Java集合详解
集合
一:集合概念 D:\workface1\springboot\bjpowernode\029-java-test
对象的容器,实现了对对象常用的操作,类似数组功能。
二:集合和数组的区别
(1) 数组长度固定,集合长度不固定
(2) 数组可以存储基本类型和引用类型,集合只能存引用类型
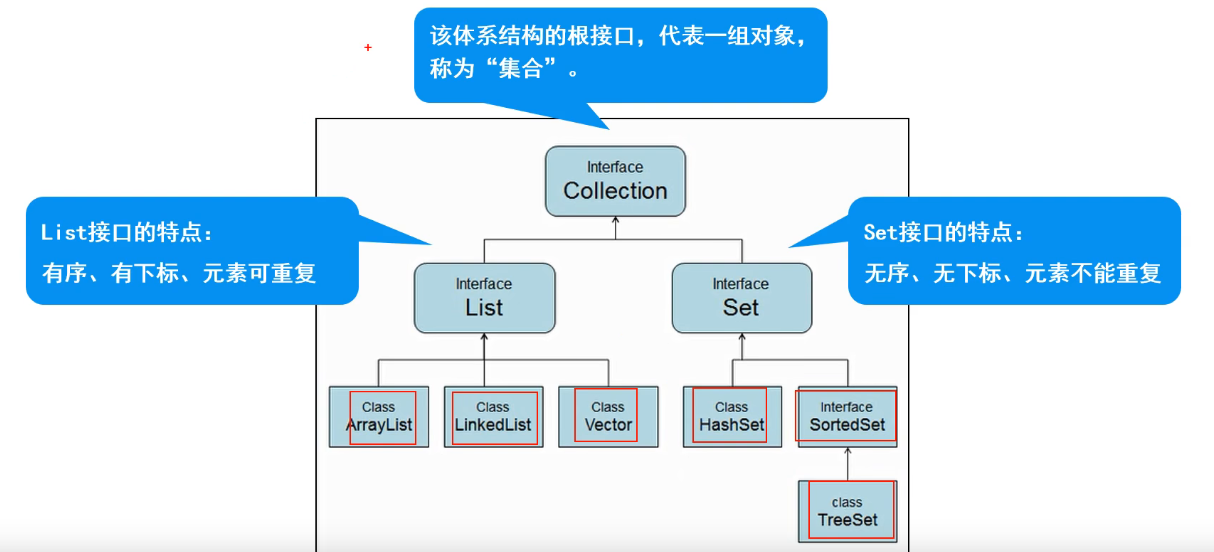
1.Conllection体系集合
1.Collection使用(1)
package com.jihu.Demo2;
/*
Collection 接口的使用
(1) 添加元素
(2) 删除元素
(3) 遍历元素
(4)判断
*/
import javax.swing.*;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo01 {
public static void main(String[] args) {
//创建集合
Collection collection = new ArrayList();
//(1) 添加元素
collection.add("苹果");
collection.add("西瓜");
collection.add("香蕉");
System.out.println("元素个数:"+collection.size());
System.out.println(collection);
// (2) 删除元素
collection.remove("西瓜");
System.out.println("删除之后:"+ collection.size());
// (3) 遍历元素(重点)
// 3.1使用增强for
System.out.println("---------3.1使用增强for---------");
for (Object object : collection) {
System.out.print(object + " ");
}
//3.2使用迭代器(迭代器专门用来遍历集合的一种方式)
//hasNext(); 有没有下一个元素
//next(); 获取下一个元素
//remove(); 删除当前元素
System.out.println();
System.out.println("---------3.2使用增强for---------");
Iterator it = collection.iterator();
while (it.hasNext()){
String s = (String) it.next();
System.out.print(s + " ");
//不能使用collection删除方法 如: collection.remove(s)
// it.remove();
}
System.out.println();
System.out.println("元素个数:"+collection.size());
// (4)判断
System.out.println(collection.contains("苹果")); //选择 看看是否有苹果
System.out.println(collection.isEmpty());
}
}
输出结果:
元素个数:3
[苹果, 西瓜, 香蕉]
删除之后:2
---------3.1使用增强for---------
苹果 香蕉
---------3.2使用增强for---------
苹果 香蕉
元素个数:2
true
false
2.Collection使用(2)
package com.jihu.Demo2;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo02 {
public static void main(String[] args) {
Collection collection = new ArrayList();
Student s1 = new Student("张三三",20);
Student s2 = new Student("张无忌",24);
Student s3 = new Student("张三丰",56);
//1.添加数据
collection.add(s1);
collection.add(s2);
collection.add(s3);
System.out.println("元素的个数:"+collection.size());
System.out.println(collection.toString());
//2.删除数据
/* collection.remove(s1);
collection.clear(); //清空里面的数据
System.out.println("删除后:"+collection.size());*/
//3.遍历
//3.1增强for
System.out.println("====3.1增强for===");
for (Object object : collection) {
// System.out.println(object); //与下面效果一样
Student s = (Student) object;
System.out.println(s.toString());
// System.out.println(s.getName()); //获取名字
}
//3.2 迭代器 : hasNext() next() remove() 迭代器中不能使用collection的删除方法
System.out.println("====3.2增强for===");
Iterator it = collection.iterator();
while (it.hasNext()){
//System.out.println(it.next()); //与下面效果一样
Student s = (Student) it.next();
System.out.println(s.toString());
}
//4.判断
System.out.println(collection.contains(s1)); //true
System.out.println(collection.contains(new Student("张三丰",56))); //false
System.out.println(collection.isEmpty()); //false
}
}
输出结果
元素的个数:3
[Student{name='张三三', age=20}, Student{name='张无忌', age=24}, Student{name='张三丰', age=56}]
====3.1增强for===
Student{name='张三三', age=20}
Student{name='张无忌', age=24}
Student{name='张三丰', age=56}
====3.2增强for===
Student{name='张三三', age=20}
Student{name='张无忌', age=24}
Student{name='张三丰', age=56}
true
true
false
2.List接口
1.List子接口
- 特点: 有序、有下标、元素可以重复
- 方法
void add(int index,Object o) //在index位置插入对象O
boolean addAll(int index,Collection c) //将一个集合中的元素添加到此集合中的index位置
Object get(int index) //返回集合中指定位置的元素
List subList(int fromIndex,int toIndex) //返回fromIndex和toIndex之间的集合元素
2.List接口的使用(1)
package com.jihu.Demo2;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
