selenium4框架学习
selenium4框架学习
https://blog.csdn.net/qq_45158700/article/details/135363339
Selenium with Python中文翻译文档:https://selenium-python-zh.readthedocs.io/en/latest/
下面链接中为103.0.5060.53版本的浏览器和对应的chromedriver
链接:https://pan.baidu.com/s/1rMniL41_L05ucgwGPzhn2A
提取码:6byo
谷歌浏览器和驱动历史版本下载网址_关闭浏览器更新功能:https://www.bilibili.com/read/cv22587648/
安装旧版本chrome 浏览器方法_chrome旧版本-CSDN博客
1.selenium编写第一个脚本
#需求:访问bibi网址,输入selenium框架学习点击搜索
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#定义一个browser的变量,用来接收实例化后的浏览器
browser = webdriver.Chrome()
#使用get方法,访问网址
browser.get("https://www.bilibili.com")
# 1.找到输入框的位置,输入selenium框架学习
browser.find_element(By.CLASS_NAME,'nav-search-input').send_keys("selenium框架学习")
# 2. 找到搜索框的位置,点击搜索
browser.find_element(By.CLASS_NAME,'nav-search-btn').click()
time.sleep(5)
browser.close()
# browser.get("https://im.qq.com/index/")
# browser.find_element_by_id("loginInfo")
从0-1搭建Python+Selenium4自动化测试框架 (yuque.com)
其工作基本流程为:
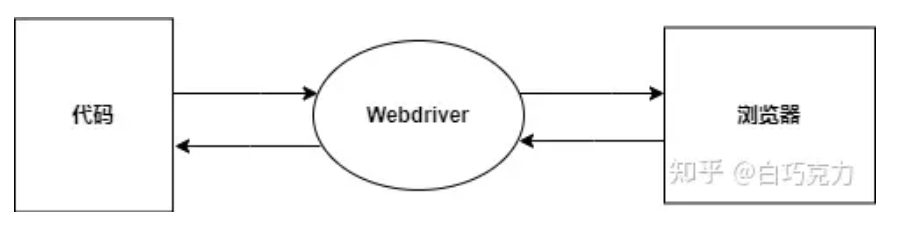
Webdriver接收到代码后,经过处理来发送给浏览器,浏览器根据处理后的代码执行对应的操作,浏览器执行后完把执行结果返回给Webdriver,Webdriver将执行结果处理并返回给代码展示出来。
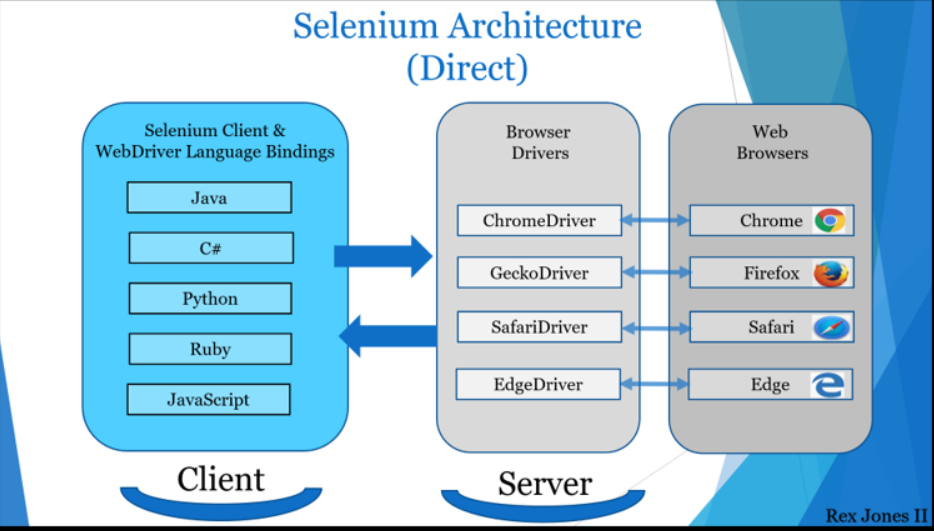
selenium源码解析
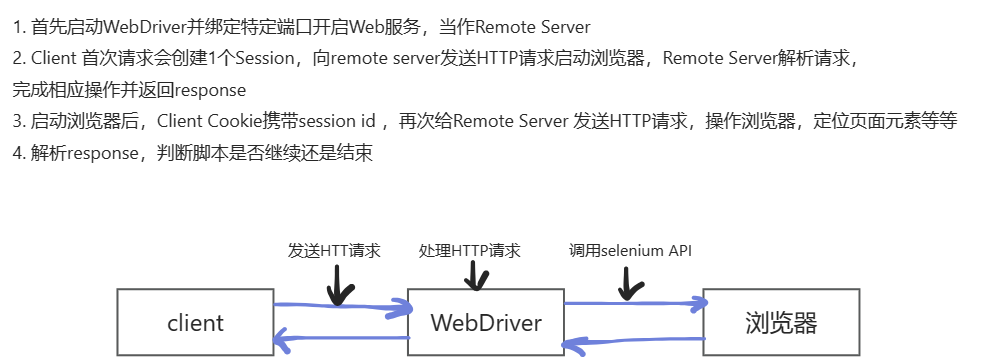
2.元素定位
设置好窗口后,想要执行自动化操作,需要定位页面源码中显示的所有HTML所包含的元素内容。
我们有八种元素定位的方法:id、name、class、tag_name、xpath、css_selector、link_text、partial_link_text。
selenium4新版本使用指南:https://zhuanlan.zhihu.com/p/648948497
selenium4自动化测试八大定位高级用法:https://www.bilibili.com/read/cv23264252/
Selenium4Web自动化2-页面元素定位:https://www.cnblogs.com/cekailsf/p/16800385.html
Selenium4自动化框架(超级详细):https://zhuanlan.zhihu.com/p/632399597
2.1 id、name、class_name定位
在一般情况下,页面源码中的id都是唯一的,所以只要知道页面元素中的id,就可以定位到该元素,但name、class值可以有重复,所以要注意页面元素中的name、class值有没有重复,假如有的话,selenium默认会返回第一个name或class的元素,假设有如下页面元素标签:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
我们只需要使用find_element()方法来定位该元素,该方法语法格式如下:
from selenium.webdriver.common.by import By
driver.find_element(By.ID,'元素id')
driver.find_element(By.name,'元素name')
driver.find_element(By.CLASS_NAME,'元素class')
示例代码如下:
from selenium.webdriver.common.by import By
driver.find_element(By.ID,'kw')
driver.find_element(By.name,'wd')
driver.find_element(By.CLASS_NAME,'s_ipt')
2.2 tag_name定位
tag_name定位是通过标签名来定位,例如div、a、input标签等等,当页面中存在多个相同的标签时,默认返回第一个标签元素,其语法格式如下:
from selenium.webdriver.common.by import By
driver.find_element(By.TAG_NAME,"标签名")
