kNN模型(Python3.x环境)
本文为《机器学习实战》第二章的实操,由于原文采用的是Python2.x环境,另外局部地方也并没有完全给出代码,因此本文对此稍作修正。
另外,本文采用的数据集是datingTestSet2.txt不是datingTestSet.txt。因为datingTestSet2.txt中分类结果是以数字为分类结果的,后期便于处理。
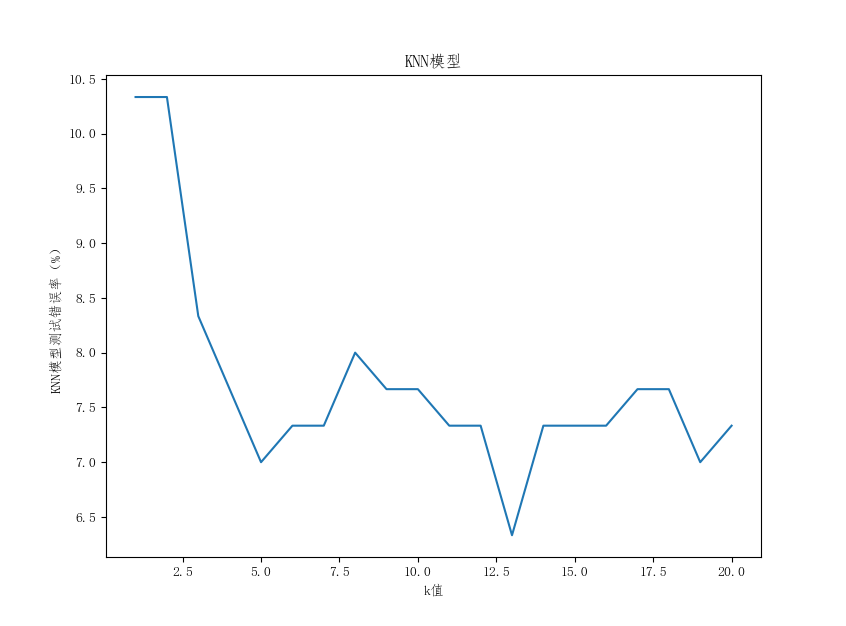
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Leslie Dang from numpy import * import matplotlib import matplotlib.pyplot as plt from pylab import mpl mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 def classify0(inX,dataSet,labels,k): # inX为预测样本,dataSet为训练样本,labels为训练样本标签,k为最近邻的数目。 dataSetSize = dataSet.shape[0] # 训练样本行数 # 距离计算 diffMat = tile(inX,(dataSetSize,1)) - dataSet # tile(A,(a,b))功能是将数组A重复(a行b列)次,构成一个新的数组 sqDiffMat = diffMat**2 sqDistances = sqDiffMat.sum(axis=1) # sum(axis=1)表示延矩阵水平方向求和 distances=sqDistances**0.5 # 获取距离排序后的索引排序 sortedDistIndicies = distances.argsort() # 获取前K个样本的label频次统计结果,将汇总结果放在classCount字典中。 classCount = {} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] # 通过索引获取对应的标注 classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 # 字典dict.get(key, default=None)函数返回指定键的值,如果值不在字典中返回默认值。 # 对获得的字典进行排序 sortedClassCount = sorted(classCount.items(), key = lambda x:x[1],reverse=True) # iteritems()方法已经废除了。在3.x里用 items()替换iteritems() ,可以用于for来循环遍历。 return sortedClassCount[0][0] # 返回距离最近的前k个样本的label最多的类别名称 def file2matrix(filename): # 处理文本文件,没有表头的、包含标签的样本数据。 # 处理后,返回样本特征矩阵、样本标签列表 fileRead = open(filename) arrayOfLines = fileRead.readlines() numOfLines = len(arrayOfLines) returnMat = zeros((numOfLines,3)) classLabelVector = [] index = 0 for line in arrayOfLines: line = line.strip() listFromLine = line.split('\t') # print('listFromLine:',listFromLine) # 获取样本行特征 returnMat[index,:] = listFromLine[0:3] # 获取样本行标签 classLabelVector.append(listFromLine[-1]) index += 1 return returnMat,classLabelVector # returnMat为array格式,classLabelVector为list格式。 def autoNorm(dataSet): # 将一列数据处理成[0,1]的归一化值。 # 返回归一化数组、极差值、最小值。 minVals = dataSet.min(0) # 参数0可以使函数从列中选取最小值,而不是选取当前行的最小值。 maxVals = dataSet.max(0) ranges = maxVals-minVals normSet = zeros(shape(dataSet)) rows = dataSet.shape[0] # 所有样本值减去最小值 normSet = dataSet - tile(minVals,(rows,1)) # 再除以样本的区间值,实现归一化。 normSet = normSet/tile(ranges,(rows,1)) return normSet ,ranges ,minVals def datingClass(fileName,k): # 函数名中不能加test字眼,不然pycharm调用不了这个函数。 # 测试代码 hoRatio = 0.30 returnMat,classLebel = file2matrix(fileName) normMat,ranges,minVals = autoNorm(returnMat) m = normMat.shape[0] numTestVecs = int(m*hoRatio) print('测试集样本数:',numTestVecs) errorCount = 0.0 for i in range(numTestVecs): classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],classLebel[numTestVecs:m],k) print('The classifier came back with: %d,the real answer is: %d' % (int(classifierResult), int(classLebel[i]))) if (int(classifierResult) != int(classLebel[i])): errorCount += 1.0 print('The total error rate is: %f'%(errorCount/float(numTestVecs))) return errorCount/float(numTestVecs) if __name__ == '__main__': fileName = 'datingTestSet2.txt' k = [] errorRate = [] for i in range(1,21): k.append(i) errorRate.append(datingClass(fileName,i)*100) fig = plt.figure() ax = fig.add_subplot(111) ax.plot(k, errorRate) plt.xlabel('k值') plt.ylabel('KNN模型测试错误率(%)') plt.title('KNN模型') plt.show()
跑出来的结果如下: