golang note 27-45
27.Go中的map如何实现顺序读取?
Go中map如果要实现顺序读取的话,可以先把map中的key,通过sort包排序.
通过sort中的排序包进行对map中的key进行排序.
28.Go中CAS是怎么回事?
CAS算法(Compare And Swap),是原子操作的一种, CAS算法是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。
该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
Go中的CAS操作是借用了CPU提供的原子性指令来实现。CAS操作修改共享变量时候不需要对共享变量加锁,而是通过类似乐观锁的方式进行检查,本质还是不断的占用CPU 资源换取加锁带来的开销(比如上下文切换开销)。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var (
counter int32 //计数器
wg sync.WaitGroup //信号量
)
func main() {
threadNum := 5
wg.Add(threadNum)
for i := 0; i < threadNum; i++ {
go incCounter(i)
}
wg.Wait()
}
func incCounter(index int) {
defer wg.Done()
spinNum := 0
for {
// 原子操作
old := counter
ok := atomic.CompareAndSwapInt32(&counter, old, old+1)
if ok {
break
} else {
spinNum++
}
}
fmt.Printf("thread,%d,spinnum,%d\n", index, spinNum)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
当主函数main首先创建了5个信号量,然后开启五个线程执行incCounter方法,incCounter内部执行, 使用cas操作递增counter的值,atomic.CompareAndSwapInt32具有三个参数,第一个是变量的地址,第二个是变量当前值,第三个是要修改变量为多少,该函数如果发现传递的old值等于当前变量的值,则使用第三个变量替换变量的值并返回true,否则返回false。
这里之所以使用无限循环是因为在高并发下每个线程执行CAS并不是每次都成功,失败了的线程需要重写获取变量当前的值,然后重新执行CAS操作。读者可以把线程数改为10000或者更多就会发现输出thread,5329,spinnum,1 其中这个1就说明该线程尝试了两个CAS操作,第二次才成功。
因此呢, go中CAS操作可以有效的减少使用锁所带来的开销,但是需要注意在高并发下这是使用cpu资源做交换的。
29.Go中的逃逸分析是什么?
在Go中逃逸分析是一种确定指针动态范围的方法,可以分析在程序的哪些地方可以访问到指针。它涉及到指针分析和形状分析。
当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它执行线程中,或者去调用子程序。如果使用尾递归优化(通常在函数编程语言中是需要的),对象也可能逃逸到被调用的子程序中。 如果一个子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中的任何一个地方被访问到——这样指针就成功“逃逸”了。
如果指针存储在全局变量或者其它数据结构中,它们也可能发生逃逸,这种情况是当前程序中的指针逃逸。 逃逸分析需要确定指针所有可以存储的地方,保证指针的生命周期只在当前进程或线程中。
导致内存逃逸的情况比较多,有些可能还是官方未能够实现精确的分析逃逸情况的 bug,通常来讲就是如果变量的作用域不会扩大并且其行为或者大小能够在编译的时候确定,一般情况下都是分配到栈上,否则就可能发生内存逃逸分配到堆上。
内存逃逸的五种情况:
-
发送指针的指针或值包含了指针到
channel中,由于在编译阶段无法确定其作用域与传递的路径,所以一般都会逃逸到堆上分配。 -
slices 中的值是指针的指针或包含指针字段。一个例子是类似
[]*string的类型。这总是导致 slice 的逃逸。即使切片的底层存储数组仍可能位于堆栈上,数据的引用也会转移到堆中。 -
slice 由于 append 操作超出其容量,因此会导致 slice 重新分配。这种情况下,由于在编译时 slice 的初始大小的已知情况下,将会在栈上分配。如果 slice 的底层存储必须基于仅在运行时数据进行扩展,则它将分配在堆上。
-
调用接口类型的方法。接口类型的方法调用是动态调度,实际使用的具体实现只能在运行时确定。考虑一个接口类型为 io.Reader 的变量 r。对 r.Read(b) 的调用将导致 r 的值和字节片b的后续转义并因此分配到堆上。
-
尽管能够符合分配到栈的场景,但是其大小不能够在在编译时候确定的情况,也会分配到堆上.
有效的避免上述的五种逃逸的情况,就可以避免内存逃逸.
30.Go值接收者和指针接收者的区别?
o中的方法能给用户自定义的类型添加新的行为。它和函数的区别在于方法有一个接收者,给一个函数添加一个接收者,那么它就变成了方法。接收者可以是值接收者,也可以是指针接收者。
在调用方法的时候,值类型既可以调用值接收者的方法,也可以调用指针接收者的方法;指针类型既可以调用指针接收者的方法,也可以调用值接收者的方法。
也就是说,不管方法的接收者是什么类型,该类型的值和指针都可以调用,不必严格符合接收者的类型。
package main
import "fmt"
type Person struct {
age int
}
func (p Person) Elegance() int {
return p.age
}
func (p *Person) GetAge() {
p.age += 1
}
func main() {
// p1 是值类型
p := Person{age: 18}
// 值类型 调用接收者也是值类型的方法
fmt.Println(p.howOld())
// 值类型 调用接收者是指针类型的方法
p.GetAge()
fmt.Println(p.GetAge())
// ----------------------
// p2 是指针类型
p2 := &Person{age: 100}
// 指针类型 调用接收者是值类型的方法
fmt.Println(p2.GetAge())
// 指针类型 调用接收者也是指针类型的方法
p2.GetAge()
fmt.Println(p2.GetAge())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
运行
18
19
100
101
2
3
4
| 函数和方法 | 值接收者 | 指针接收者 |
|---|---|---|
| 值类型调用者 | 方法会使用调用者的一个副本,类似于“传值” | 使用值的引用来调用方法,上例中,p1.GetAge() 实际上是 (&p1).GetAge(). |
| 指针类型调用者 | 指针被解引用为值,上例中,p2.GetAge()实际上是 (*p1).GetAge() | 实际上也是“传值”,方法里的操作会影响到调用者,类似于指针传参,拷贝了一份指针 |
如果实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的方法。
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;如果方法的接收者是指针类型,则调用者修改的是指针指向的对象本身。
通常我们使用指针作为方法的接收者的理由:
-
使用指针方法能够修改接收者指向的值。
-
可以避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做会更加高效。
因而呢,我们是使用值接收者还是指针接收者,不是由该方法是否修改了调用者(也就是接收者)来决定,而是应该基于该类型的本质。
如果类型具备“原始的本质”,也就是说它的成员都是由 Go 语言里内置的原始类型,如字符串,整型值等,那就定义值接收者类型的方法。像内置的引用类型,如 slice,map,interface,channel,这些类型比较特殊,声明他们的时候,实际上是创建了一个 header, 对于他们也是直接定义值接收者类型的方法。这样,调用函数时,是直接 copy 了这些类型的 header,而 header 本身就是为复制设计的。
如果类型具备非原始的本质,不能被安全地复制,这种类型总是应该被共享,那就定义指针接收者的方法。比如 go 源码里的文件结构体(struct File)就不应该被复制,应该只有一份实体。
接口值的零值是指动态类型和动态值都为 nil。当仅且当这两部分的值都为 nil 的情况下,这个接口值就才会被认为 接口值 == nil。
31.Go的对象在内存中是怎样分配的?
Go中的内存分类并不像TCMalloc那样分成小、中、大对象,但是它的小对象里又细分了一个Tiny对象,Tiny对象指大小在1Byte到16Byte之间并且不包含指针的对象。
小对象和大对象只用大小划定,无其他区分。
大对象指大小大于32kb.小对象是在mcache中分配的,而大对象是直接从mheap分配的,从小对象的内存分配看起。
Go的内存分配原则:
Go在程序启动的时候,会先向操作系统申请一块内存(注意这时还只是一段虚拟的地址空间,并不会真正地分配内存),切成小块后自己进行管理。
申请到的内存块被分配了三个区域,在X64上分别是512MB,16GB,512GB大小。
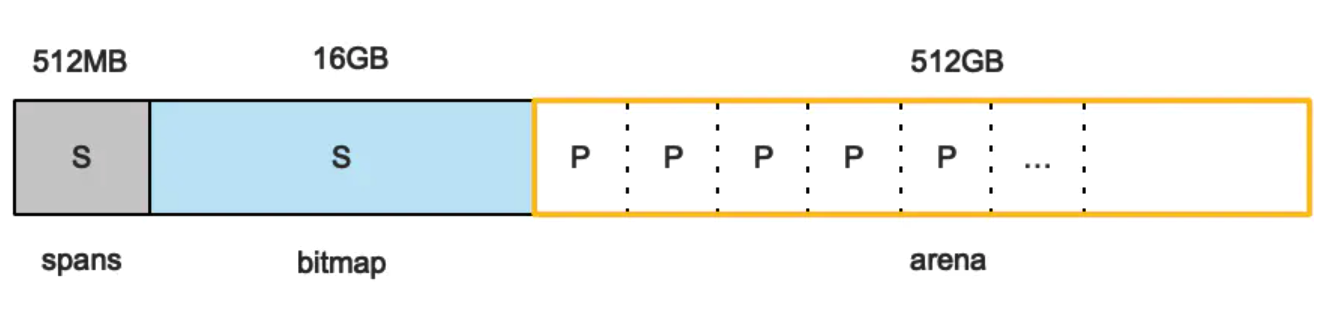
arena区域就是我们所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成8KB大小的页,一些页组合起来称为mspan。
bitmap区域标识arena区域哪些地址保存了对象,并且用4bit标志位表示对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为 8B )的内存,所以bitmap区域的大小是512GB/(4*8B)=16GB。

此外我们还可以看到bitmap的高地址部分指向arena区域的低地址部分,这里bitmap的地址是由高地址向低地址增长的。
spans区域存放mspan(是一些arena分割的页组合起来的内存管理基本单元,后文会再讲)的指针,每个指针对应一页,所以spans区域的大小就是 512GB/8KB*8B=512MB。
除以8KB是计算arena区域的页数,而最后乘以8是计算spans区域所有指针的大小。创建mspan的时候,按页填充对应的spans区域,在回收object时,根据地址很容易就能找到它所属的mspan。

32.栈的内存是怎么分配的?
