note6
1、Make 和 new 区别
make和new都是内存的分配(堆上),但是make只用于slice、map以及channel的初始化(非零值);而new用于类型的内存分配,并且内存置为零。make返回的是引用类型本身;而new返回的是指向类型的指针。
2、切片和数组关系 引用类型和值类型 共享 扩容
数组是值类型,复制和传参复制整个数组。因此改变副本得值不会改变自身的值
数组支持 “==“、”!=” 操作符,因为内存总是被初始化过的。
切片是一个引用类型,它的内部结构包含地址(底层数组的指针)、长度和容量。切片一般用于快速地操作一块数据集合
当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。
“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
3、go struct能不能比较
golang中数据类型
可比较:Integer,Floating-point,String,Boolean,Complex(复数型),Pointer,Channel,Interface,Array
不可比较:Slice,Map,Function
同一个struct的两个实例可比较也不可比较,当结构不包含不可直接比较成员变量时可直接比较,否则不可直接比较
可以比较,也不可以比较,可通过强制转换来比较,如果成员变量中含有不可比较成员变量,即使可以强制转换,也不可以比较
4、Go defer for defer
defer在匿名返回值和命名返回值函数中的不同表现
在for循环中使用defer可能导致的性能问题
调用os.Exit时defer不会被执行
5、Client 如何实现长链接
for 循环不断读取 server端返回的response
6、主协程如何等其余协程完再操作
channel通信(主协程阻塞等待数据,每当一个子协程执行完后,就会往 ch 里面写一个数据,主协程收到后会使 count–,当 count 减为 0,关闭 ch,主协程将不阻塞在 range ch)、sync.WaitGroup
7、Content 包用途
Context通常被译作上下文,它是一个比较抽象的概念,其本质,是【上下上下】存在上下层的传递,上会把内容传递给下。在Go语言中,程序单元也就指的是Goroutine
8、Channel 注意事项
已关闭的通道:
对一个关闭的通道再发送值就会导致panic。
对一个关闭的通道进行接收会一直获取值直到通道为空。
对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
关闭一个已经关闭的通道会导致panic。
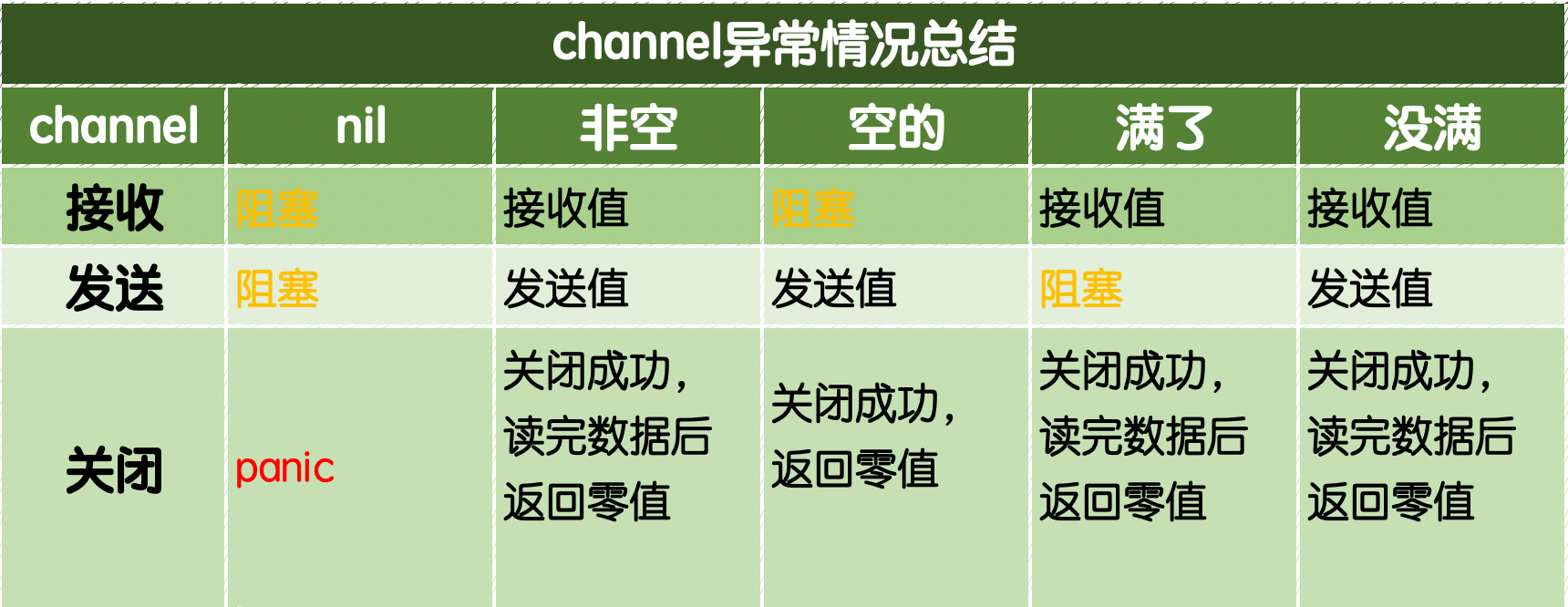
使用_,ok 判断 channel 是否关闭
更多 https://www.dazhuanlan.com/kaierlong/topics/1556135
7、Select 可以用于什么
无阻塞获取值
select-default
func (w *wantConn) waiting() bool { select { case <-w.ready: return false default: return true } }
超时控制
select-timer 例如等待tcp节点发送连接包,超时后则关闭连接
func (n *node) waitForConnectPkt() { select { case <-n.connected: log.Println("接收到连接包") case <-time.After(time.Second * 5): log.Println("接收连接包超时") n.conn.Close() } }
类事件驱动循环
for-select模式,例如监控tcp节点心跳是否正常
func (n *node) heartbeatDetect() { for { select { case <-n.heartbeat: // 收到心跳信号则退出select等待下一次心跳 break case <-time.After(time.Second*3): // 心跳超时,关闭连接 n.conn.Close() return } } }
8、Map 线程安全问题
9、进程、线程、携程关系
进程
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