示例代码如下:
driver.find_element(By.TAG_NAME,"input") #这样就可以定位到input标签了
2.3 link_text、partial_link_text定位
通过链接文本定位: link_text:使用链接的全部文字定位元素 ,partial_link_text: 通过链接部分文本定位
link_text、partial_link_text都是用来定位标签内的文本,其中link_text必须指明标签内的全部文本,而partial_link_text只需要指定标签内部分文本即可定位,其语法格式如下:
假设有如下标签:
<div class="myclass">自动化测试工具selenium</div>
from selenium.webdriver.common.by import By
driver.find_element(By.LINK_TEXT,'标签内全部文本')
driver.find_element(By.PARTIAL_LINK_TEXT,'标签内部分文本')
示例代码如下:
from selenium.webdriver.common.by import By
driver.find_element(By.LINK_TEXT,'自动化测试工具selenium')
driver.find_element(By.PARTIAL_LINK_TEXT,'自动化')
2.4 xpath定位
xpath是XML路径语言,是XML文档中定位元素的语言,常用的规则如下表所示:
| 表达式 | 描述 |
|---|---|
| nodename | 获取该节点的所有子节点 |
| / | 从当前节点获取直接子节点 |
| // | 从当前节点获取子孙节点 |
| * | 获取当前节点 |
| ** | 获取当前节点的父节点 |
| @ | 选取属性 |
| [] | 添加筛选条件 |
在Selenium自动化测试中,使用xpath定位元素语法格式如下:
例如:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH,"xpath规则")
示例代码如下:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH,'//input[@id="kw"]') #定位百度的输入框
//title[@lang='eng'] #其表示选择所有名称为title,同时属性lang的值为eng的节点。
使用xpath定位时,还可以使用运算符来增加定位的准确性,运算符如下表所示:
| 运算符 | 描述 |
|---|---|
| or | 或运算 |
| and | 与运算 |
| mod | 计算除法的余数 |
| | | 计算两个节点集 |
| +、-、*、div | 加法、减法、乘法、除法 |
| =、!=、<、<=、>、>= | 等于、不等于、小于、小于等于、大于、大于等于 |
示例代码如下:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH,'//input[@id="kw" and @name="wd"]') #这样就可以定位到百度输入框的元素了。
2.5 css选择器定位
css选择器是用于查找HTML元素,定位速度比xpath快,css选择器常用语法表达式如下表:
| 表达式 | 例子 | 描述 |
|---|---|---|
| # | #myid | 选择id为myid的元素 |
| . | .myclass | 选择class为myclass的元素 |
| * | * | 选择所有元素 |
| element | div | 选择div标签元素 |
| > | div>li | 选择div的所有li元素 |
| + | div+li | 选择同一级中在div之后的所有li元素 |
| [=] | type='mytest' | 选择type值为mytest的元素 |
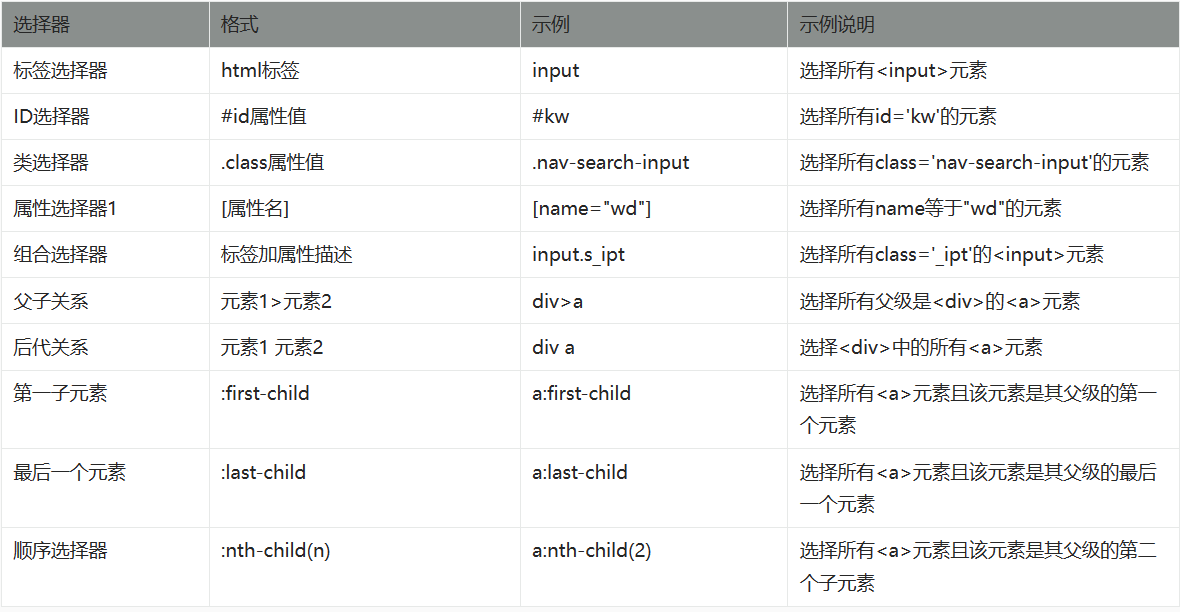
在Selenium自动化定位中,使用css选择器语法格式如下:
from selenium.webdriver.common.by import By
driver.find_element(By.CSS_SELECTOR,"css选择")
示例代码如下:
driver.find_element(By.CSS_SELECTOR,"#kw")
根据标签属性定位
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.find_element(By.CSS_SELECTOR, 'a[href="http://image.baidu.com/"]').click()
# 模糊匹配-包含
driver.find_element(By.CSS_SELECTOR, 'a[href*="image.baidu.com"]').click()
# 模糊匹配-匹配开头
driver.find_element(By.CSS_SELECTOR, 'a[href^="http://image.baidu"]').click()
# 模糊匹配-匹配结尾
driver.find_element(By.CSS_SELECTOR, 'a[href$="image.baidu.com/"]').click()