栈和堆只是虚拟内存上2块不同功能的内存区域:
-
栈在高地址,从高地址向低地址增长。
-
堆在低地址,从低地址向高地址增长。
栈和堆相比优势:
- 栈的内存管理简单,分配比堆上快。
- 栈的内存不需要回收,而堆需要,无论是主动free,还是被动的垃圾回收,这都需要花费额外的CPU。
- 栈上的内存有更好的局部性,堆上内存访问就不那么友好了,CPU访问的2块数据可能在不同的页上,CPU访问数据的时间可能就上去了。
33.堆内存管理怎么分配的?
通常在Golang中,当我们谈论内存管理的时候,主要是指堆内存的管理,因为栈的内存管理不需要程序去操心。
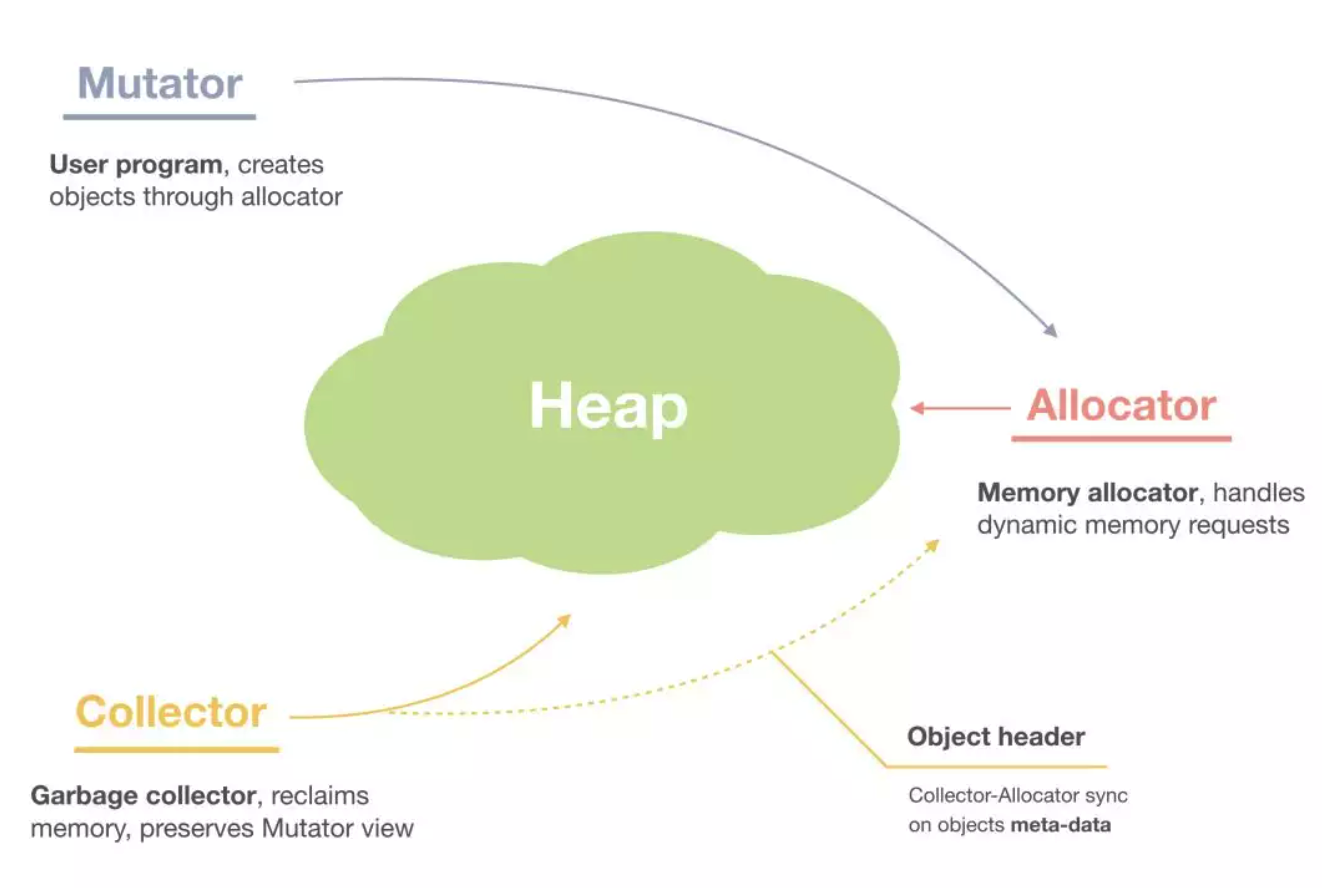
堆内存管理中主要是三部分, 1.分配内存块,2.回收内存块, 3.组织内存块。
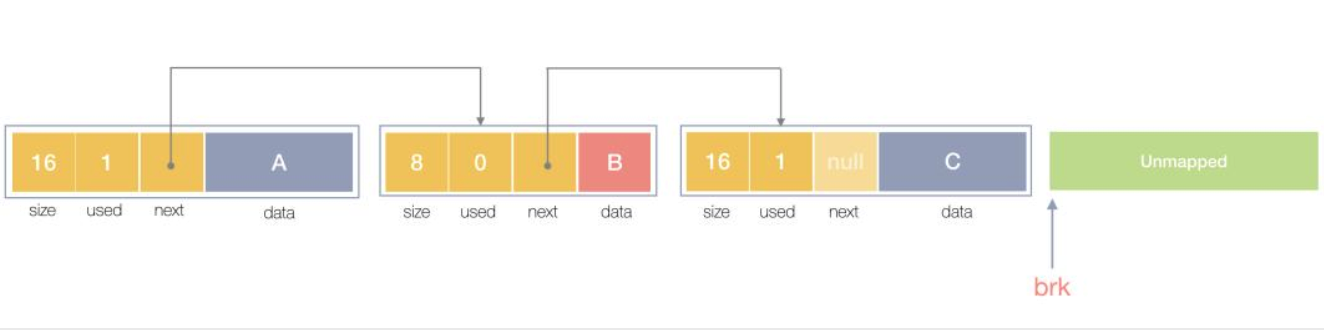
一个内存块包含了3类信息,如下图所示,元数据、用户数据和对齐字段,内存对齐是为了提高访问效率。下图申请5Byte内存的时候,就需要进行内存对齐。
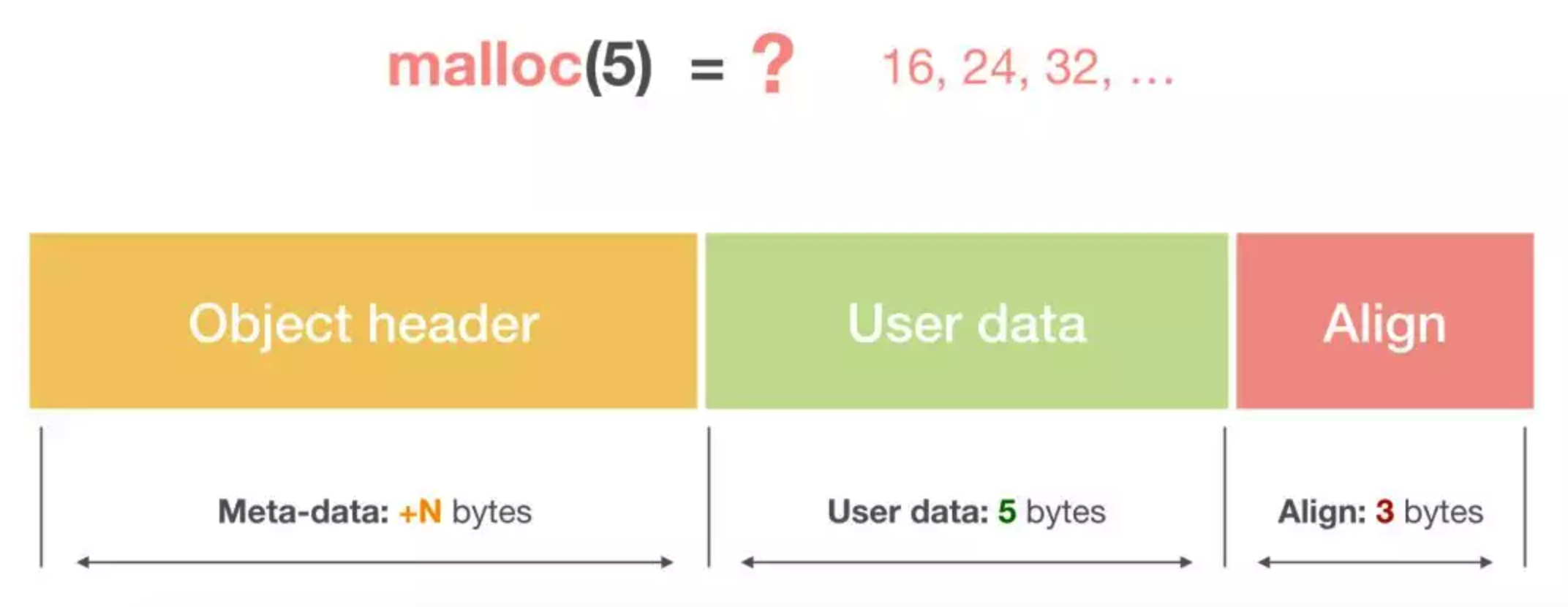
释放内存实质是把使用的内存块从链表中取出来,然后标记为未使用,当分配内存块的时候,可以从未使用内存块中有先查找大小相近的内存块,如果找不到,再从未分配的内存中分配内存。
上面这个简单的设计中还没考虑内存碎片的问题,因为随着内存不断的申请和释放,内存上会存在大量的碎片,降低内存的使用率。为了解决内存碎片,可以将2个连续的未使用的内存块合并,减少碎片。
想要深入了解可以看下这个文章,《Writing a Memory Allocator》.