/*
List子接口的使用:
特点: 1.有序 有下标 2.可以重复
*/
public class Demo03 {
public static void main(String[] args) {
//先创建集合对象
List list = new ArrayList();
//1.添加元素
list.add("苹果");
list.add("小米");
list.add(0,"华为");
System.out.println("元素个数:"+ list.size());
System.out.println(list.toString());
//2.删除元素
/* list.remove("苹果");
list.remove(0);
System.out.println("删除后元素个数:"+ list.size());*/
//3.遍历
//3.1使用for遍历
System.out.println("-------3.1使用for遍历------");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//3.2使用增强for
System.out.println("-------3.1使用增强for------");
for (Object object : list) {
System.out.println(object);
}
//3.3使用迭代器
System.out.println("-------3.3使用迭代器------");
Iterator it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//3.4使用列表迭代器,和Iterator的区别,ListIterator可以向前或向后遍历,添加,删除,修改元素
ListIterator listIterator = list.listIterator();
System.out.println("-------3.4使用列表迭代器从前往后------");
while (listIterator.hasNext()){
System.out.println(listIterator.nextIndex()+":"+ listIterator.next());
}
System.out.println("-------3.4使用列表迭代器从后往前------");
while (listIterator.hasPrevious()){
System.out.println(listIterator.previousIndex() +":"+ listIterator.previous());
}
//4.判断
System.out.println(list.contains("小米"));
System.out.println(list.isEmpty());
//5.获取位置
System.out.println(list.indexOf("苹果")); //获取元素下标操作
}
}
输出结果
元素个数:3
[华为, 苹果, 小米]
-------3.1使用for遍历------
华为
苹果
小米
-------3.1使用增强for------
华为
苹果
小米
-------3.3使用迭代器------
华为
苹果
小米
-------3.4使用列表迭代器从前往后------
0:华为
1:苹果
2:小米
-------3.4使用列表迭代器从后往前------
2:小米
1:苹果
0:华为
true
false
1
3.List接口的使用(2)
package com.jihu.Demo2;
import java.util.ArrayList;
import java.util.List;
public class Demo04 {
public static void main(String[] args) {
//创建集合
List list = new ArrayList();
//1.添加数字数据(自动装箱)
list.add(20);
list.add(30);
list.add(40);
list.add(50);
System.out.println("获取元素个数:"+list.size());
System.out.println(list.toString());
//2.删除操作
//list.remove(0); //删除第一个元素
// list.remove(new Integer(30));
list.remove((Object) 20);
System.out.println("删除元素:"+list.size());
System.out.println(list.toString());
//3.补充方法 subList : 返回子集合,包含头不包含尾
List list1 = list.subList(1,3); //[40, 50]
System.out.println(list1.toString());
}
}
输出结果:
获取元素个数:4
[20, 30, 40, 50]
删除元素:3
[30, 40, 50]
[40, 50]
4.List实现类
- ArrayList 【 重点 用的最多的现在】
数组结构实现,查询快,增删慢;
JDK1.2版本,运行效率快,线程不安全。
源码分析: DEFAULT_CAPACITY = 10 : 默认容量大小
注意: 如果没有向集合中添加任何元素时,容量0,添加一个元素之后 容量10 每次扩 容大小是原来的1.5倍
elementData : 存放元素的数组
size : 实际元素个数
- LinkedList;
链表结构实现,增删快,查询慢
-
Vector: (现在基本不用)
数组结构实现,查询快,增删慢
JDK1.0版本后,运行效率慢,线程安全。
1.ArrayList使用
package com.jihu.Demo2;
/*
ArrayList使用:
数组结构实现,查询快,增删慢;
*/
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
public class Demo05 {
public static void main(String[] args) {
//创建集合
ArrayList arrayList = new ArrayList();
//1.添加元素
Student s1 = new Student("刘德华",40);
Student s2 = new Student("郭富城",30);
Student s3 = new Student("美云",24);
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
System.out.println(arrayList.size());
System.out.println(arrayList.toString());
//2.删除元素
arrayList.remove(s1);
System.out.println("删除后元素个数:"+arrayList.size());
//3.遍历元素【重点】
//3.1使用迭代器
System.out.println("----------");
Iterator it = arrayList.iterator();
while (it.hasNext()){
Student s = (Student) it.next();
System.out.println(s.toString());
}
//3.2列表迭代器
System.out.println("-----前序------");
ListIterator lit = arrayList.listIterator();
while (lit.hasNext()){
Student s = (Student) lit.next();
