openpyxl操作excel教程
openpyxl使用—Excel篇
1.安装openpyxl
安装openxlsx
pip install openpyxl
2.创建/打开、保存工作簿
2.1创建新的工作簿
from openpyxl import Workbook
#新建一个工作簿
#实例化一个对象
wb =Workbook()
ws = wb.active #获取默认的工作表
print(ws.title) # 返回工作表名,Sheet
#保存的位置
#加r是为了解决转义的问题
wb.save(r"F:\desktop\aaa\test.xlsx")
wb.close()
2.2 打开已有的工作簿
from openpyxl import load_workbook
# 打开已存在的工作簿
wb =load_workbook(r"F:\desktop\aaa\test.xlsx")
ws = wb.active
print(ws.title)
ws.title = "default_2" #改变标题名为default_2
wb.save(r"F:\desktop\aaa\test.xlsx") #保存
2.3保存工作簿
2.3.1 保存为文件
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
print(ws.title)
wb.save("./test.xlsx") # 保存到硬盘
wb.close() # 该方法在只读或只写模式下有用
注意,通过保存路径和文件名相同会覆盖原先的文件,不会有提示
2.3.2 保存为流文件
有时候你需要保存为流文件,通过web应用服务进行传输,可以使用下面的方法
from tempfile import NamedTemporaryFile
from openpyxl import Workbook
wb = Workbook()
with NamedTemporaryFile() as tmp:
wb.save(tmp.name)
tmp.seek(0)
stream = tmp.read()
2.4 工作表信息
print(ws.max_row) # 最大行数,例如14
print(ws.max_column) # 最大列数,例如20
print(ws.dimensions) # 已启用的单元格范围,例如A1:T14
print(ws.encoding) # 编码类型,例如utf-8
print(ws.sheet_view) # 对象信息
3.操作单元格(获取、修改、合并,删除等)
3.1 操作工作表(创建、改名、移动、复制、删除)
from openpyxl import Workbook
wb =Workbook()
ws1 = wb.active
print(ws1.title) # 返回工作表名,Sheet
print(wb.sheetnames)
# create_sheet(title,index),接收两个参数,表名和位置
# title:表名
# index:下标即位置,从0开始
#创建sheet2工作簿,在2的位置,一开始索引为0
ws2 = wb.create_sheet("Sheet2",1)
ws3 = wb.create_sheet("Sheet3",2)
# 通过表名获取表
ws4=wb["Sheet3"]
print(ws4.title)
#将sheet3工作簿做移动一位, -1为向左移动,+1为向右移动
wb.move_sheet(ws3,-1)
#删除sheet3工作簿
# del wb["Sheet3"]
# 获取表的下标位置(下标从0开始)
index = wb.index(ws2)
print("get_index:", index)
print(wb.sheetnames)
3.2获取和修改单个单元格
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
cell = ws["a6"] # 通过坐标获取
cell2 = ws.cell(1, 2) # 通过行列下标获取
# 直接修改某个单元格的值
ws["a5"] = 666
ws['A3'] = datetime.datetime.now().strftime("%Y-%m-%d") # 修改为时间类型
ws.append([1, 2, 3]) # 在最下面新增一行追加一个或多个值
# 先获取单元格对象然后再进行修改
cell = ws["a6"]
cell.value = 777
print(cell, cell.value) # 输出:<Cell 'Sheet'.A6> 777