定位子元素
一般根据最近一个id属性往下找,可以根据class或者标签。
#s-top-left > a
:nth-child(3)代表第几个子元素,下标从1开始
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
# 百度首页新闻,以下三种方式皆可
driver.find_element(By.CSS_SELECTOR, 'div.s-top-left-new.s-isindex-wrap a' ) # 根据class
driver.find_element(By.CSS_SELECTOR, 'div#s-top-left a') # 根据id
driver.find_element(By.CSS_SELECTOR, '#s-top-left a') # 简写
# 百度首页地图,以下2种方式皆可
driver.find_element(By.CSS_SELECTOR, '#s-top-left a:nth-child(3)')
driver.find_elements(By.CSS_SELECTOR, '#s-top-left a')[2]
# a:first-child 第一个标签
driver.find_element(By.CSS_SELECTOR, '#s-top-left a:first-child')
# a:last-child 最后一个标签
driver.find_element(By.CSS_SELECTOR, '#s-top-left a:last-child')
2.6 冻结界面
比如在悬停时,将页面冻结,然后可以选取悬停中的信息 (冻住之后就能看其路径了)
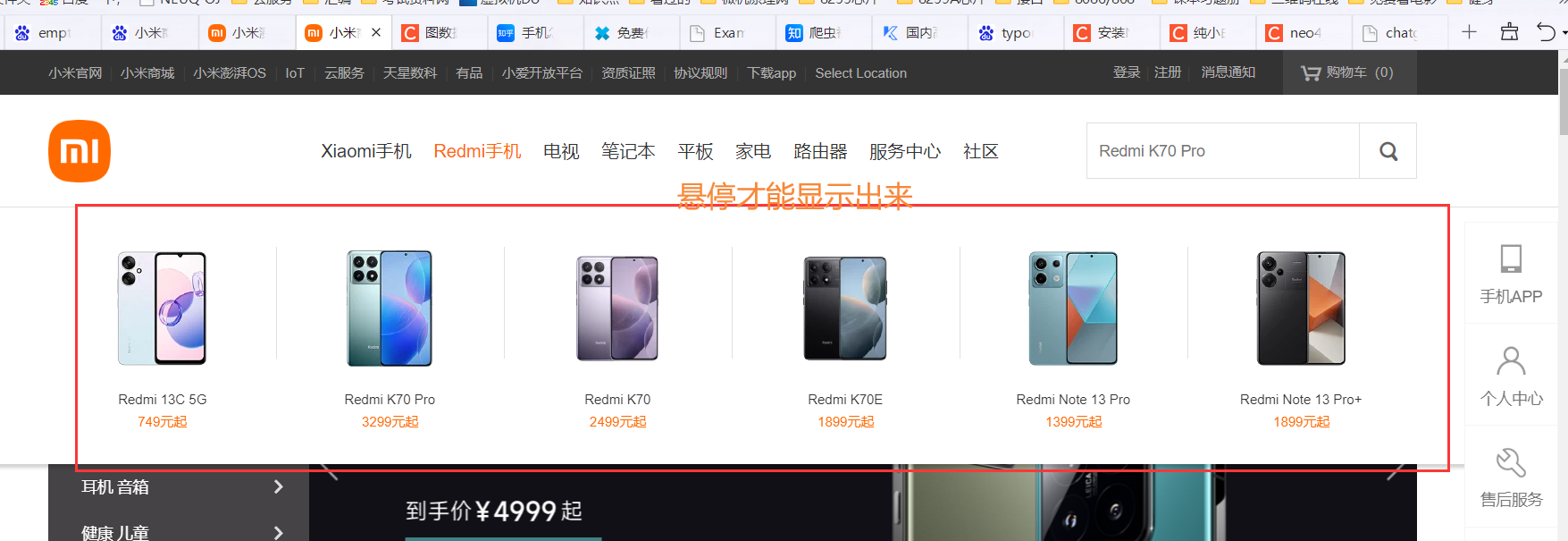
在 开发者工具栏 console 里面 执行如下js代码
setTimeout(function(){debugger},5000)
代码的意思是: 表示在5000毫秒后,执行debugger命令,执行该命令后浏览器会进入debug状态。 debug状态有个特性,界面被冻住,不管我们怎么点击界面都不会触发事件。
2.7 单选框radio定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
web=webdriver.Chrome()
web.get("https://www.iviewui.com/view-ui-plus/component/form/radio")
web.maximize_window()
time.sleep(2)
#获取出来后,选取第三个按钮
web.find_elements(By.XPATH,'//span[@class="ivu-radio"]/input[@class="ivu-radio-input"]')[3].click()
print("执行完毕")
time.sleep(2)
web.find_elements(By.XPATH,'//input[@class="ivu-radio-input" and @type="radio"]')[1].click()
time.sleep(2)
web.find_elements(By.XPATH,'//input[@class="ivu-radio-input" and @type="radio"]')[2].click()
time.sleep(2)
web.find_elements(By.XPATH,'//input[@class="ivu-radio-input" and @type="radio"]')[3].click()
time.sleep(2)
#直接选取 Android 进行点击
web.find_element(By.XPATH,'//span[text()="Android"]').click()
time.sleep(2)
web.find_element(By.XPATH,'//span[text()="Windows"]').click()
print("-----")
time.sleep(2)
web.quit()
2.8 CheckBox多选框定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
web=webdriver.Chrome()
web.get("https://www.iviewui.com/view-ui-plus/component/form/checkbox")
time.sleep(2)
web.find_element(By.XPATH,'//span[text()="Facebook"]').click()
time.sleep(2)
web.find_element(By.XPATH,'//span[text()="香蕉"]').click()
time.sleep(2)
web.find_element(By.XPATH,'//span[text()="西瓜"]').click()
time.sleep(2)
print("执行完毕")
web.quit()
2.9 select 下拉框定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
web=webdriver.Chrome()