34.在Go函数中为什么会发生内存泄露?
通常内存泄漏,指的是能够预期的能很快被释放的内存由于附着在了长期存活的内存上、或生命期意外地被延长,导致预计能够立即回收的内存而长时间得不到回收。
在 Go 中,由于 goroutine 的存在,因此,内存泄漏除了附着在长期对象上之外,还存在多种不同的形式。
- 预期能被快速释放的内存因被根对象引用而没有得到迅速释放.
当有一个全局对象时,可能不经意间将某个变量附着在其上,且忽略的将其进行释放,则该内存永远不会得到释放。
- goroutine 泄漏
Goroutine 作为一种逻辑上理解的轻量级线程,需要维护执行用户代码的上下文信息。在运行过程中也需要消耗一定的内存来保存这类信息,而这些内存在目前版本的 Go 中是不会被释放的。
因此,如果一个程序持续不断地产生新的 goroutine、且不结束已经创建的 goroutine 并复用这部分内存,就会造成内存泄漏的现象.
例如:
func main() {
for i := 0; i < 10000; i++ {
go func() {
select {}
}()
}
}35.G0的作用?
在Go中 g0作为一个特殊的goroutine,为 scheduler 执行调度循环提供了场地(栈)。对于一个线程来说,g0 总是它第一个创建的 goroutine。
之后,它会不断地寻找其他普通的 goroutine 来执行,直到进程退出。
当需要执行一些任务,且不想扩栈时,就可以用到 g0 了,因为 g0 的栈比较大。
g0 其他的一些“职责”有:创建 goroutine、deferproc 函数里新建 _defer、垃圾回收相关的工作(例如 stw、扫描 goroutine 的执行栈、一些标识清扫的工作、栈增长)等等。
36.Go中的锁如何实现
锁是一种同步机制,用于在多任务环境中限制资源的访问,以满足互斥需求。
go源码sync包中经常用于同步操作的方式:
- 原子操作
- 互斥锁
- 读写锁
- waitgroup
我们着重来分析下互斥锁和读写锁.
互斥锁:
下面是互斥锁的数据结构:
// A Mutex is a mutual exclusion lock.
// The zero value for a Mutex is an unlocked mutex.
//
// A Mutex must not be copied after first use.
type Mutex struct {
state int32 // 互斥锁上锁状态枚举值如下所示
sema uint32 // 信号量,向处于Gwaitting的G发送信号
}
const (
mutexLocked = 1 << iota // 值为1,表示在state中由低向高第1位,意义:锁是否可用,0可用,1不可用,锁定中
mutexWoken // 值为2,表示在state中由低向高第2位,意义:mutex是否被唤醒
mutexStarving // 当前的互斥锁进入饥饿状态;
mutexWaiterShift = iota //值为2,表示state中统计阻塞在此mutex上goroutine的数目需要位移的偏移量
starvationThresholdNs = 1e6
2
3
4
5
6
7
8
9
10
11
12
13
14
state和sema两个加起来只占 8 字节空间的结构体表示了 Go 语言中的互斥锁。
互斥锁的状态比较复杂,如下图所示,最低三位分别表示 mutexLocked、mutexWoken 和 mutexStarving,剩下的位置用来表示当前有多少个 Goroutine 等待互斥锁的释放.
在默认情况下,互斥锁的所有状态位都是 0,int32 中的不同位分别表示了不同的状态:
- mutexLocked 表示互斥锁的锁定状态;
- mutexWoken 表示从正常模式被从唤醒;
- mutexStarving 当前的互斥锁进入饥饿状态;
- waitersCount 当前互斥锁上等待的 Goroutine 个数;
sync.Mutex 有两种模式,正常模式和饥饿模式。
在正常模式下,锁的等待者会按照先进先出的顺序获取锁。
但是刚被唤起的 Goroutine 与新创建的 Goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现,一旦 Goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式,防止部分 Goroutine 被饿死。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。
如果一个 Goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会被切换回正常模式。
相比于饥饿模式,正常模式下的互斥锁能够提供更好地性能,饥饿模式的能避免 Goroutine 由于陷入等待无法获取锁而造成的高尾延时。
互斥锁的加锁是靠 sync.Mutex.Lock 方法完成的, 当锁的状态是 0 时,将 mutexLocked 位置成 1:
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
如果互斥锁的状态不是 0 时就会调用 sync.Mutex.lockSlow 尝试通过自旋(Spinnig)等方式等待锁的释放,
这个方法是一个非常大 for 循环,它获取锁的过程:
- 判断当前 Goroutine 能否进入自旋;
- 通过自旋等待互斥锁的释放;
- 计算互斥锁的最新状态;
- 更新互斥锁的状态并获取锁;
那么互斥锁是如何判断当前 Goroutine 能否进入自旋等互斥锁的释放,是通过它的lockSlow方法, 由于自旋是一种多线程同步机制,所以呢当前的进程在进入自旋的过程中会一直保持对 CPU 的占用,持续检查某个条件是否为真。 通常在多核的 CPU 上,自旋可以避免 Goroutine 的切换,使用得当会对性能带来很大的增益,但是往往使用的不得当就会拖慢整个程序.
所以 Goroutine 进入自旋的条件非常苛刻:
- 互斥锁只有在普通模式才能进入自旋;
runtime.sync_runtime_canSpin需要返回 true: a. 需要运行在多 CPU 的机器上; b. 当前的Goroutine 为了获取该锁进入自旋的次数小于四次; c. 当前机器上至少存在一个正在运行的处理器 P 并且处理的运行队列为空;
一旦当前 Goroutine 能够进入自旋就会调用runtime.sync_runtime_doSpin 和 runtime.procyield 并执行 30 次的 PAUSE 指令,该指令只会占用 CPU 并消耗 CPU 时间.
处理了自旋相关的特殊逻辑之后,互斥锁会根据上下文计算当前互斥锁最新的状态。
通过几个不同的条件分别会更新 state 字段中存储的不同信息,mutexLocked、mutexStarving、mutexWoken 和 mutexWaiterShift:
new := old
if old&mutexStarving == 0 {
new |= mutexLocked
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
new &^= mutexWoken
}
2
3
4
5
6
7
8
9
10
11
12
13
计算了新的互斥锁状态之后,就会使用 CAS 函数 sync/atomic.CompareAndSwapInt32 更新该状态:
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&(mutexLocked|mutexStarving) == 0 {
break // 通过 CAS 函数获取了锁
}
...