cell2 = ws.cell(6, 1) # 第6行第1列,即A6
print(cell2, cell2.value) # 输出:<Cell 'Sheet'.A6> 777
# 单元格坐标信息
print(c.coordinate) # 单元格坐标,例如A6
print(c.column_letter) # 单元格列名,例如A
print(c.col_idx) # 单元列下标,例如1
print(c.row) # 单元格所在行,例如6
1.如果使用cell(row, column, value)获取,第一个参数是行,第二个参数是列,下标都是从1开始,例如,ws[“a6”]等同于ws.cell(6, 1),但如果指定了第三个参数value,则修改了该单元格的值
2.只要访问了一个cell就会被创建,不管是否赋值
根据上面的方式,我们可以通过循环来准备一下数据
from openpyxl import Workbook
wb =Workbook()
ws = wb.active
x=1
for i in range(1,11):
for j in range(1,6):
ws.cell(i,j,x)
x += 1
wb.save("./fangwen.xlsx")
这样我们就得到了从1~50共50个(10行5列)单元格的数据
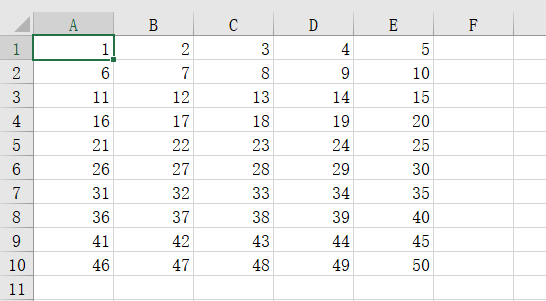
3.3 获取多个单元格
3.3.1 通过范围取值
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
i = 1
for x in range(1, 11):
for y in range(1, 21):
ws.cell(row=x, column=y, value=i)
i += 1
# wb.save("test.xlsx")
row_cells = ws[2] # 选取第2行(下标从1开始)
print(row_cells) # 输出:(A2, B2, C2, D2, E2, F2, G2, H2, I2, J2, K2, L2, M2, N2, O2, P2, Q2, R2, S2, T2)
col_cells = ws["b"] # 选取B列
print(col_cells) # 输出:(B1, B2, B3, B4, B5, B6, B7, B8, B9, B10)
row_range_cells = ws[2:5] # 选取2、3、4、5共4行
print(row_range_cells) # 输出:
# ((A2, B2, C2, D2, E2, F2, G2, H2, I2, J2, K2, L2, M2, N2, O2, P2, Q2, R2, S2, T2),
# (A3, B3, C3, D3, E3, F3, G3, H3, I3, J3, K3, L3, M3, N3, O3, P3, Q3, R3, S3, T3),
# (A4, B4, C4, D4, E4, F4, G4, H4, I4, J4, K4, L4, M4, N4, O4, P4, Q4, R4, S4, T4),
# (A5, B5, C5, D5, E5, F5, G5, H5, I5, J5, K5, L5, M5, N5, O5, P5, Q5, R5, S5, T5))
col_range_cells = ws["B:D"] # 选取B、C、D共3列
print(col_range_cells) # 输出:
# ((B1, B2, B3, B4, B5, B6, B7, B8, B9, B10),
# (C1, C2, C3, C4, C5, C6, C7, C8, C9, C10),
# (D1, D2, D3, D4, D5, D6, D7, D8, D9, D10))
range_cells = ws["c3:f6"] # 选取 C3到F6区域共16个元素
print(range_cells) # 输出:
# ((C3, D3, E3, F3),
# (C4, D4, E4, F4),
# (C5, D5, E5, F5),
# (C6, D6, E6, F6))
1.以上输出应该类似<Cell ‘Sheet’.A2>、 <Cell ‘Sheet’.B2>,为了好看,简化为A2、B2的形式
2.以上获取到的多个单元格,返回的是元组或元组套元组,可以通过遍历的方式访问或修改
3.3.2通过iter_rows或iter_cols迭代取值
iter_rows()与iter_cols()都可以指定最大最小的行列,下标从1开始
返回结果是生成器
...