10、协程调度及调度时机
GMP
调度时机
会阻塞的系统调用,比如文件io,网络io;
time系列定时操作;
go func的时候, func执行完的时候;
管道读写阻塞的情况;
垃圾回收之后。
主动调用runtime.Gosched()
https://studygolang.com/articles/34362?fr=sidebar
11、GC垃圾回收
12、Redis 数据持久化怎么做
13、逃逸分析
14、map如何顺序读取
map不能顺序读取,是因为他是无序的,想要有序读取,首先的解决的问题就是,把key变为有序,所以可以把key放入切片,对切片进行排序,遍历切片,通过key取值
15、异常和错误处理
16、微服务 服务注册发现怎么做的 链路追踪什么的 etcd相关
https://blog.csdn.net/lfhlzh/article/details/106324568
17、容器技术Docker相关
docker就是创建容器的工具,docker包含容器,镜像,仓库。容器就是原始文件,镜像就是复制容器来的,仓库就是储存镜像的
容器和虚拟机
相同:
容器和虚拟机一样都对物理硬件资源进行共享
容器和虚拟机生命周期相似 :创建 运行 暂停 关闭等
都可以安装各种应用 redis nginx 等
创建后都会存储在宿主机上
不同点:
虚拟机是一个完整的操作系统,容器需要操作系统做支撑的,本质上是一系列进程的组合
容器不需要额外的资源来管理,虚拟机有额外的更多性能消耗
容器创建启动等都容易的多
docker 是什么
一个开源的容器引擎,基于LCK容器技术,使用golang语言开发
docker 可轻松为任何应用创建可轻量级的、可移植的、自给自足的容器
docker提供了在一个完全隔离的环境中打包和运行应用程序的能力,这个隔离的环境成为容器
由于容器的隔离性和安全性,因此可以在一个主机(也叫住宿)上同时运行多个相互隔离的容器,互不干扰。
为什么用docker
保证程序运行环境的一致性
降低配置开发环境和生产环境复杂度和成本
实现程序的快速部署和分发
还可以避免甩锅
CS 结构 client (终端命令行) 通过REST API 与serve端进行通信的接口 sever 守护进程等待客户端发送命令 执行
四大核心技术:
镜像、容器、数据卷、网络
终端命令发送到 docker-host主机(docker服务端) 执行命令:如(docker pull)拉取镜像
镜像:一个docker的可执行文件,它包含运行程序所需的所有代码、依赖库、环境变量和配置文件等
容器:镜像被运行起来的实例
数据卷:容器和宿主机之间、容器和容器之间共享存储方式,类似于虚拟机和主机之间的共享文件目录 (容器内数据直接映射到本地主机环境)
网络:外部或容器之间互相访问的网络方式,如HOST模式,bridge模式
数据卷容器
docker create -v 容器卷目录 --name name1 image_id
docker run -it --name name2 -volumes-from name1 image_id 两个容器共享数据卷
docker 数据备份
创建一个挂载数据卷容器的容器
挂载宿主机本地目录作为备份数据卷
将数据卷容器的内容备份到宿主机本地目录挂载的数据卷中
完成备份操作后销毁刚创建的容器
docker run --rm --volumes-from name1[数据卷容器name/ID] -v
/home/backup[宿主机目录] :/backup[容器目录] image[镜像名称]
后面是备份命令 tar -zcPF /backup/data.tar.gz /data
网络模式
bridge 同一主机下的容器都在一个网络下,彼此之间可以通过。利用宿主机网卡通信,因为涉及到网络转换所以会造成资源消耗,网络效率低
映射
桥接网络
host 容器与宿主机共享网络
none 最纯粹,可自由定制网络
container模式 使用以创建的容器网络 类似局域网 容器和容器共享网络
overlay 容器彼此不在同一网络,而且可以互相通行 (docker内部)
dockerfile
FROM golang:alpine
# 为我们的镜像设置必要的环境变量
ENV GO111MODULE=on \
CGO_ENABLED=0 \
GOOS=linux \
GOARCH=amd64
# 移动到工作目录:/build
WORKDIR /build
# 将代码复制到容器中
COPY . .