System.out.println(s.toString());
}
System.out.println("-------后序----");
while (lit.hasPrevious()){
Student st1 = (Student) lit.previous();
System.out.println(st1.toString());
}
//4.判断
System.out.println(arrayList.contains(s2)); //true
//因为Student类中重写了euqals方法所有下面才会输出true
System.out.println(arrayList.contains(new Student("美云",24))); //true
System.out.println(arrayList.isEmpty()); //false
//5.查找
System.out.println(arrayList.indexOf(s3)); // 1
System.out.println(arrayList.indexOf(new Student("美云",24))); // 1
}
}
输出结果:
3
[Student{name='刘德华', age=40}, Student{name='郭富城', age=30}, Student{name='美云', age=24}]
删除后元素个数:2
----------
Student{name='郭富城', age=30}
Student{name='美云', age=24}
-----前序------
Student{name='郭富城', age=30}
Student{name='美云', age=24}
-------后序----
Student{name='美云', age=24}
Student{name='郭富城', age=30}
true
true
false
1
1
//Student类中重写了 equals方法
@Override
public boolean equals(Object obj) {
//1.判断是不是同一个对象
if (obj == this){
return true;
}
//2.判断是否为空
if (obj == null){
return false;
}
//3.判断是否是Student类型
if (obj instanceof Student){
Student s = (Student) obj;
//4.比较属性
if (this.name.equals(s.getName()) && this.age == s.getAge()){
return true;
}
}
return false;
}
2.Vector使用
package com.jihu.Demo2;
import java.util.Enumeration;
import java.util.Vector;
/*
演示Vector集合的使用:
存储结构:数组
*/
public class Demo06 {
public static void main(String[] args) {
//1.创建集合
Vector vector = new Vector();
//2.添加元素
vector.add("草莓");
vector.add("芒果");
vector.add("西瓜");
System.out.println("元素个数:"+vector.size());
//3.删除
/*vector.remove(0);
vector.remove("西瓜");
vector.clear();*/
//4.遍历
//1. 使用枚举器
Enumeration en = vector.elements();
while (en.hasMoreElements()){
String o = (String) en.nextElement();
System.out.println(o);
}
// 等其他几个 与ArrayList一样
System.out.println("*------");
for (Object o : vector) {
System.out.println(o);
}
//4.判断
System.out.println(vector.contains("西瓜"));
System.out.println(vector.isEmpty());
}
}
输出结果:
元素个数:3
草莓
芒果
西瓜
*------
草莓
芒果
西瓜
true
false
3.LinkedList使用
package com.jihu.Demo2;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
/*
LinkedList使用:
存储结构:双向链表
*/
public class LinkedList1 {
public static void main(String[] args) {
//创建集合
LinkedList linkedList = new LinkedList();
//1.添加元素
Student s1 = new Student("刘德华",40);
Student s2 = new Student("郭富城",30);
Student s3 = new Student("美云",24);
Student s4 = new Student("悟空",34);
linkedList.add(s1);
linkedList.add(s2);
linkedList.add(s3);
linkedList.add(s4);
System.out.println("元素的个数:"+ linkedList.size());
//System.out.println(linkedList); //这样也行
System.out.println(linkedList.toString());
//2.删除
linkedList.remove(s1);
//student中重写了equals方法所有这样也能删除
linkedList.remove(new Student("郭富城",30));
System.out.println("删除后:"+linkedList.size());
//3.遍历
System.out.println("-------1-------");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
System.out.println("------2--------");
for (Object o : linkedList) {
Student s = (Student) o;
System.out.println(o.toString());
}
System.out.println("-------3-------");
Iterator it = linkedList.iterator();
while (it.hasNext()){
//System.out.println(it.next());
Student s = (Student) it.next();
System.out.println(s.toString());
}
System.out.println("-------4-------");
ListIterator lit = linkedList.listIterator();
while (lit.hasNext()){
Student lits = (Student) lit.next();
System.out.println(lits.toString());
}
//4.判断
System.out.println(linkedList.contains(s3));
System.out.println(linkedList.isEmpty());