# wb.save("test.xlsx")
cells = ws.iter_rows(min_row=1, max_row=3, min_col=2, max_col=5)
for cell in cells:
print(cell)
# 输出:
# (B1, C1, D1, E1)
# (B2, C2, D2, E2)
# (B3, C3, D3, E3)
cells = ws.iter_cols(min_row=1, max_row=3, min_col=2, max_col=5)
for cell in cells:
print(cell)
# 输出:
# (B1, B2, B3)
# (C1, C2, C3)
# (D1, D2, D3)
# (E1, E2, E3)
iter_cols和iter_rows都可以指定参数values_only=True,这样只返回值而不是cell对象
也可以使用rows或columns属性遍历全部行或列,values属性取出所有值,它们都得到迭代器,但是注意只读模式下columns属性无效
for cell in ws.rows:
print(cell)
for cell in ws.columns:
print(cell)
for row in ws.values:
for value in row:
print(value)
3.4操作单元格
3.4.1 合并单元格
合并单元格,会保留最左上角的单元格的数据和样式,其他单元格会被清空,即使取消合并。即,合并之后只保留左上角第一个单元格的数据和样式
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
i = 1
for x in range(1, 11):
for y in range(1, 21):
ws.cell(row=x, column=y, value=i)
i += 1
print(ws["C2"].value) # 输出:23
ws.merge_cells("A1:F3")
ws.unmerge_cells("A1:F3")
print(ws["C2"].value) # 输出:None
# 等同于下面的代码
# ws.merge_cells(start_row=1, start_column=1, end_row=3, end_column=6)
# ws.unmerge_cells(start_row=1, start_column=1, end_row=3, end_column=6)
wb.save("./test.xlsx")
3.4.2 删除或插入行列
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
i = 1
for x in range(1, 11):
for y in range(1, 21):
ws.cell(row=x, column=y, value=i)
i += 1
ws.insert_cols(5) # 在第5列即E列插入1列,原来的E列及后面的列都往后移动
ws.insert_rows(2, 3) # 在第2行后面插入3行
ws.delete_cols(2, 3) # 从2列开始往后删除3列
ws.delete_rows(5, 3) # 从5行开始往后删除3行
wb.save("./test.xlsx")
3.4.3 移动单元格
可以使用move_range()合并指定范围的单元格,但是注意,如果移动到的位置原来有数据会被覆盖掉,移动之后公式会丢失,可以通过设置translate=True来更新,默认是False
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
i = 1
for x in range(1, 11):
for y in range(1, 21):
ws.cell(row=x, column=y, value=i)
i += 1
ws.move_range("B1:D3", rows=6, cols=-1, translate=False) # 移动单元格,向下移动6行,向左移动1列
wb.save("./test.xlsx")
4.设置样式(字体样式、行列宽高、对齐方式等)
4.1字体样式
from openpyxl import Workbook
from openpyxl.styles import Font
wb = Workbook()
ws = wb.active