web.get("https://sahitest.com/demo/selectTest.htm")
time.sleep(2)
#获取下拉框元素
select1 = web.find_element(By.ID,'s1')
#实例化select类,将select元素对象传进去
s1 = Select(select1)
#根据option的value进行选择
s1.select_by_value("47")
time.sleep(2)
#根据index下标获取,从0开始
s1.select_by_index(3)
time.sleep(2)
#根据实际看到的内容进行选择
s1.select_by_visible_text("Mail")
time.sleep(2)
web.quit()
2.10 级联选择器定位
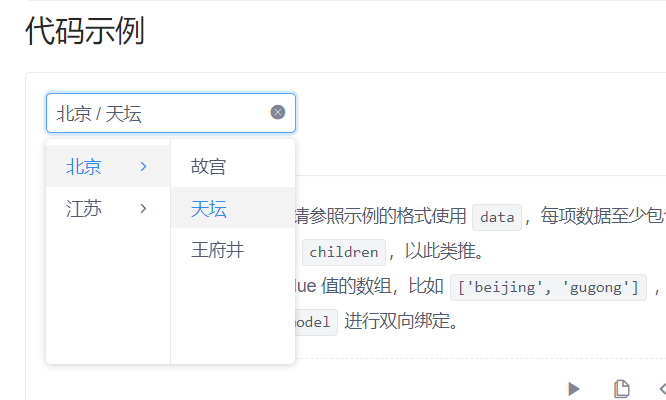
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
web=webdriver.Chrome()
web.get("https://www.iviewui.com/view-ui-plus/component/form/cascader")
time.sleep(2)
web.find_element(By.XPATH,'//input[@class="ivu-input ivu-input-default"]').click()
time.sleep(2)
#获取北京
web.find_element(By.XPATH,'//li[contains(text(),"北京")]').click()
time.sleep(2)
#获取天坛
web.find_element(By.XPATH,'//li[contains(text(),"天坛")]').click()
time.sleep(2)
web.quit()
2.11 日期选择器定位
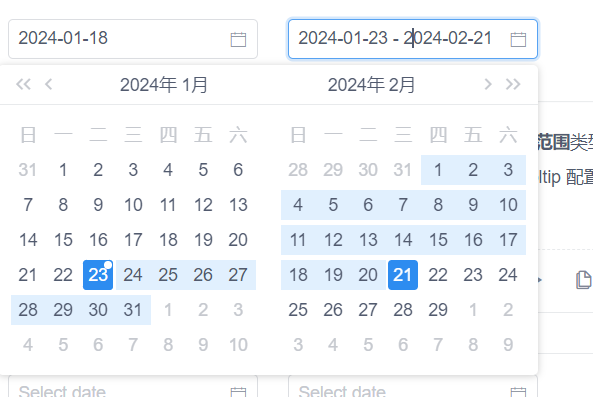
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
web=webdriver.Chrome()
web.get("https://www.iviewui.com/view-ui-plus/component/form/date-picker")
time.sleep(2)
web.find_element(By.XPATH,'//input[@class="ivu-input ivu-input-default ivu-input-with-suffix"]').send_keys("2024-01-18")
time.sleep(2)
web.find_elements(By.XPATH,'//input[@class="ivu-input ivu-input-default ivu-input-with-suffix"]')[1].send_keys("2024-01-23 - 2024-02-21")
time.sleep(2)
web.quit()
2.12 文件上传
定义一个获取文件相对路径的函数
import os
#print(os.path.realpath(__file__)) #获取文件的绝对路径
#print(os.path.dirname(os.path.realpath(__file__))) #获取文件的路径的上一级目录
#print(os.path.dirname(os.path.dirname(os.path.realpath(__file__)))) #获取文件的路径的上一级目录
#print(os.path.dirname(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))) #获取文件的路径的上一级目录
#print(os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.path.realpath(__file__)))),"file","7.png")) #file文件中的7.png图片
#print("-----------")
#定义一个获取文件相对路径的函数
def get_logo_path():
path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.path.realpath(__file__)))),"file","7.png")
return path
print(get_logo_path()) #调用函数
上传方法:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from get_filepath import get_logo_path
#获取上传文件路径
path = get_logo_path()
web=webdriver.Chrome()
#获取input文件上传元素
web.get("https://sahitest.com/demo/php/fileUpload.htm")
upload = web.find_element(By.ID,'file')
time.sleep(2)