//5.获取
System.out.println(linkedList.indexOf(s4)); //1
}
}
输出:
元素的个数:4
[Student{name='刘德华', age=40}, Student{name='郭富城', age=30}, Student{name='美云', age=24}, Student{name='悟空', age=34}]
删除后:2
-------1-------
Student{name='美云', age=24}
Student{name='悟空', age=34}
------2--------
Student{name='美云', age=24}
Student{name='悟空', age=34}
-------3-------
Student{name='美云', age=24}
Student{name='悟空', age=34}
-------4-------
Student{name='美云', age=24}
Student{name='悟空', age=34}
true
false
1
3.泛型
java泛型是JDK1.5中引入的一个新特性,其本质是参数化类型,把类型作为参数传递。
常见形式有: 泛型类,泛型接口,泛型方法。
语法:
< T ,......> T称为类型占位符, 表示一种引用类型。
好处:
(1): 提供代码的重用行
(2):防止类型转换异常,提高代码的安全性
1.泛型类
package com.jihu.Demo3;
/*
泛型类
语法: 类名<T>
T是类型占位符,表示一种引用类型,如果编写多个使用逗号隔开
*/
public class MyGeneric<T> {
//使用泛型T
//1.创建变量
T t;
//2.泛型作为方法的参数
public void show(T t){
System.out.println(t);
}
//3.泛型作为方法的返回值
public T getT(){
return t;
}
}
package com.jihu.Demo3;
public class TestGeneric {
public static void main(String[] args) {
//使用泛型类创建对象
//注意 : 1.泛型只能使用引用类型 2.不同泛型类型对象之间不能相互赋值
MyGeneric<String> myGeneric = new MyGeneric<>();
myGeneric.t="hello";
myGeneric.show("大家好,加油"); //大家好,加油
String string = myGeneric.getT();
System.out.println(string); //hello
MyGeneric<Integer> myGeneric1 = new MyGeneric<>();
myGeneric1.t = 100;
myGeneric1.show(200);
Integer t1 = myGeneric1.getT();
System.out.println(t1);
}
}
输出结果:
大家好,加油
hello
200
100
2.泛型接口
/*
泛型接口:
语法: 接口名<T>
注意: 不能泛型静态常量
*/
public interface MyInterface<T> {
String name = "张三";
T server(T t);
}
package com.jihu.Demo3;
public class MyInterfaceImpl implements MyInterface<String> {
@Override
public String server(String s) {
System.out.println(s);
return s;
}
}
package com.jihu.Demo3;
public class TestGeneric {
public static void main(String[] args) {
MyInterfaceImpl impl = new MyInterfaceImpl();
impl.server("xxxxxxxxxx"); // 输出 xxxxxxxxxx
}
}
3.泛型方法
package com.jihu.Demo3;
/*
泛型方法:
语法:<T> 返回值类型
*/
public class MyGenericMethod {
//泛型方法
public <T> T show (T t){
System.out.println("泛型方法: "+t);
return t;
}
}
package com.jihu.Demo3;
public class TestGeneric {
public static void main(String[] args) {
MyGenericMethod myGenericMethod = new MyGenericMethod();
myGenericMethod.show("中国加油");
myGenericMethod.show(200);
}
}
输出结果:
泛型方法: 中国加油
泛型方法: 200
4.泛型集合
package com.jihu.Demo3;
import com.jihu.Demo2.Student;
import java.util.ArrayList;
import java.util.Iterator;
public class Demo03 {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("吴峰");
arrayList.add("武警");
for (String s : arrayList) {
System.out.println(s);
}
ArrayList<Student> arrayList1 = new ArrayList<>();
Student s1 = new Student("刘德华",40);
Student s2 = new Student("郭富城",30);
Student s3 = new Student("美云",24);
arrayList1.add(s1);
arrayList1.add(s2);
arrayList1.add(s3);
Iterator<Student> it = arrayList1.iterator();
while (it.hasNext()){
Student s = it.next();
System.out.println(s.toString());
}
}
}
输出结果
吴峰
武警
Student{name='刘德华', age=40}
Student{name='郭富城', age=30}
Student{name='美云', age=24}
4.Set集合概述
1.Set子接口
特点: 无序、无下标、元素不可重复。
方法: 全部继承自Collection中的方法。
set接口使用:
package com.jihu.Demo4;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/*
测试set接口的使用
特点:无序、无下标、元素不可重复
*/
public class Demo1 {
public static void main(String[] args) {
//创建集合
Set<String> set = new HashSet<>();
//1.添加数据
set.add("苹果");
set.add("华为");
set.add("小米");
set.add("香蕉");
System.out.println("元素个数"+set.size());
System.out.println(set.toString());
//2.删除数据
set.remove("小米");