# 默认字体样式
ws["A1"] = "A1"
# 自定义字体样式
ws["B2"] = "B2"
font = Font(
name="微软雅黑", # 字体
size=15, # 字体大小
color="0000FF", # 字体颜色,用16进制rgb表示
bold=True, # 是否加粗,True/False
italic=True, # 是否斜体,True/False
strike=None, # 是否使用删除线,True/False
underline=None, # 下划线, 可选'singleAccounting', 'double', 'single', 'doubleAccounting'
)
ws["B2"].font = font
wb.save("./test.xlsx")
4.2 行列宽高
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.row_dimensions[2].height = 30 # 设置第2行高度为30
ws.column_dimensions["B"].width = 30 # 设置B列宽度为30
wb.save("./test.xlsx")
4.3 对齐方式
from openpyxl import Workbook
from openpyxl.styles import Alignment
wb = Workbook()
ws = wb.active
ws.row_dimensions[2].height = 30 # 设置第2行高度为30
ws.column_dimensions["B"].width = 30 # 设置B列宽度为30
# 默认字体样式
ws["A1"] = "A1"
ws["B2"] = "B1"
ws['B2'].alignment = Alignment(
horizontal='left', # 水平对齐,可选general、left、center、right、fill、justify、centerContinuous、distributed
vertical='top', # 垂直对齐, 可选top、center、bottom、justify、distributed
text_rotation=0, # 字体旋转,0~180整数
wrap_text=False, # 是否自动换行
shrink_to_fit=False, # 是否缩小字体填充
indent=0, # 缩进值
)
wb.save("./test.xlsx")
4.4 边框
from openpyxl import Workbook
from openpyxl.styles import Border, Side
wb = Workbook()
ws = wb.active
ws["B2"] = "B2"
side = Side(
style="medium", # 边框样式,可选dashDot、dashDotDot、dashed、dotted、double、hair、medium、mediumDashDot、mediumDashDotDot、mediumDashed、slantDashDot、thick、thin
color="ff66dd", # 边框颜色,16进制rgb表示
)
ws["B2"].border = Border(
top=side, # 上
bottom=side, # 下
left=side, # 左
right=side, # 右
diagonal=side # 对角线
)
wb.save("./test.xlsx")
4.5 填充和渐变
from openpyxl import Workbook
from openpyxl.styles import PatternFill, GradientFill
wb = Workbook()
ws = wb.active
ws["B2"] = "B2"
fill = PatternFill(
patternType="solid", # 填充类型,可选none、solid、darkGray、mediumGray、lightGray、lightDown、lightGray、lightGrid
fgColor="F562a4", # 前景色,16进制rgb
bgColor="0000ff", # 背景色,16进制rgb
# fill_type=None, # 填充类型
# start_color=None, # 前景色,16进制rgb
# end_color=None # 背景色,16进制rgb
)