# format函数 是一种字符串格式化的方法,
upload.send_keys(r"{}".format(path)) #将获取到的文件路径进行上传
time.sleep(2)
web.find_element(By.NAME,'submit').click()
time.sleep(3)
web.quit()
2.13 文件下载
import time
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
path = "D:\pythondemo\efile"
if os.path.exists(path):
os.remove(path)
chromeOptions = webdriver.ChromeOptions()
prefs={"download.default_directory":"D:\pythondemo\efile"}
chromeOptions.add_experimental_option("prefs",prefs)
web=webdriver.Chrome(chromeOptions)
web.get("https://registry.npmmirror.com/binary.html?path=chromedriver/")
time.sleep(2)
web.find_element(By.XPATH,'/html/body/table/tbody/tr[5]/td[2]/a').click()
time.sleep(2)
web.find_element(By.XPATH,'/html/body/table/tbody/tr[8]/td[2]/a').click()
time.sleep(2)
web.quit()
2.14 iframe框架切换
https://www.cnblogs.com/ckxingchen/p/17057065.html
frame是网页开发中常见应用。例如页面布局、局部刷新,页面分割,都是frame的用途表现,使用frame会给用户带来非常舒适的使用感受。frame包括(frameset标签、frame标签、iframe标签)
frameset和frame结合一起使用,可以对页面进行分割。例如sahitest的Frames Test。对页面进行上下切割,并嵌套html页面iframe 是个内联框架,是在页面里生成个内部框架。可以嵌套多个html页面。大多网页使用的是iframe框架。比如163邮箱。
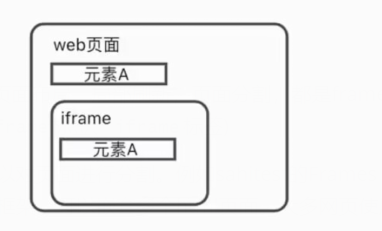
示例地址:http://sahitest.com/demo/iframesTest.htm
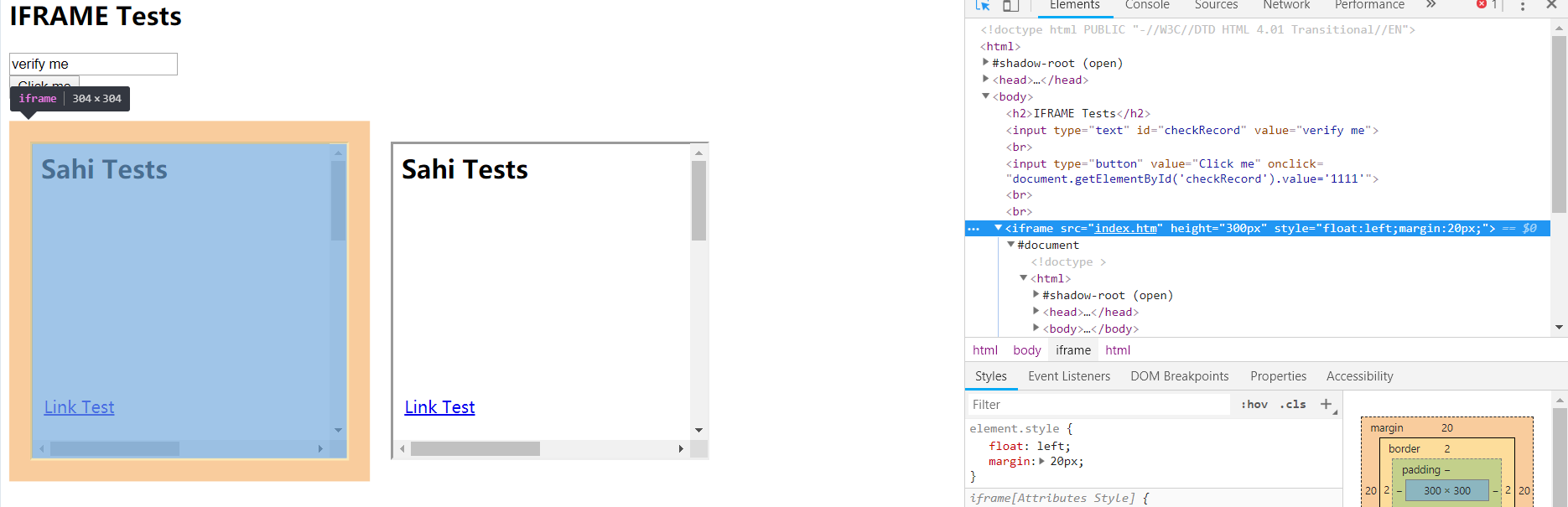
说明:图中阴影部分就是iframe,可以理解为页面中嵌套着一个小页面,我们如果要定位”Link Test“按钮,必须先切换到小页面才能定位,如果不切换则会报错元素未找到。
切换iframe的方法为: driver.switch_to.frame(), frame()中参数可以为id,name或者index,也可以为iframe元素
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
#请求某个url
driver.get('http://sahitest.com/demo/iframesTest.htm')
time.sleep(3)
#frame()中参数可以为id,name或者index
#用下标进行定位 切换iframe
driver.switch_to.frame(0) #表示选中第一个iframe框架
#点击想要点击的内容
# driver.find_element(By.XPATH,'/html/body/table/tbody/tr/td[4]/a[1]').click()
driver.find_element(By.XPATH,'/html/body/table/tbody/tr/td[1]/a[6]').click()
#返回上一次点击的iframe(切换到上一级)
driver.switch_to.parent_frame()
#切换到主界面
# driver.switch_to.default_content()
time.sleep(1)
driver.find_element(By.ID,'checkRecord').clear()
time.sleep(1)
driver.find_element(By.ID,'checkRecord').send_keys("你好")
time.sleep(2)
driver.quit()
------------------------------------------------------
#处理 iframe的话,必须先拿到iframe,再切换 视角到iframe,再然后可以拿到iframe中的数据
#切换到iframe
iframe = driver.find_element('//*[@id="mplay]')
driver.switch_to.frame(iframe) #切换到iframe里面
# 跳出iframe
driver.switch_to.parent_frame()
2.15 窗口之间的切换(handler切换)
什么是handler?