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如果我们没有通过 CAS 获得锁,会调用 runtime.sync_runtime_SemacquireMutex 使用信号量保证资源不会被两个 Goroutine 获取。
runtime.sync_runtime_SemacquireMutex 会在方法中不断调用尝试获取锁并休眠当前 Goroutine 等待信号量的释放,一旦当前 Goroutine 可以获取信号量,它就会立刻返回,sync.Mutex.Lock 方法的剩余代码也会继续执行。
在正常模式下,这段代码会设置唤醒和饥饿标记、重置迭代次数并重新执行获取锁的循环. 在饥饿模式下,当前 Goroutine 会获得互斥锁,如果等待队列中只存在当前 Goroutine,互斥锁还会从饥饿模式中退出.
互斥锁的解锁过程 sync.Mutex.Unlock 与加锁过程相比就很简单,该过程会先使用 sync/atomic.AddInt32 函数快速解锁,这时会发生下面的两种情况:
- 如果该函数返回的新状态等于 0,当前 Goroutine 就成功解锁了互斥锁;
- 如果该函数返回的新状态不等于 0,这段代码会调用
sync.Mutex.unlockSlow方法开始慢速解锁:
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
sync.Mutex.unlockSlow 方法首先会校验锁状态的合法性, 如果当前互斥锁已经被解锁过了就会直接抛出异常 sync: unlock of unlocked mutex 中止当前程序。
在正常情况下会根据当前互斥锁的状态,分别处理正常模式和饥饿模式下的互斥锁.
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
old := new
for {
// If there are no waiters or a goroutine has already
// been woken or grabbed the lock, no need to wake anyone.
// In starvation mode ownership is directly handed off from unlocking
// goroutine to the next waiter. We are not part of this chain,
// since we did not observe mutexStarving when we unlocked the mutex above.
// So get off the way.
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// Grab the right to wake someone.
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
// Starving mode: handoff mutex ownership to the next waiter, and yield
// our time slice so that the next waiter can start to run immediately.
// Note: mutexLocked is not set, the waiter will set it after wakeup.
// But mutex is still considered locked if mutexStarving is set,
// so new coming goroutines won't acquire it.
runtime_Semrelease(&m.sema, true, 1)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
在正常模式下,这段代码会分别处理以下两种情况处理:
- 如果互斥锁不存在等待者或者互斥锁的
mutexLocked、mutexStarving、mutexWoken状态不都为 0,那么当前方法就可以直接返回,不需要唤醒其他等待者; - 如果互斥锁存在等待者,会通过
sync.runtime_Semrelease唤醒等待者并移交锁的所有权;
在饥饿模式下,上述代码会直接调用 sync.runtime_Semrelease 方法将当前锁交给下一个正在尝试获取锁的等待者,等待者被唤醒后会得到锁,在这时互斥锁还不会退出饥饿状态;
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念:
- 如果互斥锁处于初始化状态,就会直接通过置位 mutexLocked 加锁;
- 如果互斥锁处于 mutexLocked 并且在普通模式下工作,就会进入自旋,执行 30 次 PAUSE 指令消耗 CPU 时间等待锁的释放;
- 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过
runtime.sync_runtime_SemacquireMutex函数将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒当前 Goroutine; - 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,当前 Goroutine 会将互斥锁切换回正常模式;
互斥锁的解锁过程与之相比就比较简单,其代码行数不多、逻辑清晰,也比较容易理解:
- 当互斥锁已经被解锁时,那么调用
sync.Mutex.Unlock会直接抛出异常; - 当互斥锁处于饥饿模式时,会直接将锁的所有权交给队列中的下一个等待者,等待者会负责设置
mutexLocked标志位; - 当互斥锁处于普通模式时,如果没有 Goroutine 等待锁的释放或者已经有被唤醒的 Goroutine 获得了锁,就会直接返回;在其他情况下会通过
sync.runtime_Semrelease唤醒对应的 Goroutine.
读写锁:
读写互斥锁sync.RWMutex 是细粒度的互斥锁,它不限制资源的并发读,但是读写、写写操作无法并行执行。
sync.RWMutex 中总共包含5 个字段:
type RWMutex struct {
w Mutex // 复用互斥锁提供的能力
writerSem uint32 // 写等待读
readerSem uint32 // 读等待写
readerCount int32 // 存储了当前正在执行的读操作的数量
readerWait int32 // 当写操作被阻塞时等待的读操作个数
}
2
3
4
5
6
7
我们从写锁开始分析:
当我们想要获取写锁时,需要调用 sync.RWMutex.Lock 方法:
func (rw *RWMutex) Lock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
// First, resolve competition with other writers.
rw.w.Lock()
// Announce to readers there is a pending writer.
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// Wait for active readers.
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
race.Acquire(unsafe.Pointer(&rw.writerSem))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 这里调用结构体持有的
sync.Mutex的sync.Mutex.Lock方法阻塞后续的写操作;
因为互斥锁已经被获取,其他 Goroutine 在获取写锁时就会进入自旋或者休眠;
- 调用
sync/atomic.AddInt32方法阻塞后续的读操作:
如果仍然有其他 Goroutine 持有互斥锁的读锁(r != 0),该 Goroutine 会调用 runtime.sync_runtime_SemacquireMutex 进入休眠状态等待所有读锁所有者执行结束后释放 writerSem 信号量将当前协程唤醒。
写锁的释放会调用 sync.RWMutex.Unlock 方法:
func (rw *RWMutex) Unlock() {
if race.Enabled {
_ = rw.w.state
race.Release(unsafe.Pointer(&rw.readerSem))
race.Disable()
}
// Announce to readers there is no active writer.
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
if r >= rwmutexMaxReaders {
race.Enable()
throw("sync: Unlock of unlocked RWMutex")
}
// Unblock blocked readers, if any.
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
rw.w.Unlock()
if race.Enabled {
race.Enable()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
解锁与加锁的过程正好相反,写锁的释放分为以下几个步骤:
- 调用
sync/atomic.AddInt32函数将readerCount变回正数,释放读锁; - 通过 for 循环触发所有由于获取读锁而陷入等待的 Goroutine:
- 调用
sync.Mutex.Unlock方法释放写锁;
获取写锁时会先阻塞写锁的获取,后阻塞读锁的获取,这种策略能够保证读操作不会被连续的写操作饿死。
接着是读锁:
读锁的加锁方法 sync.RWMutex.RLock 就比较简单了,该方法会通过 sync/atomic.AddInt32 将 readerCount 加一:
func (rw *RWMutex) RLock() {
if race.Enabled {
_ = rw.w.state
race.Disable()
}
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
if race.Enabled {
race.Enable()
race.Acquire(unsafe.Pointer(&rw.readerSem))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
如果RLock该方法返回负数,其他 Goroutine 获得了写锁,当前 Goroutine 就会调用runtime.sync_runtime_SemacquireMutex 陷入休眠等待锁的释放; 如果RLock该方法的结果为非负数,没有 Goroutine 获得写锁,当前方法就会成功返回.
当 Goroutine 想要释放读锁时,会调用如下所示的RUnlock方法:
func (rw *RWMutex) RUnlock() {
if race.Enabled {
_ = rw.w.state
race.ReleaseMerge(unsafe.Pointer(&rw.writerSem))
race.Disable()
}
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
if race.Enabled {
race.Enable()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
该方法会先减少正在读资源的readerCount 整数,根据 sync/atomic.AddInt32 的返回值不同会分别进行处理:
- 如果返回值大于等于零,表示读锁直接解锁成功.
- 如果返回值小于零 ,表示有一个正在执行的写操作,在这时会调用
rUnlockSlow方法.
func (rw *RWMutex) rUnlockSlow(r int32) {
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
race.Enable()
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
2
3
4
5
6
7
8
9
10
11
rUnlockSlow该方法会减少获取锁的写操作等待的读操作数readerWait并在所有读操作都被释放之后触发写操作的信号量,writerSem,该信号量被触发时,调度器就会唤醒尝试获取写锁的 Goroutine。
其实读写互斥锁(sync.RWMutex),虽然提供的功能非常复杂,不过因为它是在互斥锁( sync.Mutex)的基础上,所以整体的实现上会简单很多。
因此呢:
- 调用
sync.RWMutex.Lock尝试获取写锁时;
每次 sync.RWMutex.RUnlock 都会将 readerCount 其减一,当它归零时该 Goroutine 就会获得写锁, 将 readerCount 减少 rwmutexMaxReaders 个数以阻塞后续的读操作.
- 调用
sync.RWMutex.Unlock释放写锁时,会先通知所有的读操作,然后才会释放持有的互斥锁;
读写互斥锁在互斥锁之上提供了额外的更细粒度的控制,能够在读操作远远多于写操作时提升性能。
37.Go中的channel的实现
在Go中最常见的就是通信顺序进程(Communicating sequential processes,CSP)的并发模型,通过共享通信,来实现共享内存,这里就提到了channel.