System.out.println(set.toString());
//3.遍历【重点】
for (String s : set) {
System.out.println(s);
}
System.out.println("--------");
Iterator<String> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//4.判断
System.out.println(set.contains("华为"));
System.out.println(set.isEmpty());
}
}
输出:
元素个数4
[苹果, 香蕉, 华为, 小米]
[苹果, 香蕉, 华为]
苹果
香蕉
华为
--------
苹果
香蕉
华为
true
false
2.HashSet使用 [重点]
- 基于HashCode计算元素存放位置。
- 当存入元素的哈希码相同 时,会调用equals进行确认,如结果为true,则拒绝后者存入。
案例1
package com.jihu.Demo4;
import java.util.HashSet;
import java.util.Iterator;
/*
HashSet集合的使用
存储结构:哈希表(数组+链表+红黑树)
*/
public class HashSet01 {
public static void main(String[] args) {
//新建集合
HashSet<String> hashSet = new HashSet<>();
//1.添加元素
hashSet.add("马云");
hashSet.add("吴京");
hashSet.add("*");
hashSet.add("周润发");
System.out.println("元素个数:"+hashSet.size());
System.out.println(hashSet.toString());
//2.删除数据
hashSet.remove("*");
System.out.println(hashSet.toString());
//3.遍历操作
Iterator<String> it = hashSet.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//4.判断
System.out.println(hashSet.contains("毛泽1")); //false
System.out.println(hashSet.isEmpty()); //false
}
}
输出结果:
元素个数:4
[吴京, 马云, 周润发, *]
[吴京, 马云, 周润发]
吴京
马云
周润发
false
false
案例2
@Override
public int hashCode() {
int n1= this.name.hashCode();
int n2 = this.age;
System.out.println("n1 n2:"+n1+n2);
return n1+n2;
}
@Override
public boolean equals(Object obj) {
if (obj == this){
return true;
}
if (obj == null){
return false;
}
if (obj instanceof Person){
Person person = (Person) obj;
if (this.name.equals(person.getName()) && this.age == person.getAge()){
return true;
}
}
return false;
}
//或者 alt+insert 快捷键 重写equals()和hashcode()
package com.jihu.Demo4;
import java.util.HashSet;
import java.util.Iterator;
/*
HashSet集合的使用
存储结构:哈希表(数组+链表+红黑树)
存储过程 (重复的依据)
(1)根据hashcode计算保存的位置,如果此位置为空,则直接保存,如果不为空执行第二步
(2)再执行equals方法,如果equals方法为true,则认为是重复,否则,形成链表
*/
public class HashSet02 {
public static void main(String[] args) {
//创建集合
HashSet<Person> person = new HashSet<>();
//1.添加数据
Person person1 = new Person("三毛",40);
Person person2 = new Person("憨豆先生",60);
Person person3 = new Person("林志玲",30);
person.add(person1);
person.add(person2);
person.add(person3);
// person.add(person3);//重复 不会添加进来数据
//因为person类中 重写了equals()和hashcode() 所有不能添加以下用户名
person.add(new Person("林志玲",30));
System.out.println("元素个数"+person.size());
System.out.println(person.toString());
//2.删除操作
person.remove(person1);
person.remove(new Person("三毛",40));
System.out.println("删除后元素个数:"+person.size());
//3.遍历【重点】
Iterator<Person> iterator = person.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//4.判断
System.out.println(person.contains(new Person("憨豆先生",60))); //true
System.out.println(person.isEmpty()); //false
}
}
输出结果:
n1 n2:64689840
n1 n2:77995954160
n1 n2:2627496230
n1 n2:2627496230
元素个数3
[Person{name='林志玲', age=30}, Person{name='三毛', age=40}, Person{name='憨豆先生', age=60}]
n1 n2:64689840
n1 n2:64689840
删除后元素个数:2
Person{name='林志玲', age=30}
Person{name='憨豆先生', age=60}
n1 n2:77995954160
true
false
3.TreeSet使用
TreeSet:
基于排列顺序实现元素不重复。
实现了SortedSet接口,对集合元素自动排序
元素对象的类型必须实现 Comparable接口,指定排序规则。
通过CompareTo方法确定是否为重复元素
案例
package com.jihu.Demo4;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSet01 {
public static void main(String[] args) {
//创建集合
TreeSet<String> treeSet = new TreeSet<>();
//1.添加元素
treeSet.add("xyz");
treeSet.add("abc");
treeSet.add("hkasf");
System.out.println("元素个数:"+treeSet.size());
System.out.println(treeSet.toString());