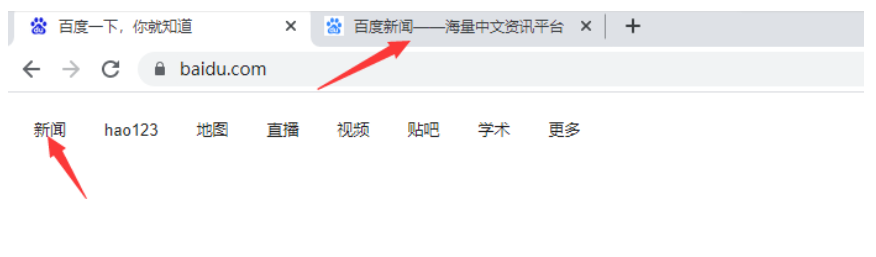
说明:当我们点击百度首页的新闻按钮时,浏览器会出现一个新的窗口。我们如果想操作百度新闻页面的元素,必须要从百度首页的窗口切换到百度新闻页的窗口,否则无法获取到新窗口中的元素。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
#请求某个url
driver.get('https://www.baidu.com/')
time.sleep(1)
#点击地图按钮
driver.find_element(By.XPATH,'//a[text()="地图"]').click()
#1.获取当前浏览器的全部窗体 (获取当前打开的所有窗口句柄)
all_handles=driver.window_handles[-1]
#2.切换到最新打开的窗体
driver.switch_to.window(all_handles)
time.sleep(1)
#在新窗口中 输入内容
driver.find_element(By.XPATH,'//*[@id="sole-input"]').send_keys("北京")
time.sleep(1)
#在新窗口中进行查询
driver.find_element(By.XPATH,'//*[@id="search-button"]').click()
time.sleep(1)
# 切换回原来的窗口 ,并进行操作
driver.switch_to.window(driver.window_handles[0])
time.sleep(1)
driver.find_element(By.XPATH,'//*[@id="kw"]').send_keys("北京")
time.sleep(4)
driver.quit()
3. 浏览器操作
浏览器操作常用的操作有:
- 获取浏览器信息,导航;
- 处理警告框;
- 添加、获取、删除Cookies;
- 大小、切换窗口。
3.1 获取信息
获取浏览器信息主要有获取标签、当前URL,其方法分别如下所示:
driver.title # 获取浏览器当前页面的标签
driver.current_url # 获取浏览器当前地址栏的URL
driver.page_source # 获取当前html源码
driver.name # 获取浏览器名称(chrome)
driver.get_window_rect() # 获取浏览器尺寸,位置
driver.get_window_position() # 获取浏览器位置(左上角)
3.2 导航
导航最常用的操作是打开、前进、后退和刷新页面,其实现方法分别为:
driver.get(url) # 打开网页
driver.back() # 返回上一个页面(回退操作)
driver.forward() # 回到下一个页面(前进操作)
driver.refresh() # 刷新本页面
3.3 警告框
有三种警告框:Alerts警告框、Confirm确认框、Prompt 提示框。
Alerts警告框:其显示一条自定义消息及关闭该警告框的按钮,如下图所示:
Confirm确认框:其显示一条自定义消息及确认和取消该警告框的按钮,如下图所示:
Prompt 提示框:其显示一条自定义消息、输入文本框及确认和取消该警告框的按钮,如下图所示:
处理这些警示框,首先使用switch_to.alert自动定位当前警示框,再使用text、accpet、dismiss、send_keys等方法进行操作操作,其中:
- text:获取警示框内的文字;
- accpet:接受(确认)弹窗内容;
- dismiss:解除(取消)弹窗;
- send_keys: 发送文本至警告框。
# Alerts警示框、Confirm确认框、Prompt提示框示例代码如下:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.selenium.dev/zh-cn/documentation/webdriver/interactions/alerts/")
driver.find_element('link text','查看样例警告框').click()
sleep(5)
alert = driver.switch_to.alert
alert.accept()
sleep(5)
driver.find_element('link text','查看样例警告框').click()
#例代码如下:
Confirm=driver.switch_to.alert
Confirm.dismiss()
3.4 添加、获取、删除Cookies
Cookies主要用于识别用户并加载存储的信息,有些情况,我们需要携带Cookies才可以继续访问浏览器或者浏览网页的更多信息,在Selenium自动化测试中,我们通过使用如下方法来添加、获取、删除Cookies,
from selenium import webdriver
driver = webdriver.Chrome()
driver.add_cookie(Cookies值) # 添加Cookies
driver.get_cookie(Cookies名称) # 获取单个Cookies
driver.get_cookies() # 获取全部Cookies
driver.delete_cookie(Cookies名称) # 删除单个Cookies
driver.delete_all_cookies() # 删除全部Cookies
#注意:添加Cookie仅接受一组已定义的可序列化JSON对象。
#示例代码 实现了添加、获取、删除Cookies值了。
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
sleep(1)
driver.add_cookie({'name':'mycookies','value':'123456'}) # 添加名为mycookies的cookies,其值为123456
print(driver.get_cookie('mycookies')) # 获取名为mycookies的cookies信息
print(driver.get_cookies()) # 获取全部cookies的信息
driver.delete_cookie('mycookies') # 删除名为mycookies的信息
print(driver.get_cookies()) # 获取全部cookies的信息
driver.delete_all_cookies() # 删除全部cookies的信息
print(driver.get_cookies()) # 获取全部cookies的信息
3.5 浏览器窗口大小
webdriver提供了set_window_size(宽, 高)来修改自动化测试时浏览器启动的窗口大小,示例代码如下:
from selenium import webdriver #导入模块
driver = webdriver.Chrome() #启动浏览器驱动
driver.get('https://www.baidu.com')
driver.set_window_size(1500, 800) #调整浏览器高为800,宽为1500
也可以使用maximize_window()方法使窗体最大化,示例代码如下:
from selenium import webdriver #导入模块
driver = webdriver.Chrome() #启动浏览器驱动
driver.get('https://www.baidu.com')
driver.maximize_window() #最大化窗口
3.6 浏览器窗口切换
在进行浏览器操作时,打开了一个新的标签页后,代码监控的浏览器标签页并不是最新打开的标签页,示例代码如下:
在进行浏览器操作时,打开了一个新的标签页后,代码监控的浏览器标签页并不是最新打开的标签页,示例代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('https://blog.csdn.net/')