# 将我们的代码编译成二进制可执行文件app
RUN go build -o app .
# 移动到用于存放生成的二进制文件的 /dist 目录
WORKDIR /dist
# 将二进制文件从 /build 目录复制到这里
RUN cp /build/app .
# 声明服务端口
EXPOSE 8888
# 启动容器时运行的命令
18、K8s相关
k8s 基于容器的集群管理平台(K8S是用来管理容器的)
一个K8S系统,通常称为一个K8S集群(Cluster)。
这个集群主要包括两个部分:一个Master节点,一群Node。
Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器
pod包含各个功能的容器,pod在node运行,master管理node。
Master节点包括API Server、Scheduler、Controller manager、etcd。
API Server是整个系统的对外接口,供客户端和其它组件调用,相当于“营业厅”。
Scheduler负责对集群内部的资源进行调度,相当于“调度室”。
Controller manager负责管理控制器,相当于“大总管”。
Node 是 k8s 的工作节点,Node 一般是一个虚拟机或者物理机,每个 node 上都运行三个服务:docker、kubelet、 kube-proxy
docker 就是创建容器的
kubelet 是一个管理系统,它管理本个node上的容器的生命周期,监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等
kube-proxy 是管理 service 的访问入口,即:要负责为Pod对象提供代理
--
master 主要工作:调度应用程序、维护应用程序的所需状态,扩展应用程序和滚动更新(先运行新容器2.0,所有请求都交到新容器,在关闭旧容器1.0)
node 主要 运行容器应用 负责监听并汇报容器的状态,同时根据master的要求管理容器的生命周期。
每个node都有kubelet(管理节点并与master进行通信的代理)
pob(资源对象) k8s的最小工作单元 每个pod可能包含多个容器 这些容器使用同一个网络namespace(即:相同的ip和port空间,可直接用localhost通信)
这些容器也可以共享存储 k8s挂载 volume到pod 就是将volume挂载到pob 中的每个容器。
controller(Deployment、ReplicaSet.....Job 多种controller) 管理pob的多个副本并确保pob按期望的状态运行,一般是Deployment
service 定义了外界访问一组特定pob的方式 有自己的ip和端口 ,service为pob提供了负载均衡
k8s运行容器(pob)和访问容器(pob) 这两项任务分别由 controller 和 service 执行
Namespace 多个用户或者项目使用同一个k8s ,即:可以将物理的集群(Cluster)逻辑上划分为多个虚拟的Cluster,可以将controller pod 等创建的资源划分开
默认有两个 default (创建资源时不指定namespace 将被放到这个namespace)、kube-system(k8s自己创建的系统资源放在此namespace)
k8s流程
1、准备好对应的yanl文件,通过kubectl发送到Api Server中
2、Api Server接收到客户端的请求将请求内容保存到etcd中
3、Scheduler会监测etcd,发现没有分配节点的pod对象通过过滤和打分筛选出最适合的节点运行pod
4、节点会通过conteiner runntime 运行对应pod的容器以及创建对应的副本数
5、节点上的kubelet会对自己节点上的容器进行管理
6、controler会监测集群中的每个节点,发现期望状态和实际状态不符合的话,就会通知对应的节点
7、节点收到通知,会通过container runtime来对pod内的容器进行收缩或者扩张
对于容器来说,管理的单位是容器
对于k8s来说,管理的是一个pod应用
一个pod上可以运行多个容器,可以将pod理解为一个虚拟机,一个虚拟机上运行了多个容器
19、http 40X 状态码 分别什么问题
400 无法解析此请求,请求参数或语义有误
401 请求未经授权 授权认证没通过
403 请求被拒绝
404 请求资源未发现或找不到了
405 method not allow 请求中请求方法不能被用来请求指定资源
20、Linux 常用命令 如端口占用 cpu负载 内存占用
端口占用:netstat -anp |grep 端口号
cpu负载:
top 命令第三行 VS vmstat
%us:表示用户空间程序的cpu使用率(没有通过nice调度)
%sy:表示系统空间的cpu使用率,主要是内核程序。
%ni:表示用户空间且通过nice调度过的程序的cpu使用率。
%id:空闲cpu
%wa:cpu运行时在等待io的时间
%hi:cpu处理硬中断的数量
%si:cpu处理软中断的数量
%st:被虚拟机偷走的cpu
内存占用