ws["B2"].fill = fill
ws["B3"].fill = GradientFill(
degree=60, # 角度
stop=("000000", "FFFFFF") # 渐变颜色,16进制rgb
)
wb.save("./test.xlsx")
5.使用公式、复制(翻译)公式
5.1可用公式
当然我演示的openpyxl版本是3.0.9,一共支持352个公式,公式保存在一个frozenset类型的集合了,我们可以通过python的in语法判断是否支持某个公式,记住每个公式都是大写的
from openpyxl.utils import FORMULAE
print(FORMULAE) # frozenset({'ODD', 'VDB', 'RANK', 'LOGEST', 'ISNONTEXT', 'COUNTA'...
print(len(FORMULAE)) # 352
# 判断是否支持某个公式,公式名区分大小写
print("SUM" in FORMULAE) # True
print("PI" in FORMULAE) # True
print("sum" in FORMULAE) # False
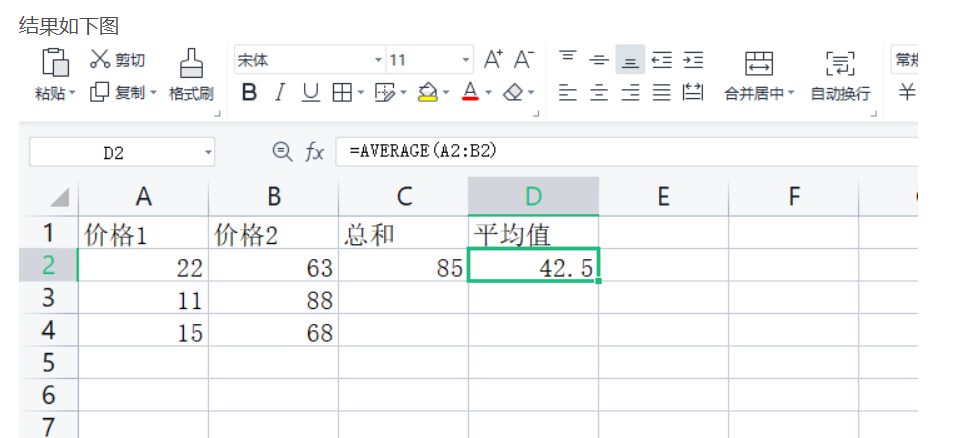
使用公式很简单,你只要记得公式名和用法,直接像在Excel那样输入即可,例如,下面的求和、求平均值
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws.append(["价格1", "价格2", "总和", "平均值"])
ws.append([22, 63])
ws.append([11, 88])
ws.append([15, 68])
ws["c2"] = "=SUM(A2,B2)" # 求和
ws["d2"] = "=AVERAGE(A2:B2)" # 求平均值
wb.save("test.xlsx")
5.2 翻译公式
过Excel的同学都知道,当某个单元格使用了公式,可以通过拖动填充柄的方式快速复制上一个公式进行填充,在openpyxl做法如下
from openpyxl import Workbook
from openpyxl.formula.translate import Translator
wb = Workbook()
ws = wb.active
ws.append(["价格1", "价格2", "总和", "平均值"])
ws.append([22, 63])
ws.append([11, 88])
ws.append([15, 68])
ws["c2"] = "=SUM(A2,B2)"
ws["d2"] = "=AVERAGE(A2:B2)"
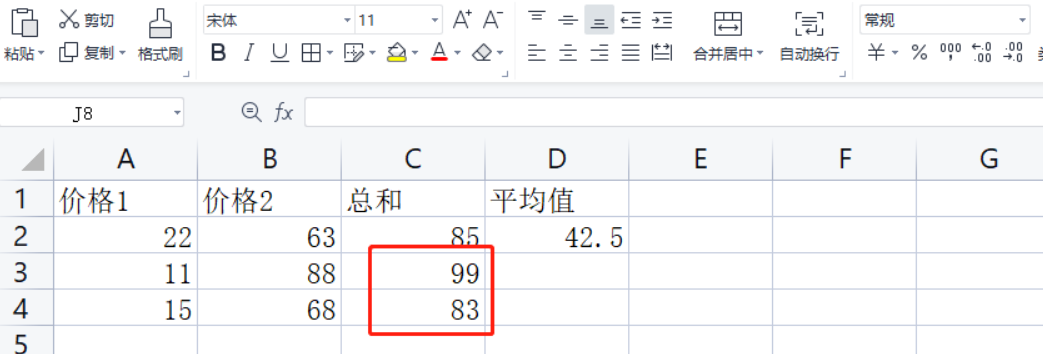
# C3、C4使用上面的C2的求和公式
ws["C3"] = Translator(formula="=SUM(A2,B2)", origin="C2").translate_formula("C3")
ws["C4"] = Translator(formula="=SUM(A2,B2)", origin="C2").translate_formula("C4")
wb.save("test.xlsx")
结果如下图
当然,既然是重复操作,我们要使用优雅的循环写法
from openpyxl import Workbook
from openpyxl.formula.translate import Translator
....
ws["c2"] = "=SUM(A2,B2)"
ws["d2"] = "=AVERAGE(A2:B2)"
# C3、C4使用上面的C2的求和公式
for cell in ws["C3:C4"]:
# ws["C3"] = Translator(formula="=SUM(A2,B2)", origin="C2").translate_formula("C3")
cell[0].value = Translator(formula="=SUM(A2,B2)", origin="C2").translate_formula(cell[0].coordinate)
wb.save("test.xlsx")
6. 插入图标(例入折线图)
6.1 图表