Goroutine 和 Channel 分别对应 CSP 中的实体和传递信息的媒介,Go 语言中的 Goroutine 会通过 Channel 传递数据。
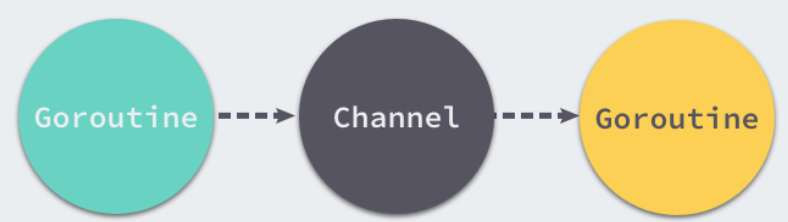
Goroutine通过使用channel传递数据,一个会向 Channel 中发送数据,另一个会从 Channel 中接收数据,它们两者能够独立运行并不存在直接关联,但是能通过 Channel 间接完成通信。
Channel 收发操作均遵循了先入先出(FIFO)的设计,具体规则如下:
- 先从 Channel 读取数据的 Goroutine 会先接收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
Channel 通常会有以下三种类型:
- 同步 Channel — 不需要缓冲区,发送方会直接将数据交给(Handoff)接收方;
- 异步 Channel — 基于环形缓存的传统生产者消费者模型;
chan struct{}类型的异步Channel的struct{}类型不占用内存空间,不需要实现缓冲区和直接发送(Handoff)的语义;
Channel 在运行时使用 runtime.hchan 结构体表示:
type hchan struct {
qcount uint // 当前队列里还剩余元素个数
dataqsiz uint // 环形队列长度,即缓冲区的大小,即make(chan T,N) 中的N
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识当前通道是否处于关闭状态,创建通道后,该字段设置0,即打开通道;通道调用close将其设置为1,通道关闭
elemtype *_type // 元素类型,用于数据传递过程中的赋值
sendx uint // 环形缓冲区的状态字段,它只是缓冲区的当前索引-支持数组,它可以从中发送数据
recvx uint // 环形缓冲区的状态字段,它只是缓冲区当前索引-支持数组,它可以从中接受数据
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex // 互斥锁,为每个读写操作锁定通道,因为发送和接受必须是互斥操作
}
type waitq struct {
first *sudog
last *sudog
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
其中hchan结构体中有五个字段是构建底层的循环队列:
* qcount — Channel 中的元素个数;
* dataqsiz — Channel 中的循环队列的长度;
* buf — Channel 的缓冲区数据指针;
* sendx — Channel 的发送操作处理到的位置;
* recvx — Channel 的接收操作处理到的位置;
2
3
4
5
通常, elemsize 和 elemtype 分别表示当前 Channel 能够收发的元素类型和大小.
sendq 和 recvq 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表runtime.waitq表示,链表中所有的元素都是runtime.sudog结构.
waitq 表示一个在等待列表中的 Goroutine,该结构体中存储了阻塞的相关信息以及两个分别指向前后runtime.sudog的指针。
channel 在Go中是通过make关键字创建,编译器会将make(chan int,10).
创建管道:
runtime.makechan 和 runtime.makechan64 会根据传入的参数类型和缓冲区大小创建一个新的 Channel 结构,其中后者用于处理缓冲区大小大于 2 的 32 次方的情况.
这里我们来详细看下makechan 函数:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// compiler checks this but be safe.
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// Hchan does not contain pointers interesting for GC when elements stored in buf do not contain pointers.
// buf points into the same allocation, elemtype is persistent.
// SudoG's are referenced from their owning thread so they can't be collected.
// TODO(dvyukov,rlh): Rethink when collector can move allocated objects.
var c *hchan
switch {
case mem == 0:
// Queue or element size is zero.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// Race detector uses this location for synchronization.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// Elements do not contain pointers.
// Allocate hchan and buf in one call.
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// Elements contain pointers.
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
Channel 中根据收发元素的类型和缓冲区的大小初始化 runtime.hchan 结构体和缓冲区:
arena区域就是我们所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成8KB大小的页,一些页组合起来称为mspan。
bitmap区域标识arena区域哪些地址保存了对象,并且用4bit标志位表示对象是否包含指针、GC标记信息。bitmap中一个byte大小的内存对应arena区域中4个指针大小(指针大小为 8B )的内存,所以bitmap区域的大小是512GB/(4*8B)=16GB。
此外我们还可以看到bitmap的高地址部分指向arena区域的低地址部分,这里bitmap的地址是由高地址向低地址增长的。
spans区域存放mspan(是一些arena分割的页组合起来的内存管理基本单元,后文会再讲)的指针,每个指针对应一页,所以spans区域的大小就是512GB/8KB*8B=512MB。
除以8KB是计算arena区域的页数,而最后乘以8是计算spans区域所有指针的大小。创建mspan的时候,按页填充对应的spans区域,在回收object时,根据地址很容易就能找到它所属的mspan。
40.Go中的map的实现
Go中Map是一个KV对集合。底层使用hash table,用链表来解决冲突 ,出现冲突时,不是每一个Key都申请一个结构通过链表串起来,而是以bmap为最小粒度挂载,一个bmap可以放8个kv。
在哈希函数的选择上,会在程序启动时,检测 cpu 是否支持 aes,如果支持,则使用aes hash,否则使用memhash。
hash函数,有加密型和非加密型。加密型的一般用于加密数据、数字摘要等,典型代表就是md5、sha1、sha256、aes256 这种,非加密型的一般就是查找。
在map的应用场景中,用的是查找。
选择hash函数主要考察的是两点:性能、碰撞概率。
2
3
4
5
每个map的底层结构是hmap,是有若干个结构为bmap的bucket组成的数组。每个bucket底层都采用链表结构。
type hmap struct {
count int // 元素个数
flags uint8 // 用来标记状态
B uint8 // 扩容常量相关字段B是buckets数组的长度的对数 2^B
noverflow uint16 // noverflow是溢出桶的数量,当B<16时,为精确值,当B>=16时,为估计值
hash0 uint32 // 是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入
buckets unsafe.Pointer // 桶的地址
oldbuckets unsafe.Pointer // 旧桶的地址,用于扩容
nevacuate uintptr // 搬迁进度,扩容需要将旧数据搬迁至新数据,这里是利用指针来比较判断有没有迁移
extra *mapextra // 用于扩容的指针
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8 // tophash用于记录8个key哈希值的高8位,这样在寻找对应key的时候可以更快,不必每次都对key做全等判断
}
//实际上编辑期间会动态生成一个新的结构体
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的,关于key的定位我们在map的查询和赋值中详细说明。
在桶内,又会根据key计算出来的hash值的高8位来决定 key到底落入桶内的哪个位置(一个桶内最多有8个位置)。
当map的key和value都不是指针,并且 size都小于128字节的情况下,会把bmap标记为不含指针,这样可以避免gc时扫描整个hmap。
但是,我们看bmap其实有一个overflow的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把overflow移动到 hmap的extra 字段来。
这样随着哈希表存储的数据逐渐增多,我们会扩容哈希表或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
哈希表作为一种数据结构,我们肯定要分析它的常见操作,首先就是读写操作的原理。哈希表的访问一般都是通过下标或者遍历进行的:
_ = hash[key]
for k, v := range hash {
// k, v
}
2
3
4
5
这两种方式虽然都能读取哈希表的数据,但是使用的函数和底层原理完全不同。
第一个需要知道哈希的键并且一次只能获取单个键对应的值,而第二个可以遍历哈希中的全部键值对,访问数据时也不需要预先知道哈希的键。
在编译的类型检查期间,hash[key] 以及类似的操作都会被转换成哈希的 OINDEXMAP 操作,中间代码生成阶段会在 cmd/compile/internal/gc.walkexpr 函数中将这些 OINDEXMAP 操作转换成如下的代码:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)
2
这里根据赋值语句左侧接受参数的个数会决定使用的运行时方法:
当接受一个参数时,会使用 runtime.mapaccess1,该函数仅会返回一个指向目标值的指针; 当接受两个参数时,会使用 runtime.mapaccess2,除了返回目标值之外,它还会返回一个用于表示当前键对应的值是否存在的 bool 值:
mapaccess1 会先通过哈希表设置的哈希函数、种子获取当前键对应的哈希,再通过 runtime.bucketMask 和 runtime.add 拿到该键值对所在的桶序号和哈希高位的 8 位数字。
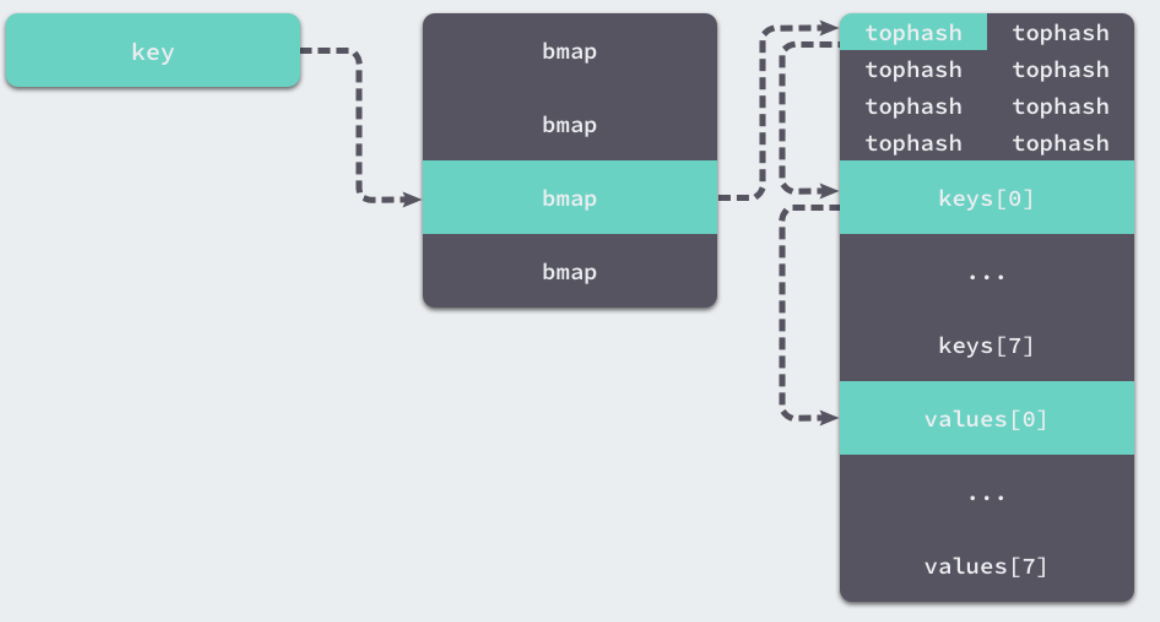
如果在bucket中没有找到,此时如果overflow不为空,那么就沿着overflow继续查找,如果还是没有找到,那就从别的key槽位查找,直到遍历所有bucket。
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
//如果h说明都没有,返回零值
if h == nil || h.count == 0 {
if t.hashMightPanic() { //如果哈希函数出错
t.key.alg.hash(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
//写和读冲突
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
//不同类型的key需要不同的hash算法需要在编译期间确定
alg := t.key.alg
//利用hash0引入随机性,计算哈希值
hash := alg.hash(key, uintptr(h.hash0))
//比如B=5那m就是31二进制是全1,
//求bucket num时,将hash与m相与,
//达到bucket num由hash的低8位决定的效果,
//bucketMask函数掩蔽了移位量,省略了溢出检查。
m := bucketMask(h.B)
//b即bucket的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// oldbuckets 不为 nil,说明发生了扩容
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
//新的bucket是旧的bucket两倍
m >>= 1
}
//求出key在旧的bucket中的位置
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
//如果旧的bucket还没有搬迁到新的bucket中,那就在老的bucket中寻找
if !evacuated(oldb) {
b = oldb
}
}
//计算tophash高8位
top := tophash(hash)
bucketloop:
//遍历所有overflow里面的bucket
for ; b != nil; b = b.overflow(t) {
//遍历8个bucket
for i := uintptr(0); i < bucketCnt; i++ {
//tophash不匹配,继续
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
//tophash匹配,定位到key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
//若key为指针
if t.indirectkey() {
//解引用
k = *((*unsafe.Pointer)(k))
}
//key相等
if alg.equal(key, k) {
//定位value的位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
//value解引用
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
//没有找到,返回0值
return unsafe.Pointer(&zeroVal[0])
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
在 bucketloop 循环中,哈希会依次遍历正常桶和溢出桶中的数据,它先会比较哈希的高 8 位和桶中存储的 tophash,后比较传入的和桶中的值以加速数据的读写。用于选择桶序号的是哈希的最低几位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能。
因此bucket里key的起始地址就是unsafe.Pointer(b)+dataOffset;第i个key的地址就要此基础上加i个key大小;value的地址是在key之后,所以第i个value,要加上所有的key的偏移。
另一个同样用于访问哈希表中数据的 runtime.mapaccess2 只是在 runtime.mapaccess1 的基础上多返回了一个标识键值对是否存在的 bool 值:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
...
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e, true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
使用 v, ok := hash[k]的形式访问哈希表中元素时,我们能够通过这个布尔值更准确地知道当 v == nil 时,v 到底是哈希中存储的元素还是表示该键对应的元素不存在,所以在访问哈希时,我们更推荐使用这种方式判断元素是否存在。
写入:
当形如 hash[k] 的表达式出现在赋值符号左侧时,该表达式也会在编译期间转换成 mapassign 函数的调用,该函数与 mapaccess1 比较相似:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
我们可以通过遍历比较桶中存储的tophash 和键的哈希,如果找到了相同结果就会返回目标位置的地址。
如果当前桶已经满了,哈希会调用 newoverflow 创建新桶或者使用 hmap 预先在 noverflow 中创建好的桶来保存数据,新创建的桶不仅会被追加到已有桶的末尾,还会增加哈希表的 noverflow 计数器。
如果当前键值对在哈希中不存在,哈希会为新键值对规划存储的内存地址,通过typedmemmove 将键移动到对应的内存空间中并返回键对应值的地址 val。
如果当前键值对在哈希中存在,那么就会直接返回目标区域的内存地址,哈希并不会在mapassign 这个运行时函数中将值拷贝到桶中,该函数只会返回内存地址,真正的赋值操作是在编译期间插入的.
扩容:
随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存保证哈希的读写性能,这个时候我们就需要用到扩容了.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
...
}
// 装载因子超过 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// overflow buckets
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
mapassign 函数会在以下两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5;
- 哈希使用了太多溢出桶;
不过因为 Go 语言哈希的扩容不是一个原子的过程,所以mapassign 还需要判断当前哈希是否已经处于扩容状态,避免二次扩容造成混乱。
根据触发的条件不同扩容的方式分成两种,如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容sameSizeGrow,sameSizeGrow 是一种特殊情况下发生的扩容,当我们持续向哈希中插入数据并将它们全部删除时,如果哈希表中的数据量没有超过阈值,就会不断积累溢出桶造成缓慢的内存泄漏。
runtime: limit the number of map overflow buckets 引入了 sameSizeGrow 通过复用已有的哈希扩容机制解决该问题,一旦哈希中出现了过多的溢出桶,它会创建新桶保存数据,垃圾回收会清理老的溢出桶并释放内存\。
扩容的入口是 hashGrow:
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
// B+1 相当于是原来 2 倍的空间
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
// 进行等量的内存扩容,所以 B 不变
bigger = 0
h.flags |= sameSizeGrow
}
// 将老 buckets 挂到 buckets 上
oldbuckets := h.buckets
// 申请新的 buckets 空间
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
// 提交 grow 的动作
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 搬迁进度为 0
h.nevacuate = 0
// overflow buckets 数为 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
哈希在扩容的过程中会通过 makeBucketArray 创建一组新桶和预创建的溢出桶,随后将原有的桶数组设置到 oldbuckets 上并将新的空桶设置到 buckets 上,溢出桶也使用了相同的逻辑更新. 这里会申请到了新的 buckets 空间,把相关的标志位都进行了处理,例如标志 nevacuate 被置为 0, 表示当前搬迁进度为 0。
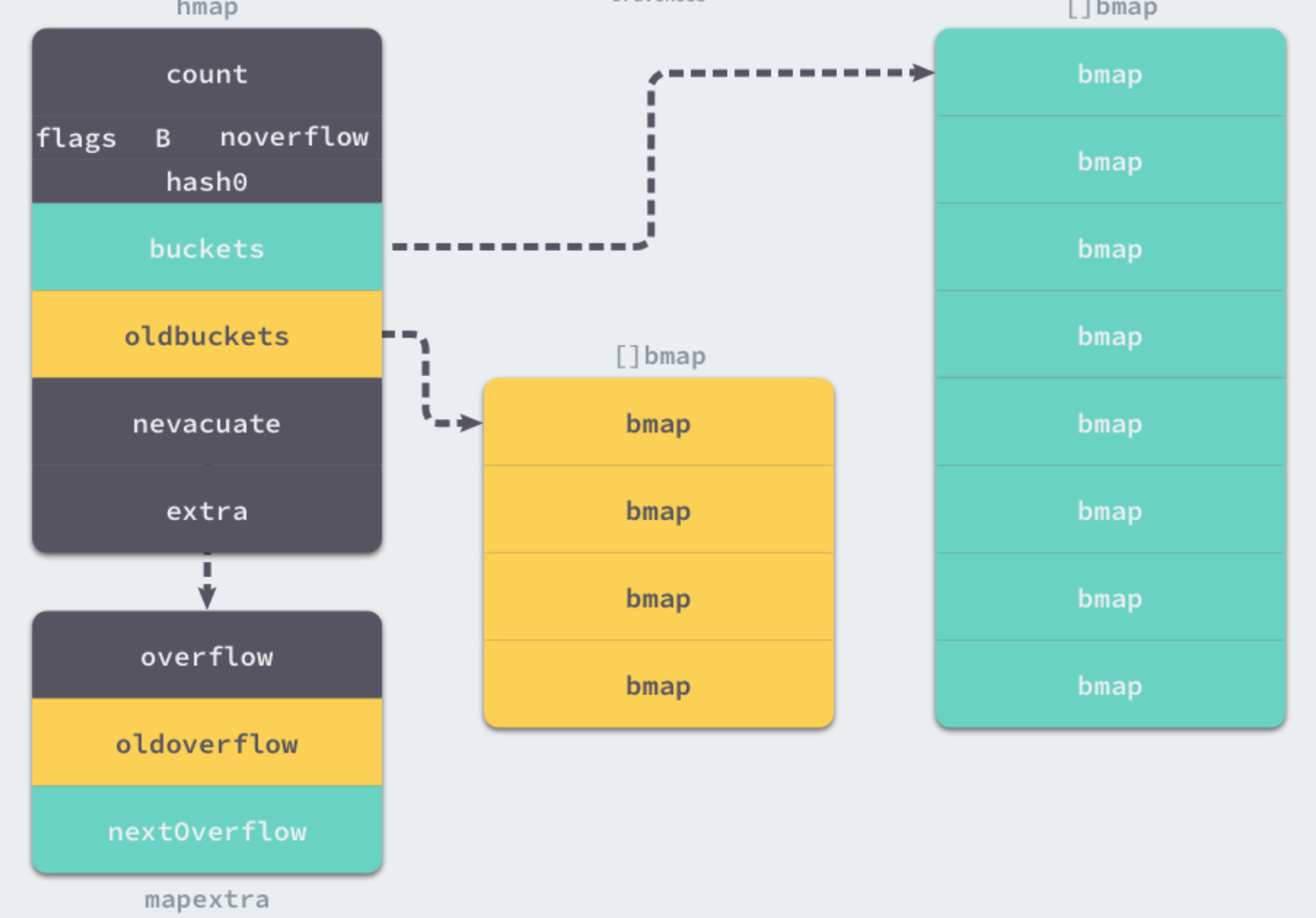
在hashGrow 中还看不出来等量扩容和翻倍扩容的太多区别,等量扩容创建的新桶数量只是和旧桶一样,该函数中只是创建了新的桶,并没有对数据进行拷贝和转移。
哈希表的数据迁移的过程在是 evacuate 中完成的,它会对传入桶中的元素进行再分配。
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 这里会定位老的 bucket 地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 结果是 2^B
newbit := h.noldbuckets()
// 如果吧没有搬迁过
if !evacuated(b) {
// TODO: reuse overflow buckets instead of using new ones, if there
// is no iterator using the old buckets. (If !oldIterator.)