//2.删除
treeSet.remove("xyz");
System.out.println("删除后元素个数:"+treeSet.size());
//3.遍历
Iterator<String> it = treeSet.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//4.判断
System.out.println(treeSet.contains("abc")); //true
System.out.println(treeSet.isEmpty()); //false
}
}
输出结果
元素个数:3
[abc, hkasf, xyz]
删除后元素个数:2
abc
hkasf
true
false
案例2
public class Person implements Comparable<Person> {
private String name;
private Integer age;
//先按姓名比,再按年龄比
@Override
public int compareTo(Person o) {
int n1= this.getName().compareTo(o.getName());
int n2 = this.getAge()-o.getAge();
return n1 == 0? n2: n1;
}
}
package com.jihu.Demo4;
/*
使用TreeSet保存数据
存储结构:红黑树
要求:元素必须要实现Comparable接口 ,compareTo()方法返回值为0,认为是重复元素
*/
import java.util.TreeSet;
public class TreeSet02 {
public static void main(String[] args) {
TreeSet<Person> treeSet = new TreeSet<>();
Person person1 = new Person("三毛",40);
Person person2 = new Person("憨豆先生",60);
Person person3 = new Person("林志玲",30);
Person person4 = new Person("林志玲",35);
treeSet.add(person1);
treeSet.add(person2);
treeSet.add(person3);
treeSet.add(person4);
System.out.println("元素个数:"+treeSet.size());
System.out.println(treeSet.toString());
}
}
案例3
package com.jihu.Demo4;
/*
TreeSet集合的使用
Comparator:实现定制比较(比较器) 这样就不用在person那 implements Comparable实现这个接口了
Comparable:可比较的
*/
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSet03 {
public static void main(String[] args) {
//创建集合,并指定比较规则
TreeSet<Person> treeSet = new TreeSet<>(new Comparator<Person>(){
@Override
public int compare(Person o1, Person o2) {
int n1 = o1.getAge()-o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1==0? n2:n1;
}
});
Person person1 = new Person("三毛",40);
Person person2 = new Person("憨豆先生",60);
Person person3 = new Person("林志玲",30);
Person person4 = new Person("林志玲",35);
treeSet.add(person1);
treeSet.add(person2);
treeSet.add(person3);
treeSet.add(person4);
System.out.println("元素个数:"+treeSet.size());
System.out.println(treeSet.toString());
}
}
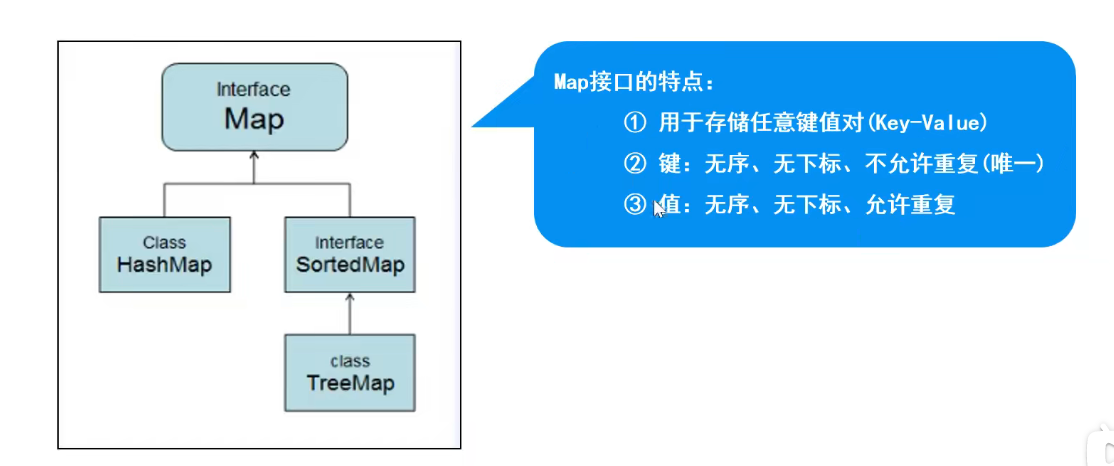
5.Map集合
1.Map集合概述
特点:存储一对数据(Key-Value),无序,无下标,键不可重复,值可重复。
方法:
V put(K Key,V Value) //将对象存入到集合中,关联键值。key重复则覆盖原值。
Object get (Object key) //根据键获取对应的值
Set
Collection
Set<Map.Entry<K,V>> entrySet() //键值匹配的Set集合
小试牛刀:
package com.jihu.MapDemo;
/*
Mao接口的使用
特点:(1)存储键值对 (2)键不能重复(3)无序
*/
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo01 {
public static void main(String[] args) {
//创建Map集合
Map<String,String> map = new HashMap<>();
//1.添加元素
map.put("cn","中国");
map.put("uk","英国");
map.put("us","美国");
map.put("cn","中国22"); //如果key值相同则会覆盖掉前面的那一个
System.out.println("元素个数:"+map.size());
System.out.println(map.toString());
//2.删除
map.remove("cn");
System.out.println(map.toString());
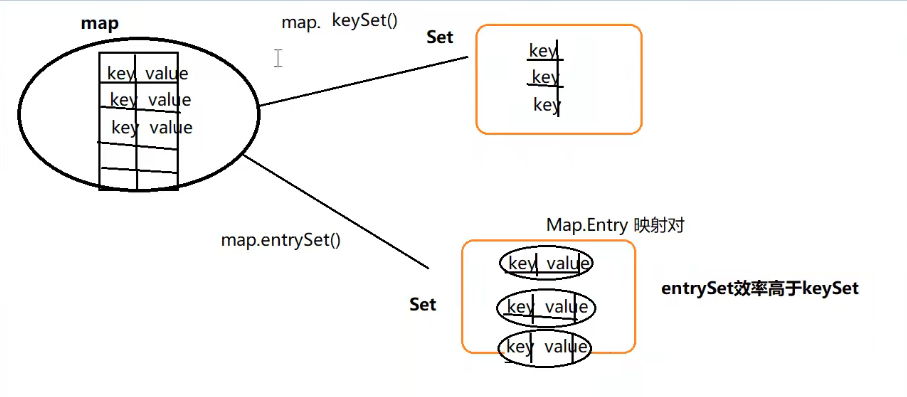
//3.遍历
//3.1使用keySet()
System.out.println("--------keyset()--------");
Set<String> keyset = map.keySet();
for (String key : keyset) {
System.out.println(key+ "--------"+ map.get(key));
}
//也可以写成 for (String key : map.keySet())
//3.2使用entryset()方法
System.out.println("--------entryset()--------");
Set<Map.Entry<String,String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey()+"-----------"+entry.getValue());
}
//也可以写成 for (Map.Entry<String, String> entry : map.entrySet())
//4.判断
System.out.println(map.containsKey("uk")); //true
System.out.println(map.containsValue("泰国")); //false
}
}
输出结果:
元素个数:3
{uk=英国, cn=中国22, us=美国}
{uk=英国, us=美国}
--------keyset()--------
uk--------英国