Excel支持的图表类型还挺多的,包括柱状图、折线图、饼图、雷达图等等,2D和3D都有,而且支持很多自定义配置,例如颜色、大小、位置等。因为内容较多,所以我这里只举例折线图,其他图表类型大家可以参考官方文档
https://openpyxl.readthedocs.io/en/stable/charts/introduction.html
6.2折线图代码
from openpyxl import Workbook
from openpyxl.chart import LineChart, Reference
wb = Workbook()
ws = wb.active
# 准备数据
rows = [
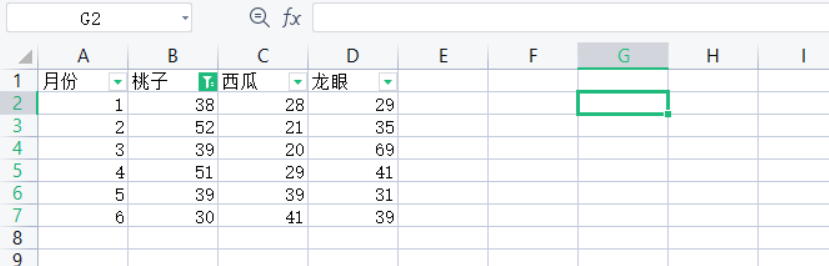
['月份', '桃子', '西瓜', '龙眼'],
[1, 38, 28, 29],
[2, 52, 21, 35],
[3, 39, 20, 69],
[4, 51, 29, 41],
[5, 29, 39, 31],
[6, 30, 41, 39],
]
for row in rows:
ws.append(row)
# 创建图表
c1 = LineChart()
c1.title = "折线图" # 标题
c1.style = 13 # 样式
c1.y_axis.title = '销量' # Y轴
c1.x_axis.title = '月份' # X轴
# 选择数据范围
data = Reference(ws, min_col=2, min_row=1, max_col=4, max_row=7)
c1.add_data(data, titles_from_data=True)
# 线条样式
s0 = c1.series[0]
s0.marker.symbol = "triangle" # triangle为三角形标记, 可选circle、dash、diamond、dot、picture、plus、square、star、triangle、x、auto
s0.marker.graphicalProperties.solidFill = "FF0000" # 填充颜色
s0.marker.graphicalProperties.line.solidFill = "0000FF" # 边框颜色
# s0.graphicalProperties.line.noFill = True # 改为True则隐藏线条,但显示标记形状
s1 = c1.series[1]
s1.graphicalProperties.line.solidFill = "00AAAA"
s1.graphicalProperties.line.dashStyle = "sysDot" # 线条点状样式
s1.graphicalProperties.line.width = 80000 # 线条大小,最大20116800EMUs
s2 = c1.series[2] # 采用默认设置
s2.smooth = True # 线条平滑
ws.add_chart(c1, "A8") # 图表位置
wb.save("line.xlsx")
大概过程是,创建一个图表(Chart)–指定数据范围(Reference)–设置系列(series)样式–添加到工作表中
7.过滤和排序
7.1过滤和排序
如果你想对表格进行过滤或排序,openpyxl有提供对应的设置,但是,只是添加过滤排序选项,并不会真的操作数据,如果想要操作,还是得在Excel中手动点击
2.代码
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
# 准备数据
rows = [
['月份', '桃子', '西瓜', '龙眼'],
[1, 38, 28, 29],
[2, 52, 21, 35],
[3, 39, 20, 69],
[4, 51, 29, 41],
[5, 39, 39, 31],
[6, 30, 41, 39],
]
for row in rows:
ws.append(row)
ws.auto_filter.ref = "A1:D7" # 选择数据范围
ws.auto_filter.add_filter_column(1, ["39", "29", "30"]) # 选择第2列为过滤数据(下标从0开始),并勾选需要过滤的数据项
ws.auto_filter.add_sort_condition("C2:C7", True) # 设置排序范围,第二个参数是是否倒序,默认为否
wb.save("./openpyxl/test.xlsx")