el=driver.find_element(By.ID,'toolbar-search-input')
el.send_keys('Selenium')
bt=driver.find_element(By.ID,'toolbar-search-button').click()
sleep(2)
print(driver.title) # 输出标签页标题
driver.quit()
#运行上面的代码,终端输出的内容是:
CSDN博客-专业IT技术发表平台
但最新的标签页标题为:Selenium- CSDN搜索。
这时我们需要获取打开的窗口句柄,并切换到最新的窗口,示例代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('https://blog.csdn.net/')
el=driver.find_element(By.ID,'toolbar-search-input')
el.send_keys('Selenium')
bt=driver.find_element(By.ID,'toolbar-search-button').click()
windows = driver.window_handles # 获取浏览器打开的窗口句柄
driver.switch_to.window(windows[-1]) # 切换到最新的窗口
sleep(2)
print(driver.title) # 输出标签页标题
driver.quit()
#运行结果:
Selenium- CSDN搜索。
注意: 获取窗口句柄的返回值类型为数组,而且最新的窗口句柄放在数组最后面,所以通过-1下标来获取最新的句柄。
3.7 浏览器窗口新建
当我们需要新建一个页面方法其他URL链接时,可以使用new_window()方法,示例代码如下:
from selenium import webdriver
from time import sleep
driver=webdriver.Chrome()
driver.get('https://cn.bing.com/')
driver.switch_to.new_window() # 新建标签页
driver.get('https://www.baidu.com/')
sleep(5) # 休眠5秒
driver.quit() # 关闭浏览器并释放进程资源
3.8 浏览器窗口截图
我们可以通过get_screenshot_as_file()方法对打开的标签页进行截图保存,示例代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.get_screenshot_as_file('screenshot.png')
driver.quit()
或者
driver.get_screenshot_as_png('...')
driver.get_screenshot_as_base64('...')
3.9 关闭浏览器释放资源
在完成自动化操作后,需要关闭浏览器并释放资源,示例代码如下:
driver.quit() # 关闭所有标签页
driver.close() # 关闭当前标签页
关闭当前标签页时,要注意切换到你想要关闭的标签页。
4. 鼠标操作
常用的鼠标操作方法如下:
| 方法 | 描述 |
|---|---|
| click() | 单击左键 |
| context_click() | 单击右键 |
| double_click() | 双击 |
| drag_and_drop() | 拖动 |
| move_to_element() | 鼠标悬停 |
| perform() | 执行所有ActionChains中存储的动作 |
除了单击左键,上面的方法需要用到ActionChains方法,而且需要使用perform方法执行ActionChains的动作。
4.1 单击左键
单击左键使用click()方法即可,示例代码如下:
bt=driver.find_element(By.ID,'su').click() # 单击左键
4.2 单击右键
单击右键使用context_click()方法即可,示例代码如下:
from selenium.webdriver import ActionChains
bt=driver.find_element(By.ID,'su') # 定位元素
ActionChains(driver).context_click(bt).perform() # 使用ActionChains方法调用context_click方法实现单击右键
4.3 双击左键
双击左键使用double_click()方法即可,示例代码如下:
# 定位搜索按钮
button = driver.find_element('选择器','元素位置')
# 执行双击动作
ActionChains(driver).double_click(button).perform()
4.4 拖动操作
拖动鼠标使用drag_and_drop()方法,该方法需要传递两个参数:
- source:拖动的元素;
- target:拖到目标位置;
示例代码如下:
# 定位要拖动的元素
source = driver.find_element('选择器','xxx')
# 定位目标元素
target = driver.find_element('选择器','')
# 执行拖动动作
ActionChains(driver).drag_and_drop(source, target).perform()
4.5 悬停操作
鼠标悬停使用move_to_element()方法来实现,示例代码如下:
from selenium.webdriver import ActionChains
bt=driver.find_element(By.XPATH,'//*[@id="s-top-left"]/div/a') # 定位元素
ActionChains(driver).move_to_element(bt).perform() # 使用ActionChains方法调用move_to_element实现悬停操作
--------------------------------------------------------
# 定位需要悬停的元素
element= browser.find_element(By.XPATH,'//div[@class="wid"]/ul/li[5]')
# 创建一个ActionChains对象
actions1 =ActionChains(browser)
# 执行鼠标悬停操作
actions1.move_to_element(element).perform()
4.6 滑动操作
滑动操作需要使用execute_script方法来实现,其传入的参数为JavaScript代码,示例代码如下:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.runoob.com/")
js='window.scrollTo(0, 500);'
# 使用execute_script方法执行JavaScript代码来实现鼠标滚动
driver.execute_script(js) # 向下滚动 500 像素
sleep(5)
driver.quit()
除了自定滑动的距离,我们还可以指定滑动到的页面元素,示例代码如下:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.set_window_size(500, 500)
driver.get("https://www.baidu.com/")
sleep(2)
target = driver.find_element(By.ID,'su') # 定位元素
driver.execute_script("arguments[0].scrollIntoView();", target) # 滑动到定位元素