us--------美国
--------entryset()--------
uk-----------英国
us-----------美国
true
false
keyset()和entryset()遍历时的映射图:
2.HashMap【重点】
JDK1.2版本,线程不安全,运行效率快;允许用null作为key或是value。
源码分析:
1.static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //hashMap初始容量大小 16
2.static final int MAXIMUM_CAPACITY = 1 << 30 //hashMap的数组最大容量
3.static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子
4.static final int TREEIFY_THRESHOLD = 8; //jdk1.8 当链表长度大于8时,调整成红黑树
5.static final int UNTREEIFY_THRESHOLD = 6; //jdk1.8 当链表长度小于6时,调整成链表
6.static final int MIN_TREEIFY_CAPACITY = 64; //jdk1.8 当链表长度大于8时,并且集合元素个数大于等于64时,调整成红黑树
7.transient Node<K,V> table; //哈希表中的数组
8.size //元素个数
//刚创建hashMap之后没有添加元素 table=null size=0 目的节省空间
案例:
package com.jihu.MapDemo;
/*
HashMap集合的使用
存储结构:哈希表 (数组+链表+红黑树)
使用key的hashcode和equals作为重复依据
*/
import java.util.HashMap;
import java.util.Map;
public class Demo02 {
public static void main(String[] args) {
//创建集合
HashMap<Student,String> students = new HashMap<>();
//刚创建hashMap之后没有添加元素 table=null size=0 目的节省空间
//1.添加元素
Student s1 = new Student("毛1",100);
Student s2 = new Student("*",70);
Student s3 = new Student("孙悟空",80);
Student s4 = new Student("孙悟空",80);
students.put(s1,"北京");
students.put(s2,"上海");
students.put(s3,"西天");
students.put(s3,"西天2"); //这样也会覆盖前面的“西天”
//重写了hashcode和equals再添加 new Student("孙悟空",80) 就添加不进来了
students.put(s4,"西天3号"); //
System.out.println("元素个数:"+students.size());
System.out.println(students.toString());
//2.删除
students.remove(s1);
System.out.println("删除后元素个数:"+students.size());
//3.遍历
//3.1使用keyset()
System.out.println("-------keyset()-----");
for (Student key : students.keySet()) {
System.out.println(key.toString()+"---"+students.get(key));
}
//3.2使用entryset()
System.out.println("-------entryset()-----");
for (Map.Entry<Student,String> entry : students.entrySet()) {
System.out.println(entry.getKey()+"---"+entry.getValue());
}
//4.判断
System.out.println(students.containsKey(s1)); //false
System.out.println(students.containsKey(new Student("*",70))); //true 因为重写了hashcode和equals
System.out.println(students.containsValue("杭州")); //false
}
}
输出结果:
元素个数:3
{Student{name='毛1', stuNo=100}=北京, Student{name='孙悟空', stuNo=80}=西天3号, Student{name='*', stuNo=70}=上海}
删除后元素个数:2
-------keyset()-----
Student{name='孙悟空', stuNo=80}---西天3号
Student{name='*', stuNo=70}---上海
-------entryset()-----
Student{name='孙悟空', stuNo=80}---西天3号
Student{name='*', stuNo=70}---上海
false
true
false
import java.util.Objects;
public class Student {
private String name;
private Integer stuNo;
//重写 hashcode和equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name) &&
Objects.equals(stuNo, student.stuNo);
}
@Override
public int hashCode() {
return Objects.hash(name, stuNo);
}
}
总结:
(1)HashMap刚创建时,table是null,为了节省空间,当添加第一个元素是 table容量调整为16
(2)当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后大小为原来的2倍,目的是减少调整元素的个数。
(3)jdk1.8 当每个链表长度大于8,并且元素个数大于等于64时,会调整为红黑树,目的提高执行效率。
(4)jdk1.8 当链表长度小于6时,调整成链表
(5)jdk1.8以前 ,链表是头插法, jdk1.8以后 链表为尾插法
//HashSet<> 和HashMap<K,V>比较
HashSet<>里面会调用HashMap<K,V>,等于是HashMap的一个子集
3.Hashtable:【不咋重要】
JDK1.0版本,线程安全,运行效率慢;不允许null作为key或是value。
4.Properties:【用的多】
Hashtable的子类,要求key和value都是String。 通常用于配置文件的读取。
5.TreeMap:
实现了SortedMap接口(是Map的子接口),可以对key自动排序。
案例:
package com.jihu.MapDemo;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
/*
TreeMap的使用
存储结构:红黑树
*/
public class Demo03 {
public static void main(String[] args) {
//新建集合
TreeMap<Student,String> treeMap = new TreeMap<>(new Comparator<Student>() {