效果如下
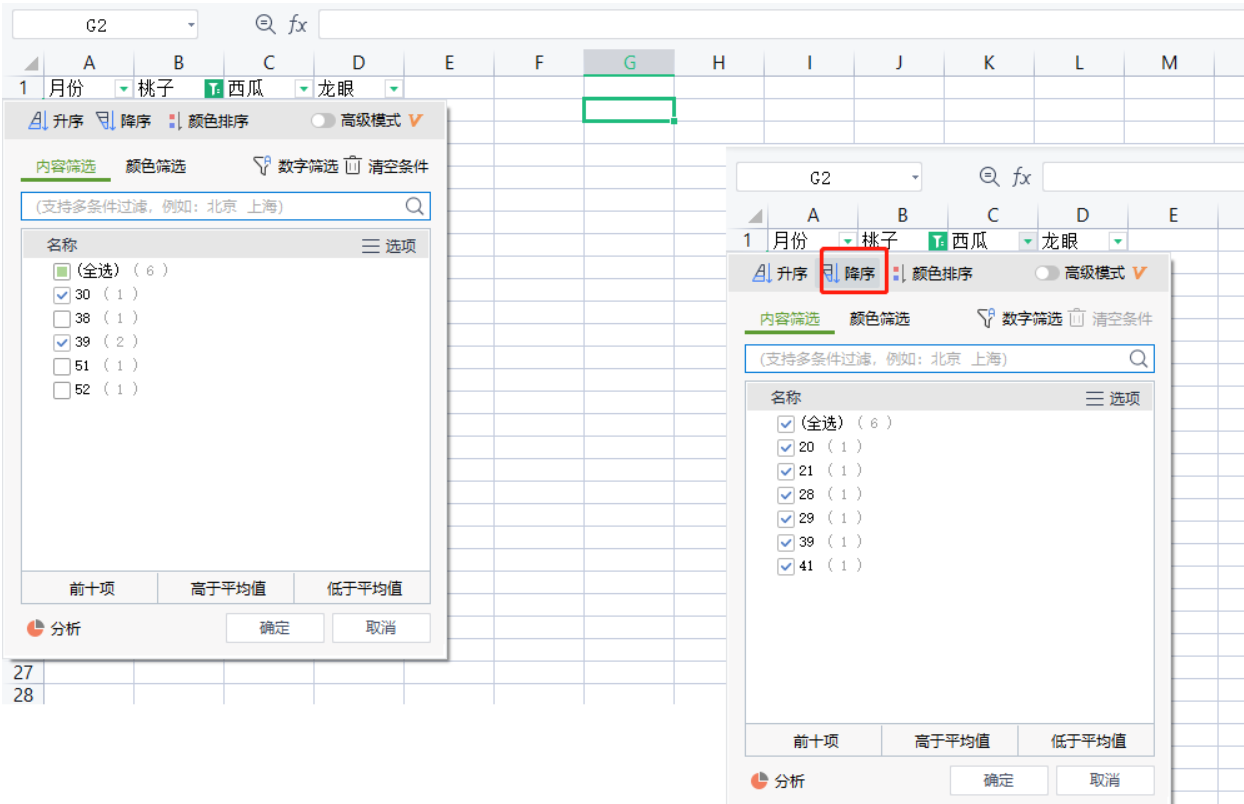
7.2 pandas排序
虽然openpyxl不能真的实现排序,但是我们可以借助超级强大的pandas轻松实现排序
import pandas as pd
# 读取上一步保存的Excel文件
df = pd.read_excel("./openpyxl/test.xlsx", sheet_name="Sheet")
df_value = df.sort_values(by=["桃子", "西瓜"], ascending=False) # 如果"桃子"数据相同再按照"西瓜"进行排列
# 保存文件
writer = pd.ExcelWriter('./openpyxl/sort_file.xlsx')
df_value.to_excel(writer, sheet_name='Sheet1', index=False)
writer.save()
8. 只读模式、只写模式
说明:
前面我们使用的normal模式进行读写Excel文件,这是一种兼顾读写相对比较平衡的模式,但是,数据加载到内存占用的资源是比较大的,大概是文件的50倍,如果你的Excel文件本身就10M,加载之后程序
需要占用0.5G内存,这很不划算(大内存电脑请自动忽略),所以我们需要考虑是不是可以选择只读或只写模式以便提高性能
8.1只读模式
只读模式,如果你需要读取很大的Excel文件,但是又不改变和保存,例如只读取数值用于其他数据分析,这时候我们完全可以使用只读模式提供性能
from openpyxl import load_workbook
# 加载Excel文件时使用read_only指定只读模式
wb = load_workbook(filename='large_file.xlsx', read_only=True)
ws = wb['big_data']
# 可以正常读取值
for row in ws.rows:
for cell in row:
print(cell.value)
# 注意:读取完之后需要手动关闭避免内存泄露
wb.close()
load_workbook参数说明:
定义:
def load_workbook(filename, read_only=False, keep_vba=KEEP_VBA, data_only=False, keep_links=True)
参数:
read_only:是否只读,默认False
keep_vba:是否使用VBA编程,默认False
data_only:是否只加载数据值,即丢弃公式、排序等操作,默认False
keep_links:是否保留超链接,默认True
8.2 只写模式
如果文件是以写为主,可以在创建工作簿的时候指定为只写模式以便提高性能,不管文件有多大,都可以把内存保持在10M以下
from openpyxl import Workbook
from openpyxl.cell import WriteOnlyCell
from openpyxl.comments import Comment
from openpyxl.styles import Font
wb = Workbook(write_only=True) # 创建工作簿时指定只写模式
ws = wb.create_sheet() # 需要通过create_sheet创建一个sheet
# 可以正常保存数据
for _ in range(100):
ws.append([i for i in range(200)]) # 只能通过append写
# 如果需要保留公式、注释等操作,可以使用WriteOnlyCell
cell = WriteOnlyCell(ws, value="冰冷的希望")
cell.font = Font(name='黑体', size=15)
cell.comment = Comment(text="这是注释", author="pan")
ws.append([cell])
wb.save('openpyxl/test.xlsx')
只写模式注意点:
1.需要通过create_sheet()创建表
2.只能通过append()增加数据,不能通过cell或iter_rows()
3.wb.save()之后不能再修改,否则抛出WorkbookAlreadySaved异常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号