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
// 如果不是等size 扩容,前后bucket序号有变,使用y 进行搬迁
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}
// 遍历所有老的bucket地址
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
// If key != key (NaNs), then the hash could be (and probably
// will be) entirely different from the old hash. Moreover,
// it isn't reproducible. Reproducibility is required in the
// presence of iterators, as our evacuation decision must
// match whatever decision the iterator made.
// Fortunately, we have the freedom to send these keys either
// way. Also, tophash is meaningless for these kinds of keys.
// We let the low bit of tophash drive the evacuation decision.
// We recompute a new random tophash for the next level so
// these keys will get evenly distributed across all buckets
// after multiple grows.
useY = top & 1
top = tophash(hash)
} else {
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
dst := &xy[useY] // evacuation destination
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
dst.i++
// These updates might push these pointers past the end of the
// key or elem arrays. That's ok, as we have the overflow pointer
// at the end of the bucket to protect against pointing past the
// end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
ptr := add(b, dataOffset)
n := uintptr(t.bucketsize) - dataOffset
memclrHasPointers(ptr, n)
}
}
if oldbucket == h.nevacuate {
advanceEvacuationMark(h, t, newbit)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
evacuate 会将一个旧桶中的数据分流到两个新桶,所以它会创建两个用于保存分配上下文的 evacDst 结构体,这两个结构体分别指向了一个新桶:
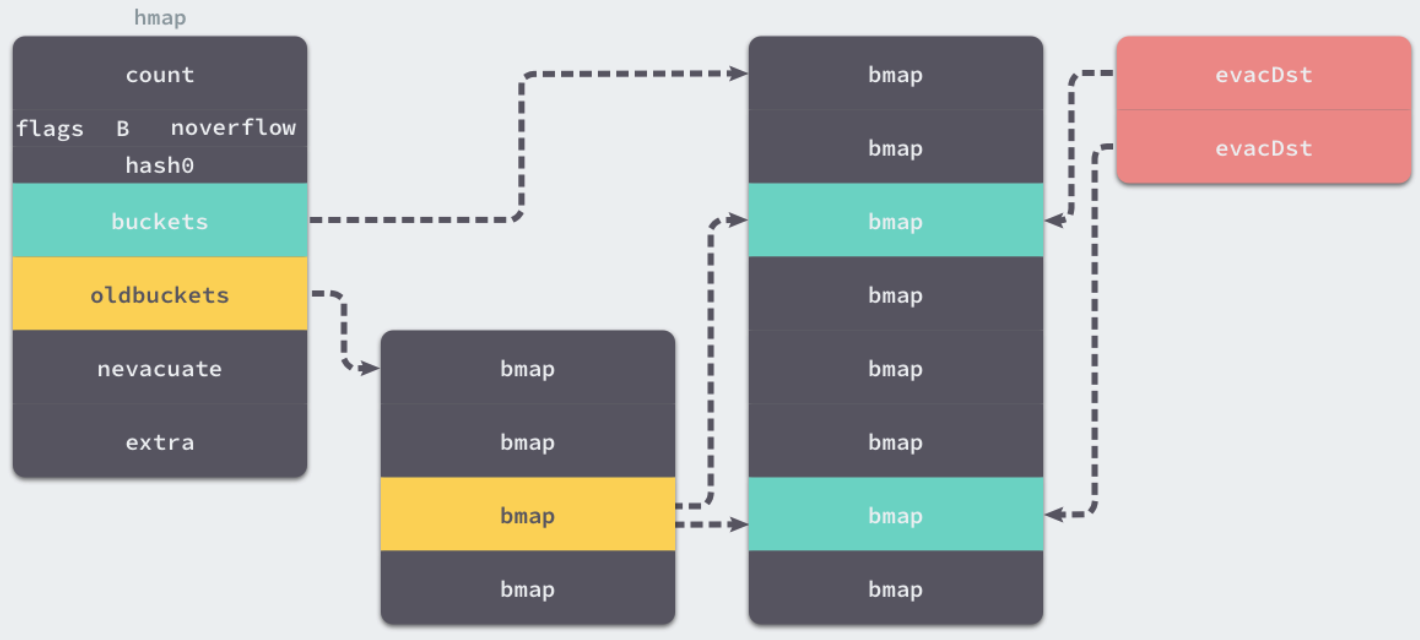
哈希表扩容目的:
如果这是等量扩容,那么旧桶与新桶之间是一对一的关系,所以两个evacDst只会初始化一个。而当哈希表的容量翻倍时,每个旧桶的元素会都分流到新创建的两个桶中.
只使用哈希函数是不能定位到具体某一个桶的,哈希函数只会返回很长的哈希,我们还需一些方法将哈希映射到具体的桶上。
那么如何定位key呢?
key 经过哈希计算后得到哈希值,共64个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。
如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32。
例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
用最后的 5 个bit 位,也就是01010,值为 10,那么这个就是10号桶。
再用哈希值的高 8 位,找到此 key 在bucket中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
buckets 编号就是桶编号,当两个不同的key落在同一个桶中,也就是发生了哈希冲突。
通常哈希冲突的解决手段是用链表法,在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
因此哈希表扩容的设计和原理,哈希在存储元素过多时会触发扩容操作,每次都会将桶的数量翻倍,扩容过程不是原子的,而是通过growWork 增量触发的,在扩容期间访问哈希表时会使用旧桶,向哈希表写入数据时会触发旧桶元素的分流。
除了这种正常的扩容之外,为了解决大量写入、删除造成的内存泄漏问题,哈希引入了sameSizeGrow 这一机制,在出现较多溢出桶时会整理哈希的内存减少空间的占用。
删除:
如果想要删除哈希中的元素,就需要使用 Go 语言中的 delete 关键字,这个关键字的唯一作用就是将某一个键对应的元素从哈希表中删除,无论是该键对应的值是否存在,这个内建的函数都不会返回任何的结果。
因此呢Go采用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。
哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为可以帮助哈希快速遍历桶中元素的缓存。
哈希表的每个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。
随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大损耗。
41.Go中的http包的实现原理?
