
2. def test_read_existing_file(self):#
测试读取存在的文件并检查内容是否正确,在原来以后信息的情况下重新输入数据,观察预期输出和实际输出的差别
def test_read_existing_file(self):
file_path = 'test_file.txt'
expected_content = 'This is a test file content.'
with open(file_path, 'w') as file:
file.write(expected_content)
with open(file_path, 'r') as file:
actual_content = file.read()
self.assertEqual(actual_content, expected_content)
3. def test_read_non_existing_file(self):
测试读取不存在的文件并检查是否引发了FileNotFoundError异常
def test_read_non_existing_file(self):
file_path = 'non_existing_file.txt'
with self.assertRaises(FileNotFoundError):
with open(file_path, 'r') as file:
file.read()
4. def test_read_with_different_encodings(self):
测试使用不同的编码方式读取文件并确保内容正确
def test_read_with_different_encodings(self):
file_path = 'encoded_file.txt'
content = '这是一个测试文件内容。'
# 以不同编码方式保存文件
encodings = ['utf-8', 'utf-16', 'iso-8859-1']
for encoding in encodings:
with open(file_path, 'w', encoding="utf-8") as file:
file.write(content)
with open(file_path, 'r', encoding="utf-8") as file:
actual_content = file.read()
self.assertEqual(actual_content, content)
5.def test_read_binary_file(self):
测试读取二进制文件并检查内容是否正确
def test_read_binary_file(self):
file_path = 'binary_file.bin'
expected_content = b'\x48\x65\x6c\x6c\x6f\x2c\x20\x57\x6f\x72\x6c\x64'
with open(file_path, 'wb') as file:
file.write(expected_content)
with open(file_path, 'rb') as file:
actual_content = file.read()
self.assertEqual(actual_content, expected_content)
6. def test_file_size(self):
测试文件的大小是否正确
def test_file_size(self):
file_path = 'test_file_size.txt'
expected_size = 1024 # 1 KB
with open(file_path, 'wb') as file:
file.write(b'0' * expected_size)
actual_size = os.path.getsize(file_path)
self.assertEqual(actual_size, expected_size)
7. def test_Delete_useless2(self):
测试垃圾处理函数
def test_Delete_useless2(self):
input_text = "I am a boy,hey."
expected_output = ["I","am","a","boy","hey"]
cleaned_text = Delete_useless(input_text)
self.assertEqual(cleaned_text, expected_output)
8. def test_delete_useless_empty_text(self):
测试空文本输入
def test_delete_useless_empty_text(self):
text = ""
expected_result = []
self.assertEqual(Delete_useless(text), expected_result)
9.def test_delete_useless_all_punctuation(self):
测试只包含标点符号的文本
text = ",。!?"
expected_result = [",", "。", "!", "?"]
self.assertEqual(Delete_useless(text), expected_result)
10.def test_cos_sim(self):
测试计算相似度准确度
def test_cos_sim(self):
final_content1 = ["这", "是", "一段", "示例文本"]
final_content2 = ["这", "是", "另外一段", "示例文本"]
similarity = cos_sim(final_content1, final_content2)
expected_similarity = 0.75
tolerance = 0.1
self.assertAlmostEqual(similarity, expected_similarity, delta=tolerance)
测试程序的覆盖率:
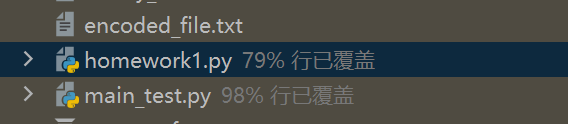
7.异常处理
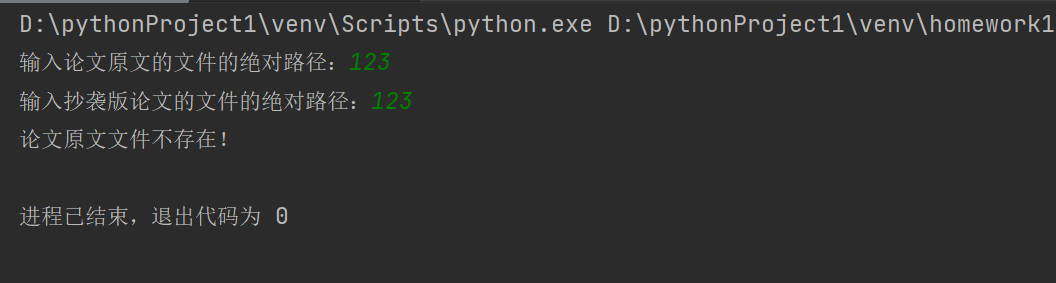
def main_test():
path1 = input("输入论文原文文件绝对路径:")
path2 = input("输入抄袭版论文文件绝对路径:")
if not os.path.exists(path1):
print("论文原文文件不存在!")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在!")
exit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号