top 命令第四行
第四行:内存状态
总量:1020000k
已使用:144964k
空闲量:875036k
缓存的内存量:12456k
进程情况 PS
21、实现set
22、实现消息队列(多生产者,多消费者)
channel 实现
struct 实现 使用select 及互斥锁
type Product struct{ mutex sync.Mutex product chan int closeChan chan bool isClosed bool }
https://blog.csdn.net/weixin_38707040/article/details/95224277
23、大文件排序
24、基本排序,哪些是稳定的
25、http get跟head
26、http keep-alive
27、http能不能一次连接多次请求,不等后端返回
28、tcp与udp区别,udp优点,适用场景
TCP与UDP的区别。
TCP:面向连接,可靠的,速度慢,效率低。
UDP:无连接、不可靠、速度快、效率高
TCP应用场景:
效率要求相对低,但对准确性要求相对高的场景。因为传输中需要对数据确认、重发、排序等操作,相比之下效率没有UDP高。举几个例子:文件传输(准确高要求高、但是速度可以相对慢)、接受邮件、远程登录。
UDP应用场景:
效率要求相对高,对准确性要求相对低的场景。举几个例子:QQ聊天、在线视频、网络语音电话(即时通讯,速度要求高,但是出现偶尔断续不是太大问题,并且此处完全不可以使用重发机制)、广播通信(广播、多播)
TCP三次握手
所谓三次握手,是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。
三次握手的目的是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号并交换 TCP 窗口大小信息.在socket编程中,客户端执行connect()时。将触发三次握手。
(1) 第一次握手:建立连接时,客户端A发送SYN包(SYN=j)到服务器B,并进入SYN_SEND状态,等待服务器B确认。
(2) 第二次握手:服务器B收到SYN包,必须确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器B进入SYN_RECV状态。
(3) 第三次握手:客户端A收到服务器B的SYN+ACK包,向服务器B发送确认包ACK(ACK=k+1),此包发送完毕,客户端A和服务器B进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据。
TCP 四次挥手
TCP的连接的拆除需要发送四个包,因此称为四次挥手。客户端或服务器均可主动发起挥手动作,在socket编程中,任何一方执行close()操作即可产生挥手操作。
TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个
FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1)TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送。
(2)服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
(3)服务器关闭客户端的连接,发送一个FIN给客户端。
(4)客户端发回ACK报文确认,并将确认序号设置为收到序号加1
29、time-wait的作用
a、为了保证客户端发送的最后一个ack报文段能够到达服务器,因为这最后一个ack确认包可能会丢失,然后服务器就会超时重传第三次挥手的fin信息报,然后客户端再重传一次第四次挥手的ack报文。如果没有这2msl,客户端发送完最后一个ack数据报后直接关闭连接,那么就接收不到服务器超时重传的fin信息报(此处应该是客户端收到一个非法的报文段,而返回一个RST的数据报,表明拒绝此次通信,然后双方就产生异常,而不是收不到。),那么服务器就不能按正常步骤进入close状态。那么就会耗费服务器的资源。当网络中存在大量的timewait状态,那么服务器的压力可想而知。
b、在第四次挥手后,经过2msl的时间足以让本次连接产生的所有报文段都从网络中消失,防止下次连接出问题
30、孤儿进程,僵尸进程
31、数据库如何建索引
32、mysql索引为什么要用B+树
33、raft算法是那种一致性算法
共识算法 分布式一致性算法
34、raft有什么特点
与Paxos相比,Raft强调的是易理解、易实现,Raft和Paxos一样只要保证超过半数的节点正常就能够提供服务。
众所周知,当问题较为复杂时,可以把问题分解为几个小问题来处理,Raft也使用了分而治之的思想,把算法分为三个子问题:
- 选举(Leader election)
- 日志复制(Log replication)
- 安全性(Safety)
分解后,整个raft算法变得易理解、易论证、易实现
35、怎么做服务发现的,服务发现有哪些机制
36、锁 :死锁条件 如何避免

 浙公网安备 33010602011771号
浙公网安备 33010602011771号