Golang中http包中处理 HTTP 请求主要跟两个东西相关:ServeMux 和 Handler。
ServeMux 本质上是一个 HTTP 请求路由器(或者叫多路复用器,Multiplexor)。它把收到的请求与一组预先定义的 URL 路径列表做对比,然后在匹配到路径的时候调用关联的处理器(Handler)。
处理器(Handler)负责输出HTTP响应的头和正文。任何满足了http.Handler接口的对象都可作为一个处理器。通俗的说,对象只要有个如下签名的ServeHTTP方法即可:
ServeHTTP(http.ResponseWriter, *http.Request)
Go 语言的 HTTP 包自带了几个函数用作常用处理器,比如FileServer,NotFoundHandler 和 RedirectHandler。
应用示例:
package main
import (
"log"
"net/http"
)
func main() {
mux := http.NewServeMux()
rh := http.RedirectHandler("http://www.baidu.com", 307)
mux.Handle("/foo", rh)
log.Println("Listening...")
http.ListenAndServe(":3000", mux)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在这个应用示例中,首先在 main 函数中我们只用了 http.NewServeMux 函数来创建一个空的 ServeMux。 然后我们使用 http.RedirectHandler 函数创建了一个新的处理器,这个处理器会对收到的所有请求,都执行307重定向操作到 http://www.baidu.com。
接下来我们使用 ServeMux.Handle 函数将处理器注册到新创建的 ServeMux,所以它在 URL 路径/foo 上收到所有的请求都交给这个处理器。 最后我们创建了一个新的服务器,并通过 http.ListenAndServe 函数监听所有进入的请求,通过传递刚才创建的 ServeMux来为请求去匹配对应处理器。
在浏览器中访问 http://localhost:3000/foo,你应该能发现请求已经成功的重定向了。
此刻你应该能注意到一些有意思的事情:ListenAndServer 的函数签名是ListenAndServe(addr string, handler Handler) ,但是第二个参数我们传递的是个ServeMux。
通过这个例子我们就可以知道,net/http包在编写golang web应用中有很重要的作用,它主要提供了基于HTTP协议进行工作的client实现和server实现,可用于编写HTTP服务端和客户端。
42.Goroutine发生了泄漏如何检测?
通常内存泄漏,指的是能够预期的能很快被释放的内存由于附着在了长期存活的内存上、或生命期意外地被延长,导致预计能够立即回收的内存而长时间得不到回收。
在 Go 中,由于Goroutine的存在,因此,内存泄漏除了附着在长期对象上之外,还存在多种不同的形式。
- 预期能被快速释放的内存因被根对象引用而没有得到迅速释放.
当有一个全局对象时,可能不经意间将某个变量附着在其上,且忽略的将其进行释放,则该内存永远不会得到释放。
- Goroutine 泄漏
Goroutine 作为一种逻辑上理解的轻量级线程,需要维护执行用户代码的上下文信息。在运行过程中也需要消耗一定的内存来保存这类信息,而这些内存在目前版本的 Go 中是不会被释放的。
因此,如果一个程序持续不断地产生新的 goroutine、且不结束已经创建的 goroutine 并复用这部分内存,就会造成内存泄漏的现象.
可以通过Go自带的工具pprof或者使用Gops去检测诊断当前在系统上运行的Go进程的占用的资源.
43.Go函数返回局部变量的指针是否安全?
- 在 Go 中是安全的,Go 编译器将会对每个局部变量进行逃逸分析。如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上
44.Go中两个Nil可能不相等吗?
Go中两个Nil可能不相等。
接口(interface) 是对非接口值(例如指针,struct等)的封装,内部实现包含 2 个字段,类型 T 和 值 V。一个接口等于 nil,当且仅当 T 和 V 处于 unset 状态(T=nil,V is unset)。
两个接口值比较时,会先比较 T,再比较 V。 接口值与非接口值比较时,会先将非接口值尝试转换为接口值,再比较。
func main() {
var p *int = nil
var i interface{} = p
fmt.Println(i == p) // true
fmt.Println(p == nil) // true
fmt.Println(i == nil) // false
}
2
3
4
5
6
7
这个例子中,将一个nil非接口值p赋值给接口i,此时,i的内部字段为(T=*int, V=nil),i与p作比较时,将 p 转换为接口后再比较,因此 i == p,p 与 nil 比较,直接比较值,所以 p == nil。
但是当 i 与nil比较时,会将nil转换为接口(T=nil, V=nil),与i(T=*int, V=nil)不相等,因此 i != nil。因此 V 为 nil ,但 T 不为 nil 的接口不等于 nil。
45.Goroutine和KernelThread之间是什么关系?
首先我们先看下进程和线程还有协程之间的区别:
- 进程
计算机的操作系统模式是一种多任务系统,操作系统接管了所有的硬件资源,并且本身运行在一个受硬件保护的级别。所有的应用程序都以进程(process)的方式运行在比操作系统权限更低的级别,每个进程都有自己独立的地址空间,使得进程之间的地址空间相互隔离。CPU由操作系统一进行分配,每个进程根据进程的优先级的高低都有机会得到CPU,但是如果允许时间超出了一定的时间,操作系统会暂停该进程,将CPU资源分配给其他等待的进程。这种CPU的分配方式即所谓的抢占式,操作系统可以强制剥夺CPU资源并且分配给它认为目前最需要的进程。如果操作系统分配给每个进程的时间都很短,即CPU在多个进程间快速地切换,从而造成了很多进程都在同时运行的假象。
- 线程
线程有时被称为轻量级进程(Lightweight Process),是程序执行流的最小单元,一个标准的线程由线程ID,当前指令指针(PC)、寄存器集合和堆栈组成,通常意义上,一个进程🈶一个到多个线程组成,各个线程之间共享程序的内存空间(包括代码段、数据段、堆等)及一些进程级的资源(如打开文件和信号)。
- 协程
协程(coroutine)是Go语言中的轻量级线程实现,由Go运行时(runtime)管理。
进程、线程、协程的关系和区别:
-
进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
-
线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的)。
-
协程和线程一样共享堆,不共享栈,协程由程序开发者在协程的代码里显示调度。
为什么协程比线程轻量?
a. go协程调用跟切换比线程效率高
线程并发执行流程: 线程是内核对外提供的服务,应用程序可以通过系统调用让内核启动线程,由内核来负责线程调度和切换。线程在等待IO操作时线程变为unrunnable状态会触发上下文切换。现代操作系统一般都采用抢占式调度,上下文切换一般发生在时钟中断和系统调用返回前,调度器计算当前线程的时间片,如果需要切换就从运行队列中选出一个目标线程,保存当前线程的环境,并且恢复目标线程的运行环境,最典型的就是切换ESP指向目标线程内核堆栈,将EIP指向目标线程上次被调度出时的指令地址。
go协程并发执行流程:不依赖操作系统和其提供的线程,golang自己实现的CSP并发模型实现:M, P, G .go协程也叫用户态线程,协程之间的切换发生在用户态。在用户态没有时钟中断,系统调用等机制,因此效率高
b. go协程占用内存少
执行go协程只需要极少的栈内存(大概是4~5KB),默认情况下,线程栈的大小为1MB。goroutine就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈。所以它非常廉价,我们可以很轻松的创建上万个goroutine,但它们并不是被操作系统所调度执行。
因此协程和线程一样共享堆,不共享栈,协程由用户态下面的轻量级线程。
CAS算法(Compare And Swap),是原子操作的一种, CAS算法是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。
该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
Go中的CAS操作是借用了CPU提供的原子性指令来实现。CAS操作修改共享变量时候不需要对共享变量加锁,而是通过类似乐观锁的方式进行检查,本质还是不断的占用CPU 资源换取加锁带来的开销(比如上下文切换开销)。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var (
counter int32 //计数器
wg sync.WaitGroup //信号量
)
func main() {
threadNum := 5
wg.Add(threadNum)
for i := 0; i < threadNum; i++ {
go incCounter(i)
}
wg.Wait()
}
func incCounter(index int) {
defer wg.Done()
spinNum := 0
for {
// 原子操作
old := counter
ok := atomic.CompareAndSwapInt32(&counter, old, old+1)
if ok {
break
} else {
spinNum++
}
}
fmt.Printf("thread,%d,spinnum,%d\n", index, spinNum)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
当主函数main首先创建了5个信号量,然后开启五个线程执行incCounter方法,incCounter内部执行, 使用cas操作递增counter的值,atomic.CompareAndSwapInt32具有三个参数,第一个是变量的地址,第二个是变量当前值,第三个是要修改变量为多少,该函数如果发现传递的old值等于当前变量的值,则使用第三个变量替换变量的值并返回true,否则返回false。
这里之所以使用无限循环是因为在高并发下每个线程执行CAS并不是每次都成功,失败了的线程需要重写获取变量当前的值,然后重新执行CAS操作。读者可以把线程数改为10000或者更多就会发现输出thread,5329,spinnum,1 其中这个1就说明该线程尝试了两个CAS操作,第二次才成功。
因此呢, go中CAS操作可以有效的减少使用锁所带来的开销,但是需要注意在高并发下这是使用cpu资源做交换的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号