sleep(2)
driver.quit()
5. 键盘操作
在webdriver中的keys类中,提供了很多按键方法,常用的按键操作有:
| 操作 | 描述 |
|---|---|
| Keys.ENTER | 回车键 |
| Keys.BACK_SPACE | 删除键 |
| Keys.CONTROL | Ctrl键 |
| Keys.F1 | F1键 |
| Keys.SPACE | 空格 |
| Keys.TAB | Tab键 |
| Keys.ESCAPE | ESC键 |
| Keys.ALT | Alt键 |
| Keys.SHIFT | Shift键 |
| Keys.ARROW_DOWN | 向下箭头 |
| Keys.ARROW_LEFT | 向左箭头 |
| Keys.ARROW_RIGHT | 向右箭头 |
| Keys.ARROW_UP | 向上箭头 |
接下来我们以回车键来演示,示例代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
el=driver.find_element(By.ID,'kw') # 定位元素
el.send_keys('NBA头条',Keys.ENTER) # 输出内容后按回车键
sleep(2) # 休眠2秒
driver.quit() # 关闭浏览器并释放进程资源
6. 等待操作
由于页面元素不会一下子就全部渲染出来,当定位还没渲染出来的元素时,就会报错,那么我们需要设置一下等待,等待可以分为:显式等待、隐式等待和强制等待。
6.1 显式等待
显式等待主要是使用WebDriverWait来实现,其语法格式如下:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
其中:
- driver:浏览器驱动;
- timeout:最长超时时间,默认以秒为单位;
- poll_frequency:检测的间隔步长,默认为0.5s;
- ignored_exceptions:超时后的抛出的异常信息,默认抛出NoSuchElementExeception异常。
在使用WebDriverWait时,需要搭配until或until_not方法来使用,其语法格式如下:
until(method,message='')
until_not(method,message='')
其中:
- method:指定预期条件的判断方法;
- message:超时后抛出的提示;
常用的method方法有:
| 方法 | 描述 |
|---|---|
| title_is('') | 判断当前页面的 title 是否等于预期 |
| title_contains('') | 判断当前页面的 title 是否包含预期字符串 |
| presence_of_element_located(locator) | 判断元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility_of_element_located(locator) | 判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 |
| visibility_of(element) | 跟上一个方法作用相同,但传入参数为 element |
| text_to_be_present_in_element(locator ,'') | 判断元素中的 text 是否包含了预期的字符串 |
| text_to_be_present_in_element_value(locator ,‘’) | 判断元素中的 value 属性是否包含了预期的字符串 |
| frame_to_be_available_and_switch_to_it(locator) | 判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False |
| invisibility_of_element_located(locator) | 判断元素中是否不存在于 dom 树或不可见 |
| element_to_be_clickable(locator) | 判断元素中是否可见并且是可点击的 |
| staleness_of(element) | 等待元素从 dom 树中移除 |
| element_to_be_selected(element) | 判断元素是否被选中,一般用在下拉列表 |
| element_selection_state_to_be(element,True) | 判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False |
| element_located_selection_state_to_be(locator,True) | 跟上一个方法作用相同,但传入参数为 locator |
| alert_is_present() | 判断页面上是否存在 alert |
示例代码如下:
from time import sleep
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
element = WebDriverWait(driver, 2, 0.5,ignored_exceptions=None).until(EC.presence_of_element_located((By.ID, 'toolbar-search-input')),message='超时!') # 定位不存在的标签
element.send_keys('NBA',Keys.ENTER)
sleep(5) # 休眠5秒
driver.quit() # 关闭浏览器并释放进程资源
运行结果为:message:超时!
6.2 隐式等待
Webdriver提供了三种隐式等待方法:
- implicitly_wait:识别对象时的超时时间;
- set_script_timeout:异步脚本的超时时间;
- set_page_load_timeout:页面加载时的超时时间。
这三种方法的语法格式如下:
implicitly_wait('时间')
set_script_timeout('时间')
set_page_load_timeout('时间')
大家可以根据需求来选择隐式等待的方法,这里演示implicitly_wait方法,示例代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.implicitly_wait(5) # 隐式等待5秒
el=driver.find_element(By.ID,'kw1') # 获取id为kw1的元素
el.send_keys('NBA头条')
bt=driver.find_element(By.ID,'su').click() # 单击左键
sleep(3) # 休眠5秒
driver.quit() # 关闭浏览器并释放进程资源
id为kw1的元素不存在,所以5秒后就会报错。
6.3 强制等待
强制等待通过休眠sleep方法来实现,不管元素是否存在、是否已加载出来,都会等到休眠时间结束才会继续下一步操作,示例代码如下:
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('https://www.baidu.com/')
sleep(5)
el=driver.find_element(By.ID,'kw')
el.send_keys('NBA头条')
bt=driver.find_element(By.ID,'su').click() # 单击左键
sleep(3) # 休眠5秒
driver.quit() # 关闭浏览器并释放进程资源


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)