//(用定制方法比较)
@Override
public int compare(Student o1, Student o2) {
int n1 = o1.getStuNo()-o2.getStuNo();
return n1;
}
});
//1.添加元素
Student s1 = new Student("毛1",100);
Student s2 = new Student("*",70);
Student s3 = new Student("孙悟空",80);
treeMap.put(s1,"北京");
treeMap.put(s2,"上海");
treeMap.put(s3,"深圳");
System.out.println("元素的个数:"+treeMap.size());
System.out.println(treeMap.toString());
//2.删除
treeMap.remove(s1);
System.out.println(treeMap.toString());
//3.遍历
System.out.println("----keySet()----");
for (Student key : treeMap.keySet()) {
System.out.println(key+"--"+treeMap.get(key));
}
System.out.println("----entrySet()----");
for (Map.Entry<Student, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey()+"---"+entry.getValue());
}
//4.判断
System.out.println(treeMap.containsKey(s2)); //true
System.out.println(treeMap.containsKey(new Student("孙悟空",80))); //true
System.out.println(treeMap.containsValue("深圳")); //true
}
}
输出:
元素的个数:3
{Student{name='*', stuNo=70}=上海, Student{name='孙悟空', stuNo=80}=深圳, Student{name='毛1', stuNo=100}=北京}
{Student{name='*', stuNo=70}=上海, Student{name='孙悟空', stuNo=80}=深圳}
----keySet()----
Student{name='*', stuNo=70}--上海
Student{name='孙悟空', stuNo=80}--深圳
----entrySet()----
Student{name='*', stuNo=70}---上海
Student{name='孙悟空', stuNo=80}---深圳
true
true
true
public class Student implements Comparable<Student> {
private String name;
private Integer stuNo;
@Override
public int compareTo(Student o) {
// int n1= this.name.compareTo(o.getName());
int n2 = this.stuNo-o.getStuNo();
// return n1==0?n2:n1;
return n2;
}
}
TreeMap和TreeSet比较: TreeSet调用TreeMap
6.Collections工具类
概念:集合工具类,定义了除了存取以外的集合常用方法。
方法:
public static void reverse(List<?> list) //反转集合中元素的顺序
public static void shuffle(List<?> list) //随机重置集合元素的顺序
public static void sort(List<T> list) //升序排序 (元素类型必须实现Comparable接口)
package com.jihu.MapDemo;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
/*
演示Collections工具类的使用
*/
public class Demo04 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(30);
list.add(3);
list.add(15);
list.add(60);
list.add(40);
list.add(35);
//sort排序
System.out.println("排序前:" + list);
Collections.sort(list);
System.out.println("排序后:" + list);
//binarySearch二分查找
int i= Collections.binarySearch(list,35);
System.out.println(i);
//copy复制
List<Integer> dest = new ArrayList<>();
for (int k=0;k<list.size();k++){
dest.add(0);
}
Collections.copy(dest,list);
System.out.println("list1:=="+dest);
//reverse反转
Collections.reverse(list);
System.out.println("反转后:"+list);
//shuffle 打乱
Collections.shuffle(list);
System.out.println("打乱后:" +list);
//补充: list转成数组
System.out.println("--------list转成数组-------");
Integer[] arr = list.toArray(new Integer[0]);
System.out.println(arr.length);
System.out.println(Arrays.toString(arr));
//数组转成集合
System.out.println("--------数组转成集合-------");
String[] names = {"张三","李四","王五"};
//集合是一个受限集合,不能添加和删除
List<String> strings = Arrays.asList(names);
System.out.println(strings);
//把基本类型数组转成集合时,需要修改为包装类型
Integer[] nums = {100,200,450,650,450};
List<Integer> integers = Arrays.asList(nums);
System.out.println(integers);
}
}
输出结果
排序前:[30, 3, 15, 60, 40, 35]
排序后:[3, 15, 30, 35, 40, 60]
3
list1:==[3, 15, 30, 35, 40, 60]
反转后:[60, 40, 35, 30, 15, 3]
打乱后:[3, 35, 30, 15, 40, 60]
--------list转成数组-------
6
[3, 35, 30, 15, 40, 60]
--------数组转成集合-------
[张三, 李四, 王五]
[100, 200, 450, 650, 450]
6.集合总结



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析