
python接口自动化4-绕过验证码登录(cookie)
原文链接:https://www.cnblogs.com/liunaixu/p/11077960.html
前言
有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。
获取不到也没关系,可以通过添加cookie的方式绕过验证码。
一、抓登录cookie
1.登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开登录界面,手动输入账号和密码

4.打开fiddler抓包工具,刷新下登录首页,就是登录前的cookie了
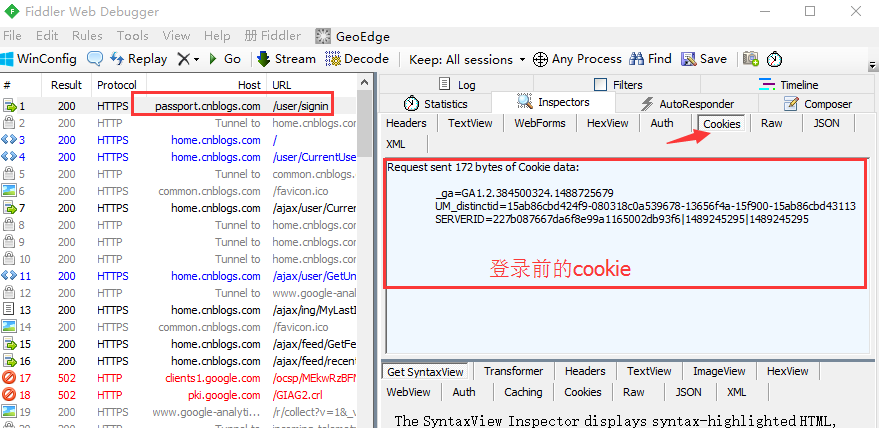
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
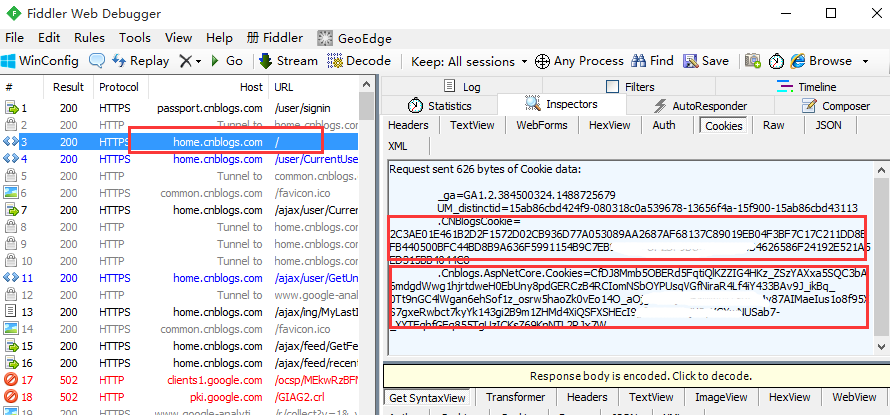
二、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数
2.以下是一个完整的cookie组成结构
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
三、添加cookie
1.往session里面添加cookie可以用以下方式
2.set里面参数按括号里面的参数格式
coo = requests.cookies.RequestsCookieJar()
coo.set('cookie-name', 'cookie-value', path='/', domain='.xxx.com')
s.cookies.update(coo)
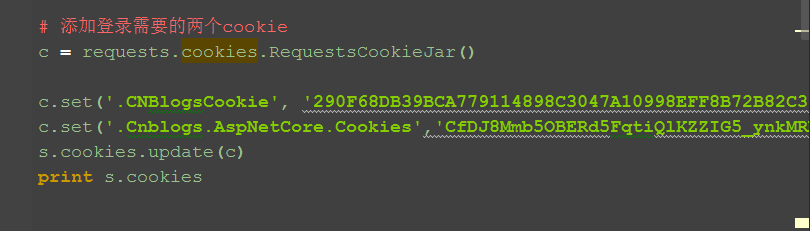
3.于是添加登录的cookie,把第一步fiddler抓到的内容填进去就可以了
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'xxx')
c.set('.Cnblogs.AspNetCore.Cookies','xxx')
s.cookies.update(c)
print(s.cookies)
四、参考代码
1.由于登录时候是多加2个cookie,我们可以先用get方法打开登录首页,获取部分cookie
2.再把登录需要的cookie添加到session里
3.添加成功后,随便编辑正文和标题保存到草稿箱
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
print s.cookies
# 添加登录需要的两个cookie
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', '这里是抓到的') # 填上面抓包内容
c.set('.Cnblogs.AspNetCore.Cookies','这里是抓到的') # 填上面抓包内容
s.cookies.update(c)
print s.cookies
# 登录成功后保存编辑内容
r1 = s.get("https://i.cnblogs.com/EditPosts.aspx?opt=1", headers=headers, verify=False)
# 保存草稿箱
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是3111",
"Editor$Edit$EditorBody":"<p>这里111:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$Advanced$txbEntryName":"",
"Editor$Edit$Advanced$txbExcerpt":"",
"Editor$Edit$Advanced$tbEnryPassword":"",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r.content

