dataframe 多字段排序
需求:
import pandas as pd
df = pd.DataFrame(
{'gene': ['BC061237', 'Gm19965', 'Afdvwef', 'Vafsx', '4930599A14Rik', 'am45766'],
'mid': [2, 2, 5, 7, 2, 2],
'count': [3, 6, 2, 7, 3, 3]})
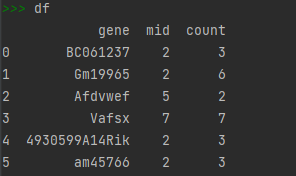
对于上边这个dataframe,先按字段mid顺序排序,如果mid值相同,再用gene字段按ascii值不区分字母大小写顺序排序。
解决方案
方案一(会区分大小写,不适用):
df.sort_values(by=['mid', 'gene'])
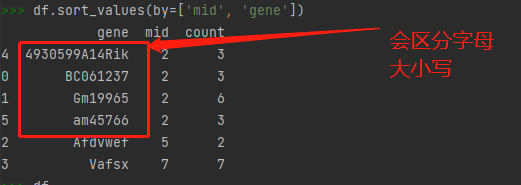
方案二 (大量数据时,并不会根据gene字段排序)
df.sort_values('gene', key=lambda x: x.str.lower()).sort_values('mid')
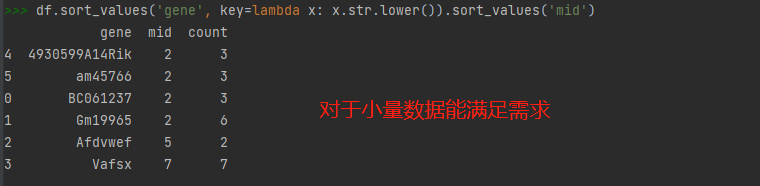
用真实数据做如下测试,发现不满足需求
方案三 (满足需求)
对于方案一,唯一的问题是会区分字母小大写,所以多方案一进行优化,做如下改动
df.sort_values(by=['mid', 'gene'], key=lambda x: x.str.lower())
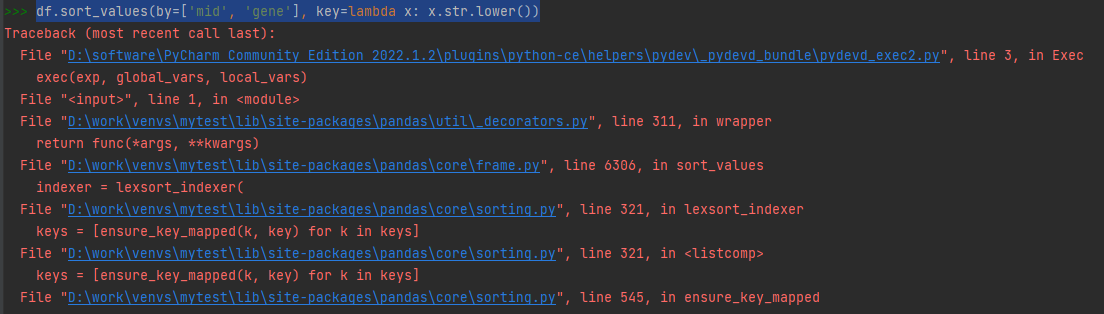
直接这样执行会出错,分析原因:
- 是因为gene是字符串类型,调用.str.lower()是没问题,但是mid是数值类型,调用.str.lower()会有问题

解决异常:
- 我们只对字符串类型的做大小写准换,对数值类型不处理。
def str2lower(sr):
try:
return sr.str.lower()
except:
return sr
修改上边的代码
df.sort_values(by=['mid', 'gene'], key=str2lower)
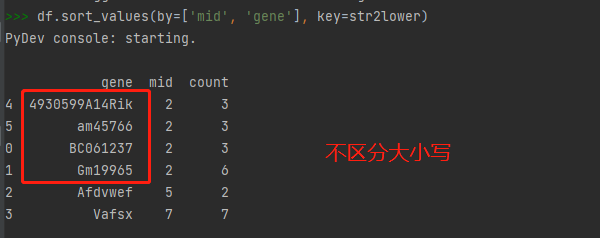
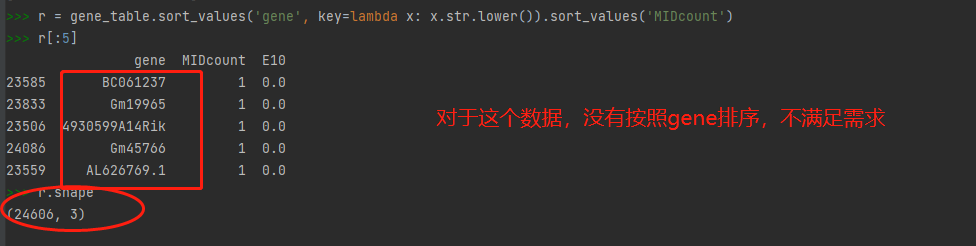
在真实数据测试
r = gene_table.sort_values(by=['MIDcount', 'gene'], key=str2lower)
r[:5]
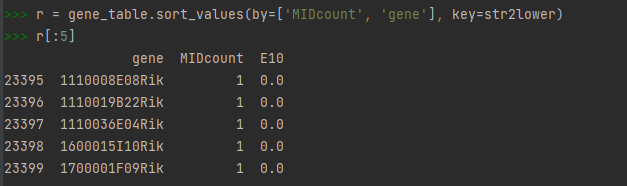
先按MIDcount的值顺序排序,再根据gene的值不区分字母大小写顺序数据,满足需求。(在这里看到的gene值全都是数字开头是因为数据太大,只输出了前5个元素)
